yolov5源码中添加注意力机制
- 1 项目环境配置
- 1.1 yolov5 源码下载
- 1.2 创建虚拟环境
- 1.3 安装依赖
- 2 常用的注意力机制
- 2.1 SE 注意力机制
- 2.2 CBAM 注意力机制
- 2.3 ECA 注意力机制
- 2.4 CA 注意力机制
- 3 添加方式
- 3.1 修改 common.py 文件
- 3.2 修改 yolo.py 文件
- 3.3 修改 yolov5s.yaml 文件
- 3.4 修改 train.py 文件
1 项目环境配置
1.1 yolov5 源码下载
点击下载
1.2 创建虚拟环境
win+r打开Windows终端界面输入(其中yolov5为我命名的虚拟环境名称):
mkvirtualenv yolov5
进入虚拟环境
python">workon yolov5
没有此模块无法创建虚拟环境的请移步:Python 的虚拟环境
1.3 安装依赖
- 依赖前提:有python环境以及pytorch
本人环境:python3.9,cuda11.7
安装 pytorch 移步官网
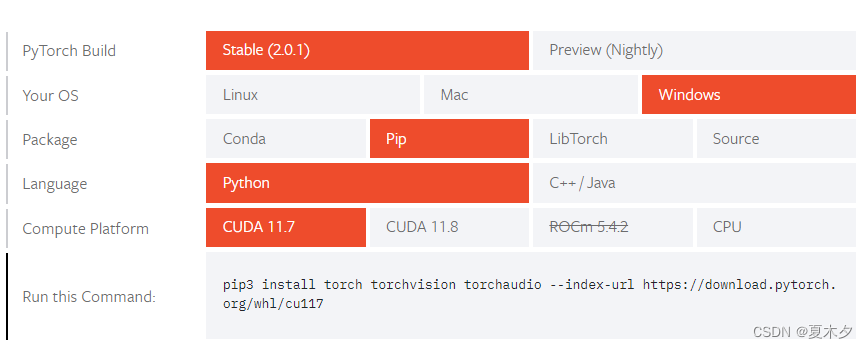
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
避免不必要的错误,建议使用 pip 安装
- 安装项目依赖
进入项目文件夹,终端键入:
pip install -r requirements.txt
环境搭建完成!
2 常用的注意力机制
2.1 SE 注意力机制
python"># SE
class SE(nn.Module):
def __init__(self, c1, c2, ratio=16):
super(SE, self).__init__()
#c*1*1
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // ratio, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
2.2 CBAM 注意力机制
python"># CBAM
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# (特征图的大小-算子的size+2*padding)/步长+1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1*h*w
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
#2*h*w
x = self.conv(x)
#1*h*w
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
# c*h*w
# c*h*w * 1*h*w
out = self.spatial_attention(out) * out
return out
2.3 ECA 注意力机制
python">class ECA(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, c1,c2, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
2.4 CA 注意力机制
python"># CA
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
#c*1*W
x_h = self.pool_h(x)
#c*H*1
#C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
#C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
3 添加方式
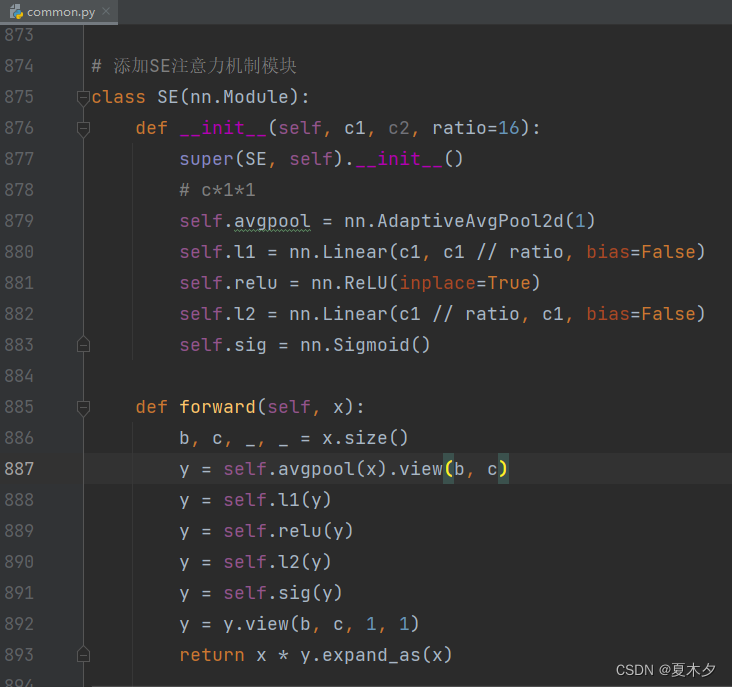
3.1 修改 common.py 文件
修改 yolov5-master/models/common.py文件,将上述提供的注意力机制代码块直接加到 common.py 文件夹的末尾,此处以SE注意力机制为例
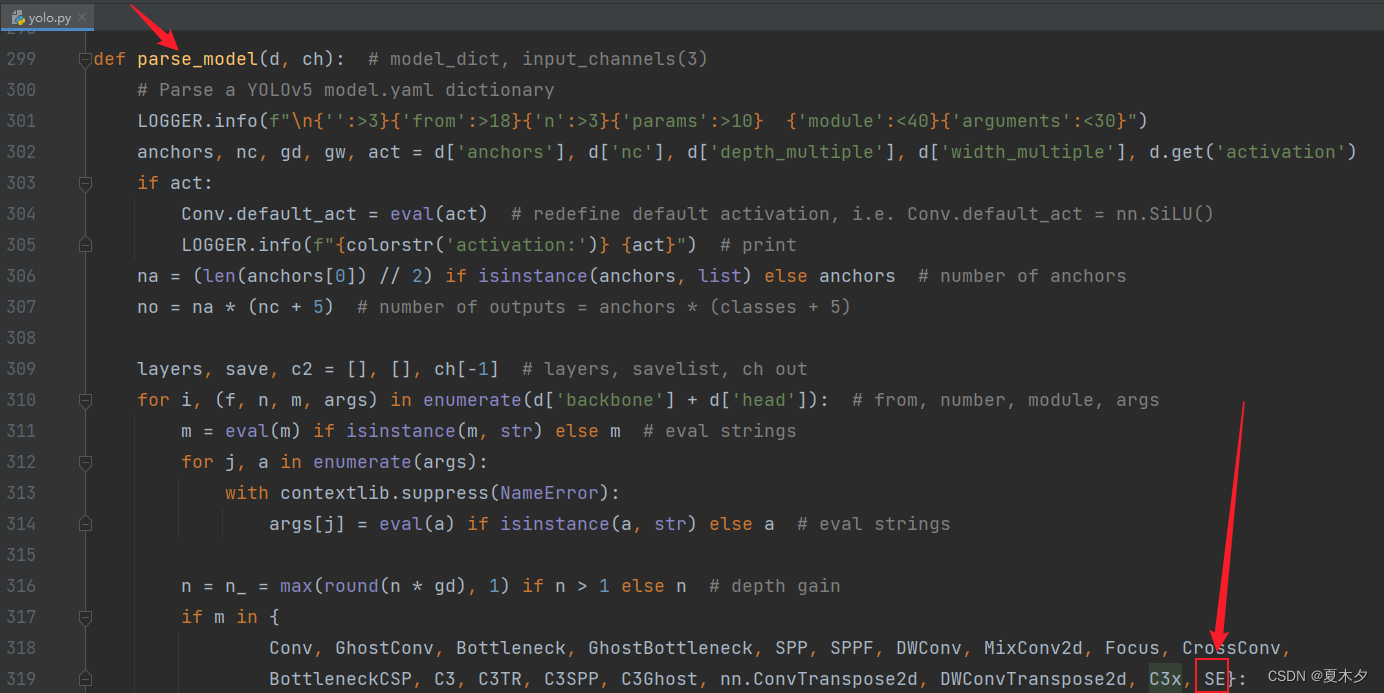
3.2 修改 yolo.py 文件
修改 yolov5-master/models/yolo.py文件,将注意力机制类名SE添加到 yolo.py 文件的 parse_model方法中如下集合里
3.3 修改 yolov5s.yaml 文件
修改 yolov5-master/models/yolov5s.yaml文件,将SE注意力机制模块添加到你想添加的位置,常见的有C3模块的后面,以及在主干网络 backbone 的 SPPF 的前一层,这里我将SE注意力机制模块添加在主干网络 backbone 的 SPPF 的前一层
修改前:
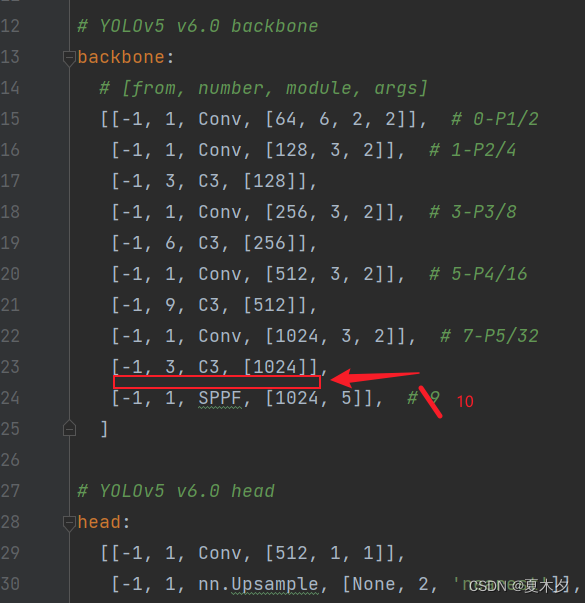
修改后:
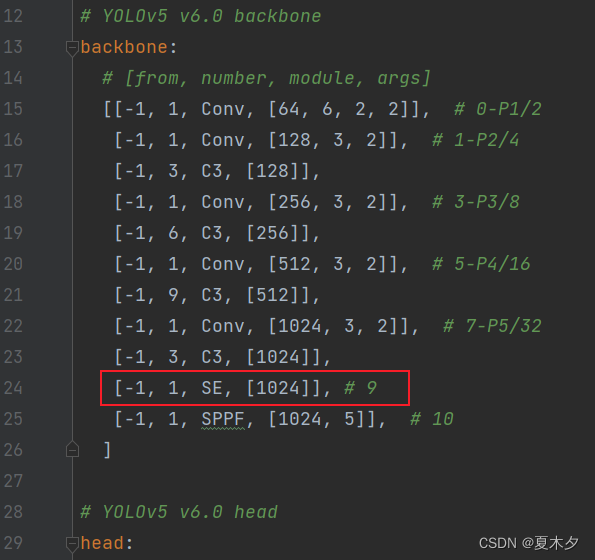
另外,由于我将SE注意力机制模块添加在了第 9 层(层索引为 9,起始层索引为 0),那么,原来的第 9 层,以及第 9 层之后的层数都要加 1
加1前:
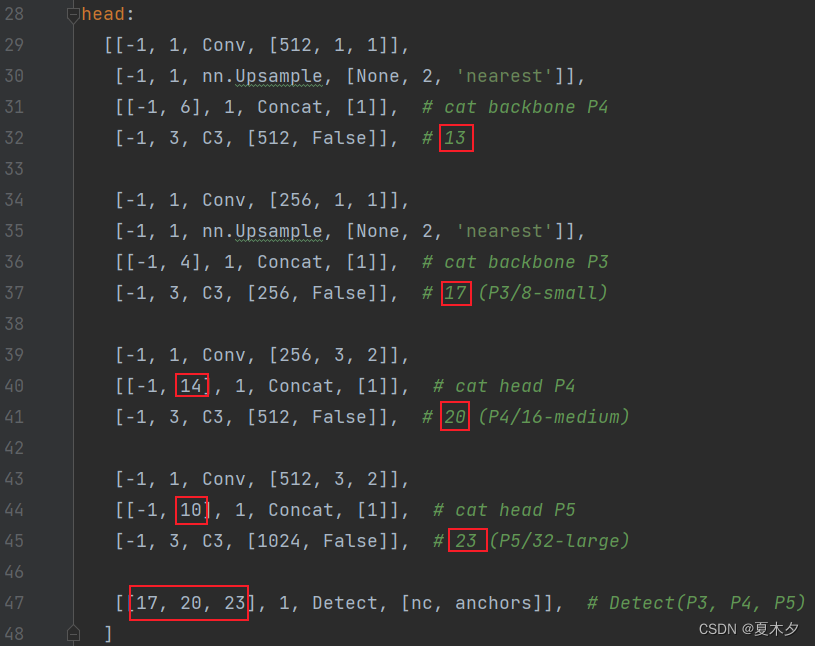
加1后:
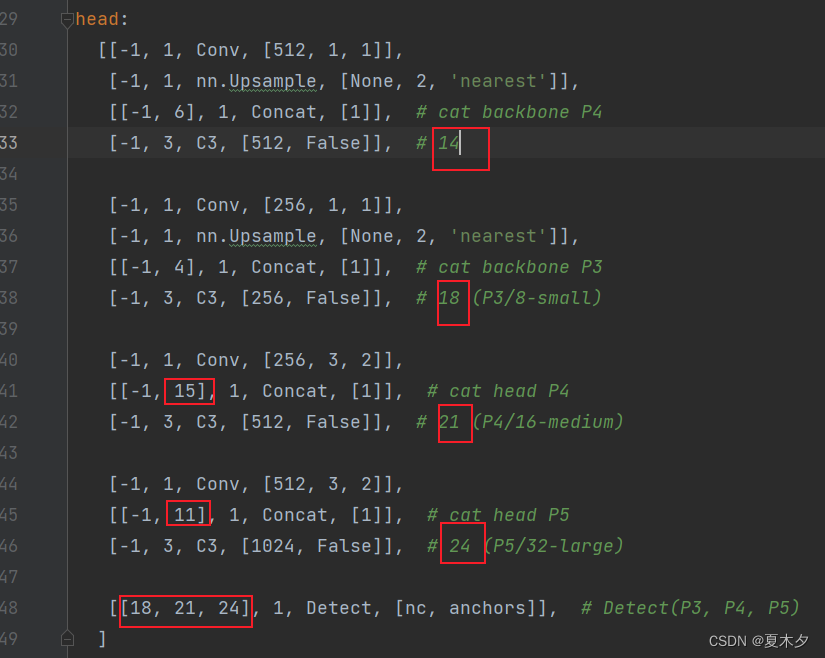
3.4 修改 train.py 文件
修改 yolov5-master/train.py 文件,在默认参数 --cfg后面的 default中添加我们前面修改过的 yolov5s.yaml文件
修改前:

修改后: