闭包
星辰处理器
python副业
汽车
论文阅读
web
性能优化
Table API
激活函数
kmeans
业务大屏
web前端
OData
salesforce
koa
换源
创业项目
codeblock
延迟
工业互联网
注意力机制
2024/4/12 2:10:15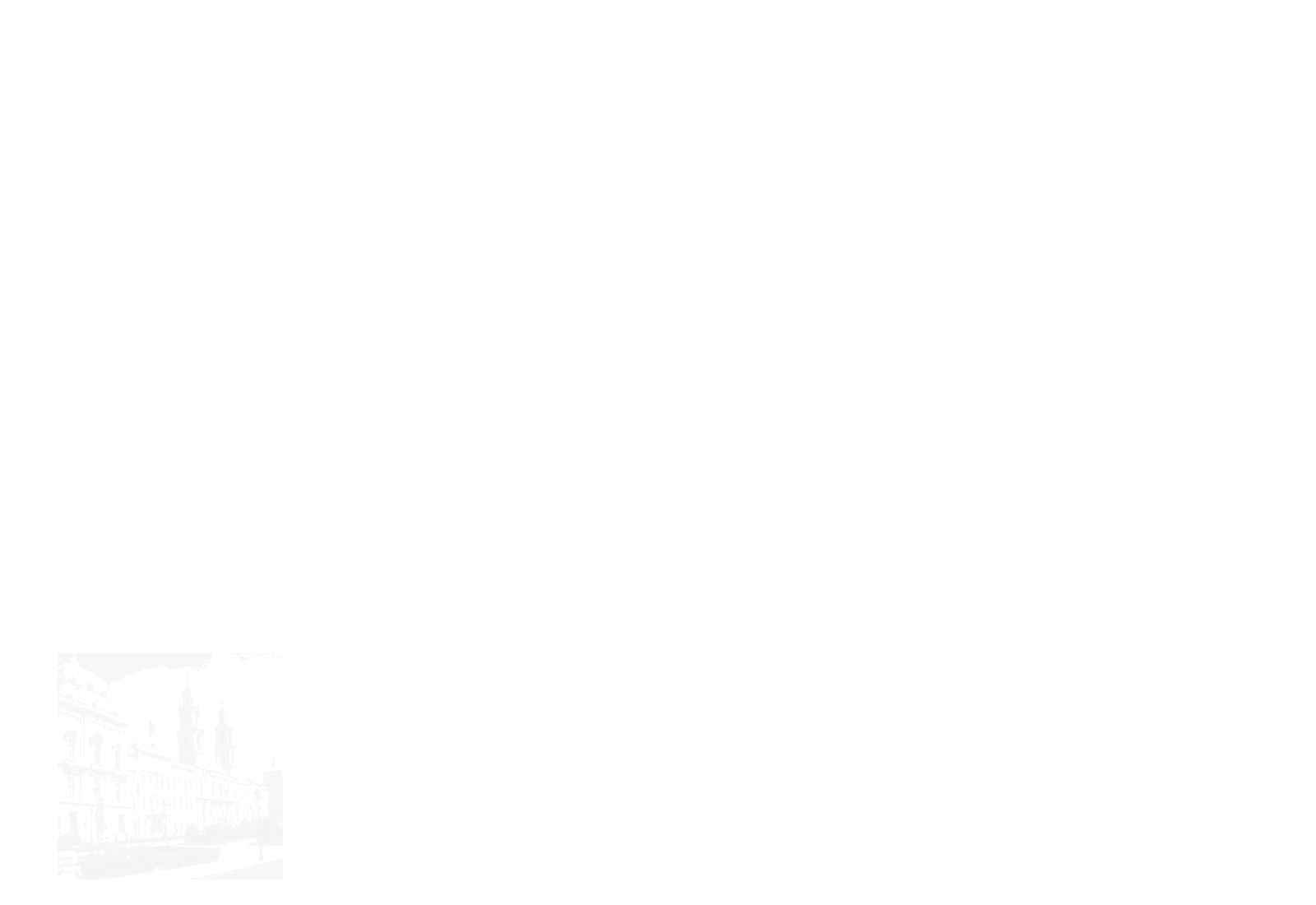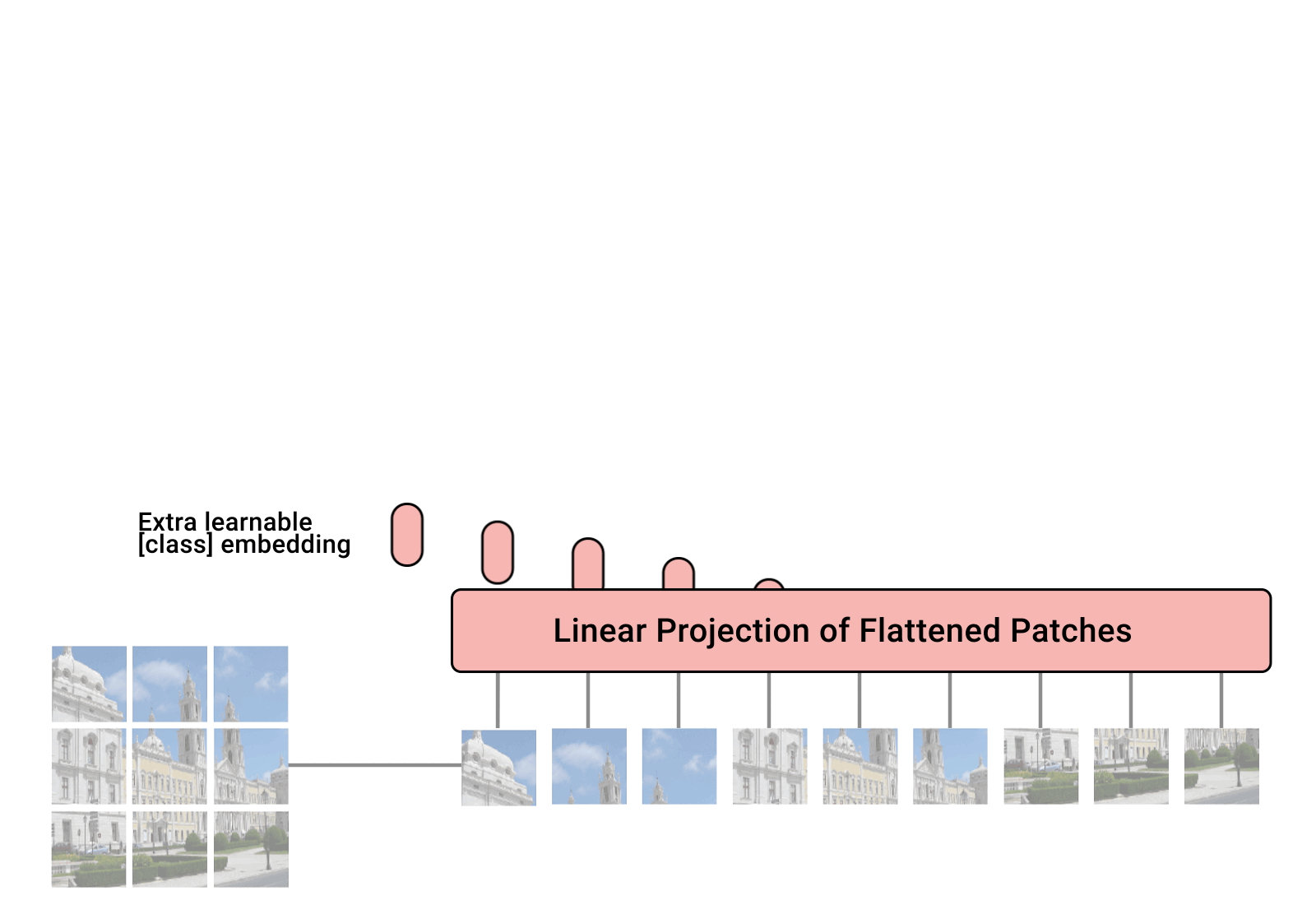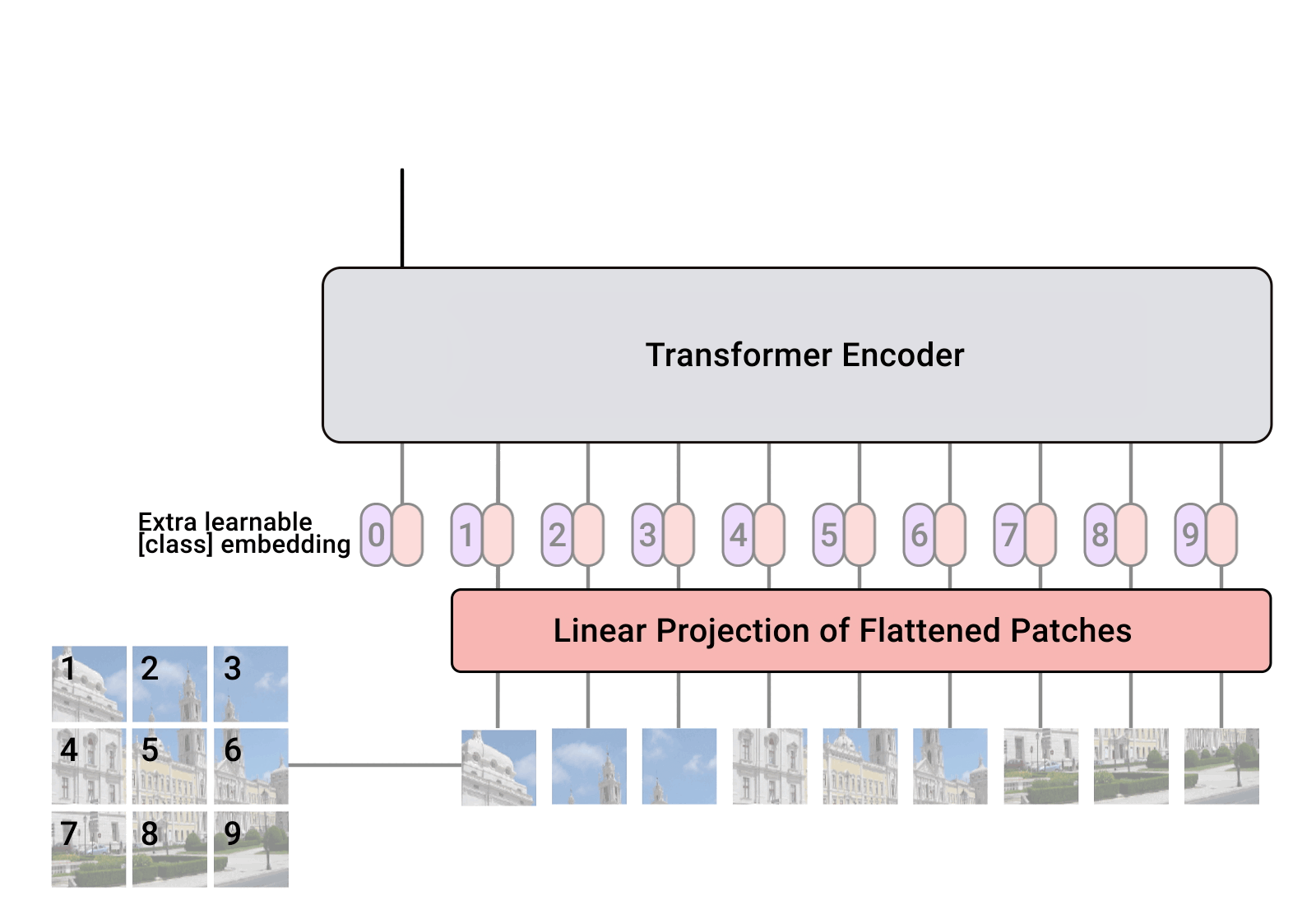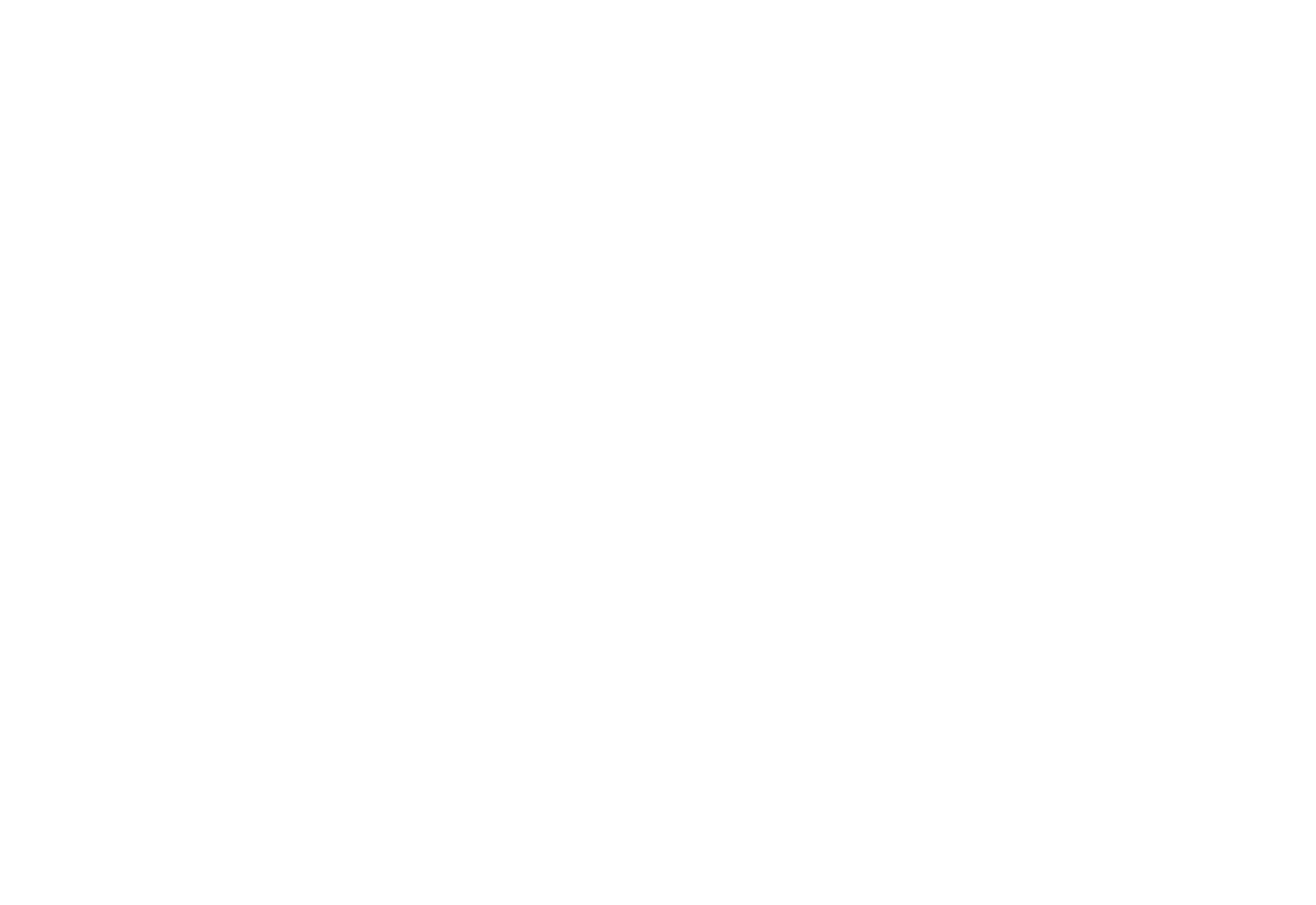
机器学习笔记 - 在 Vision Transformer 中可视化注意力
2022 年,视觉变换器(ViT) 成为卷积神经网络(CNN) 的有力竞争对手,后者现已成为计算机视觉领域的最先进技术,并广泛应用于许多图像识别应用中。在计算效率和准确性方面,ViT 模型超过了当前最先进的 (CNN) 几乎四倍。
一、视觉转换器 (ViT) 如何工作? 视觉转换器模型的性能…
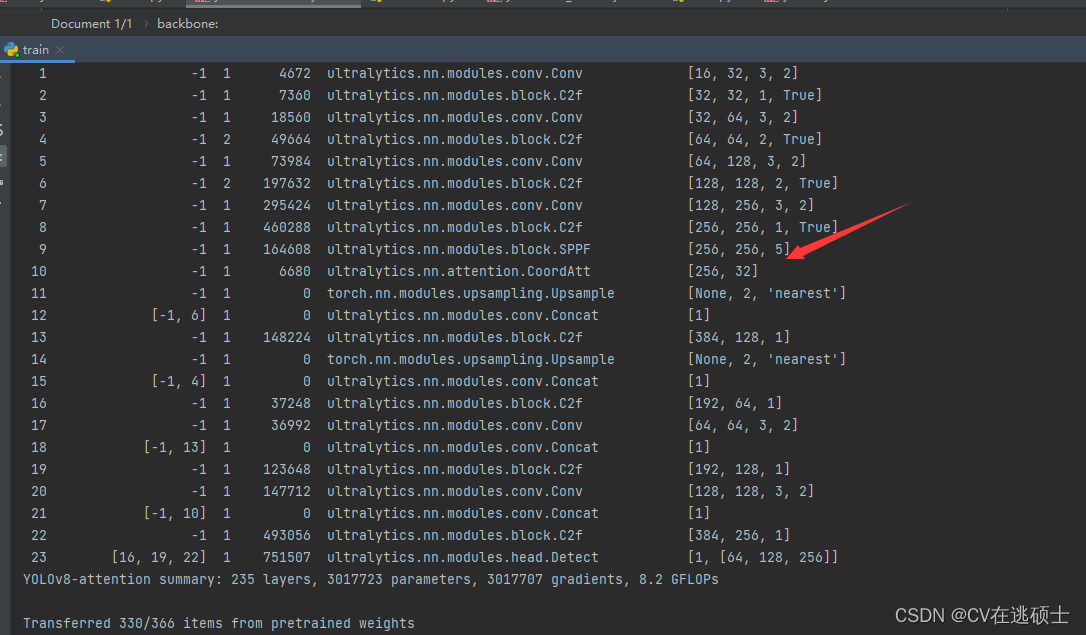
YOLOv8创新魔改教程(二)如何添加注意力机制
YOLOv8创新魔改教程(二)如何添加注意力机制
(一)找代码
github找各种注意力机制的代码
(二)融合
1.创建文件
在ultralytics/nn/attention.py创建attention.py 文件 将找到的代码粘贴进来
2.修改task…

SCI一区 | Matlab实现BES-TCN-BiGRU-Attention秃鹰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现BES-TCN-BiGRU-Attention秃鹰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现BES-TCN-BiGRU-Attention秃鹰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述程序…
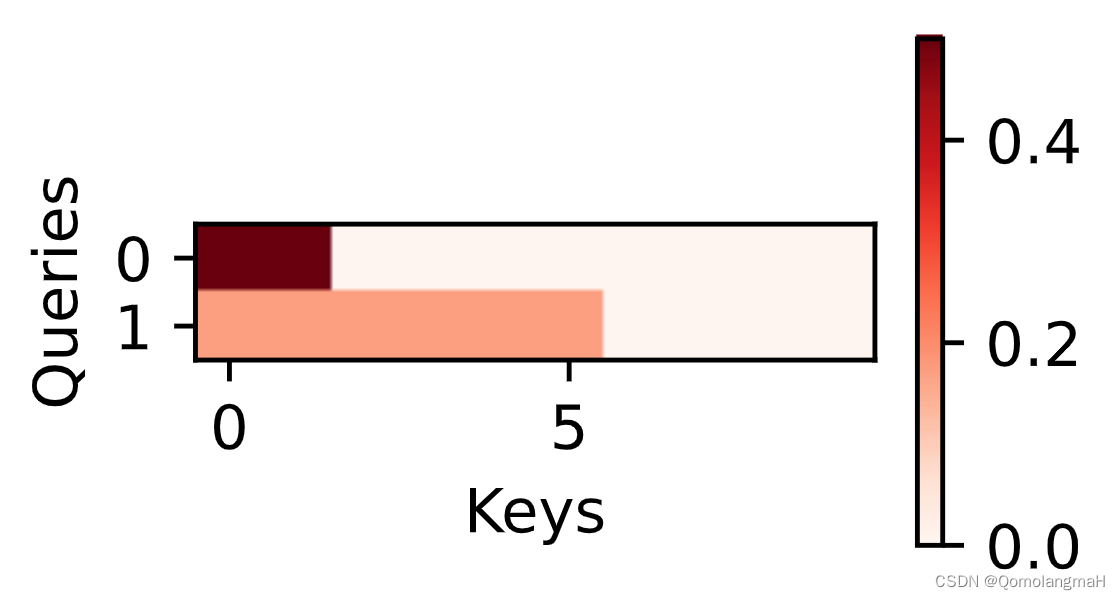
【深度学习实验】注意力机制(三):打分函数——加性注意力模型
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 理论介绍a. 认知神经学中的注意力b. 注意力机制 1. 注意力权重矩阵可视化(矩阵热图)2. 掩码Softmax 操作3. 打分函数——加性注意力模型1. 初始化2. 前向传播3. 内部组件…

回归预测 | Matlab实现SSA-BiLSTM-Attention麻雀算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测
回归预测 | Matlab实现SSA-BiLSTM-Attention麻雀算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测 目录 回归预测 | Matlab实现SSA-BiLSTM-Attention麻雀算法优化双向长短期记忆神经网络融合注意力机制多变量回归预测预测效果基本描述程序设计参考资料 预测效果 基…

YOLOv5改进系列(7)——添加SimAM注意力机制
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
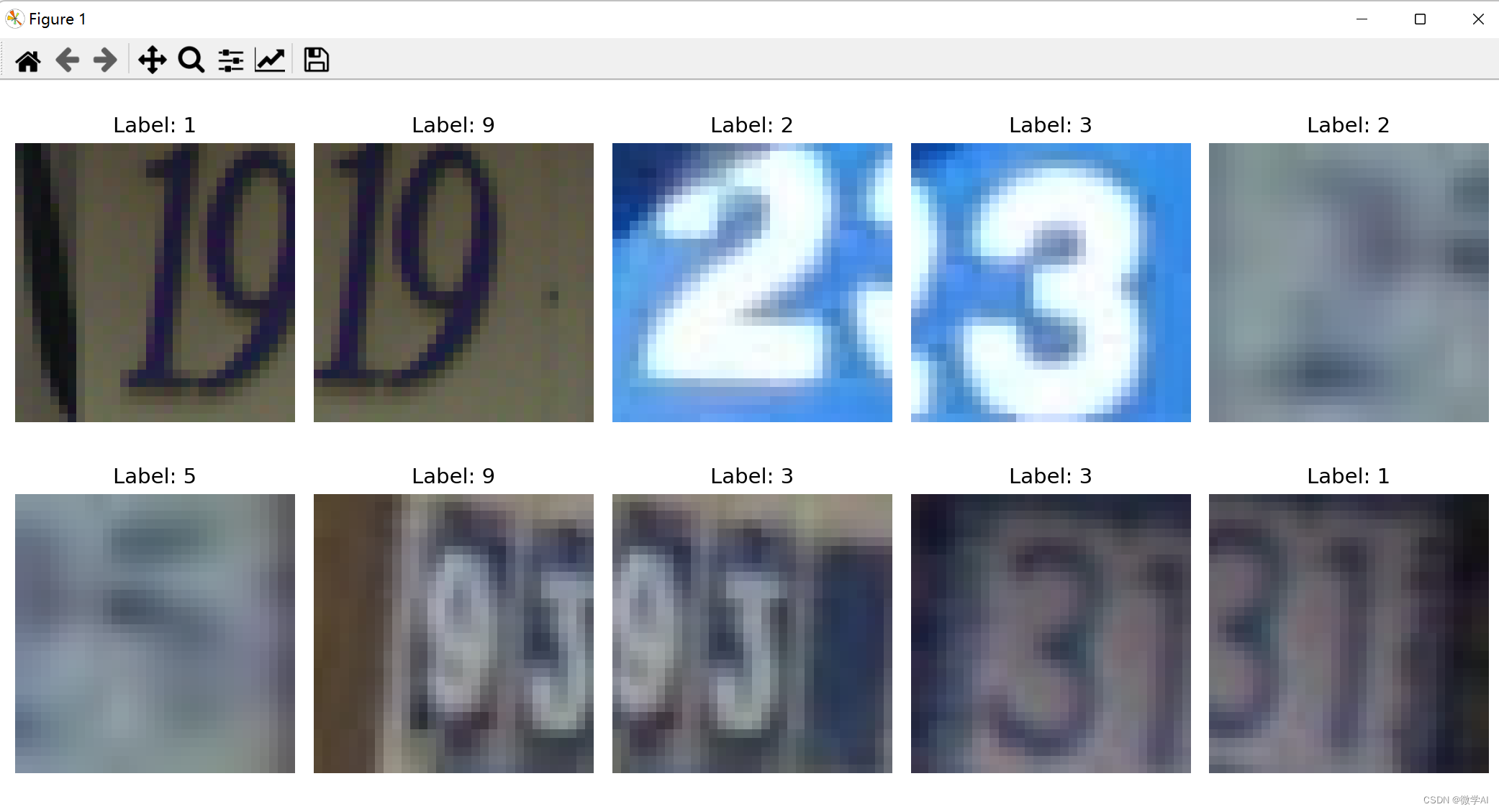
计算机视觉的应用11-基于pytorch框架的卷积神经网络与注意力机制对街道房屋号码的识别应用
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用11-基于pytorch框架的卷积神经网络与注意力机制对街道房屋号码的识别应用,本文我们借助PyTorch,快速构建和训练卷积神经网络(CNN)等模型,…


【论文笔记】CBAM:Convolutional Block Attention Module(卷积块注意力模型)
本文是关于论文《CBAM: Convolutional Block Attention Module》的阅读笔记。 一、概述
深度学习中的注意力机制是模仿人类的注意力产生的,当我们在看一副图像时,图像中有些地方(比如人物照中的人的面部)会引起我们的注意力&…
SCI一区 | Matlab实现RIME-TCN-BiGRU-Attention霜冰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现RIME-TCN-BiGRU-Attention霜冰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现RIME-TCN-BiGRU-Attention霜冰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述程…
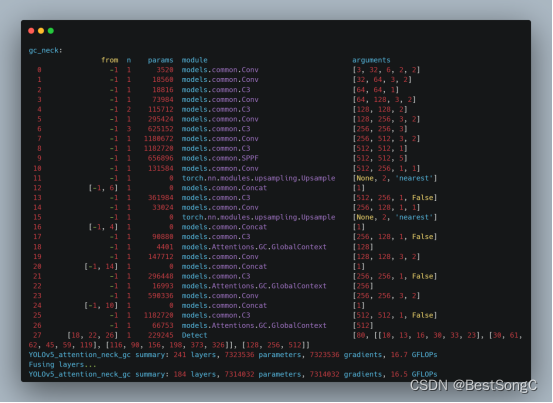
YOLO改进系列之注意力机制(GlobalContext模型介绍)
模型结构
通过捕获long-range dependency提取全局信息,对各种视觉任务都是很有帮助的,典型的方法是Non-local Network自注意力机制。对于每个查询位置(query position),Non-local network首先计算该位置和所有位置之间…
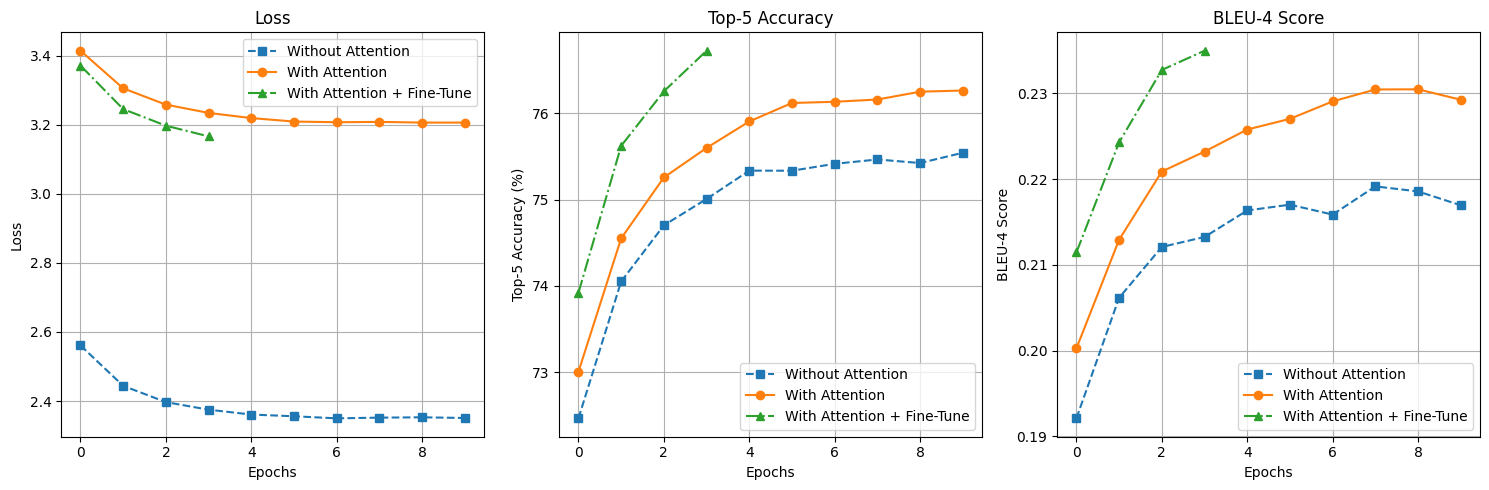
【深度学习】图像自然语言描述生成
案例 6:图像自然语言描述生成(让计算机“看图说话”)
相关知识点:RNN、Attention 机制、图像和文本数据的处理
1 任务目标
1.1 任务和数据简介
本次案例将使用深度学习技术来完成图像自然语言描述生成任务,输入…

目标点注意力Transformer:一种用于端到端自动驾驶的新型轨迹预测网络
目标点注意力Transformer:一种用于端到端自动驾驶的新型轨迹预测网络
附赠自动驾驶学习资料和量产经验:链接
摘要
本文介绍了目标点注意力Transformer:一种用于端到端自动驾驶的新型轨迹预测网络。在自动驾驶领域中,已经有很多…

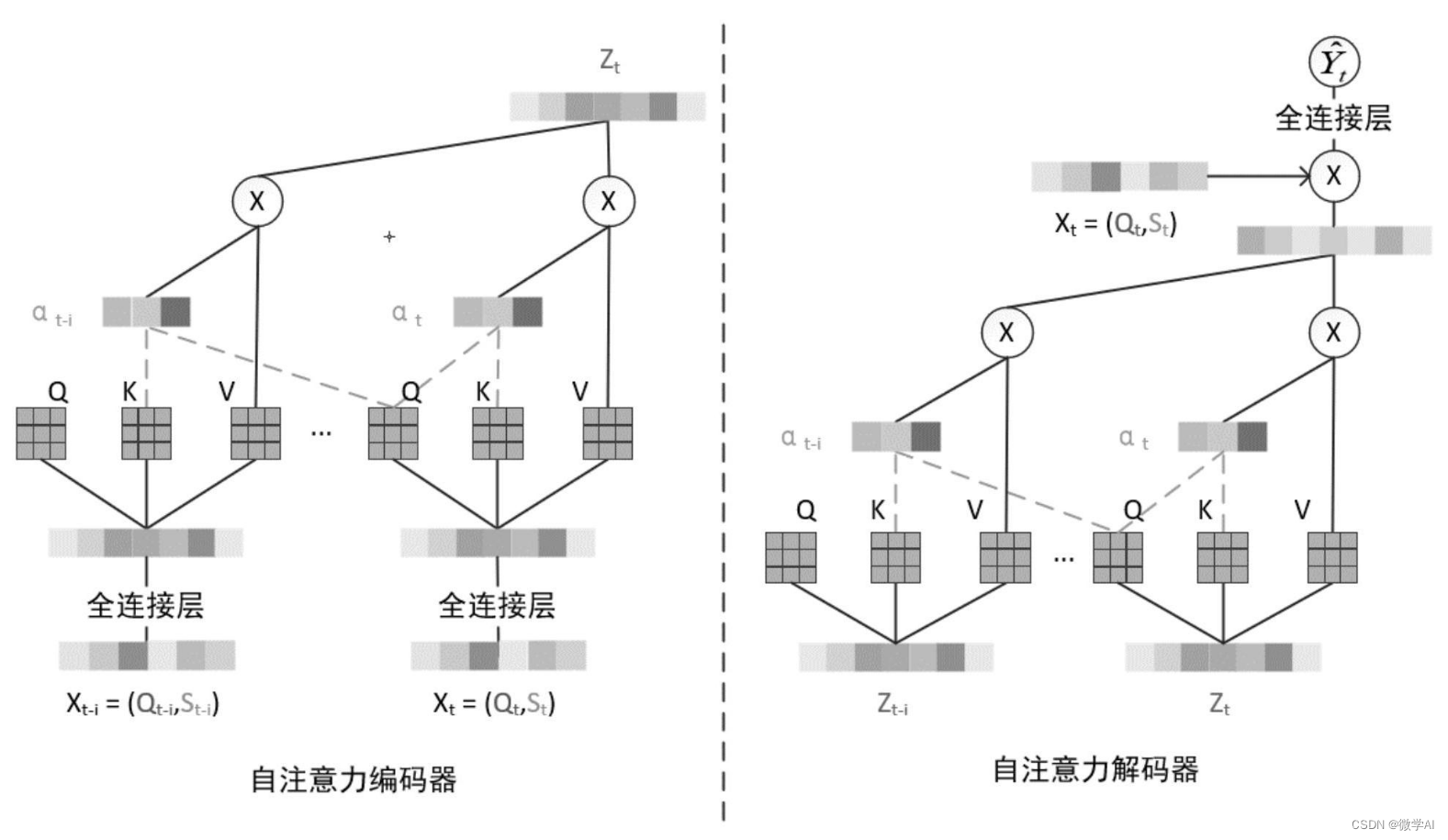
『大模型笔记』LLMs入门:从头理解与编码LLM的自注意力机制
LLMs入门:从头理解与编码LLM的自注意力机制 这里直接引用我语雀上的的文章:《从头理解与编码LLM的自注意力机制》

即插即用篇 | YOLOv8 引入 SENetv2 | 多套版本配合使用
卷积神经网络(CNNs)通过提取空间特征并在基于视觉的任务中实现了最先进的准确性,彻底改变了图像分类。所提出的压缩激励网络模块收集输入的通道表示。多层感知机(MLP)从数据中学习全局表示,在大多数用于学习图像提取特征的图像分类模型中起到关键作用。在本文中,我们引入…
【Roadmap to learn LLM】Large Language Models in Five Formulas
by Alexander Rush Our hope: reasoning about LLMs Our Issue 文章目录 Perpexity(Generation)Attention(Memory)GEMM(Efficiency)用矩阵乘法说明GPU的工作原理 Chinchilla(Scaling)RASP(Reasoning)结论参考资料 the five formulas perpexity —— generationattention —— m…
![[Python人工智能] 四十五.命名实体识别 (6)利用keras构建CNN-BiLSTM-ATT-CRF实体识别模型(注意力问题探讨)](https://img-blog.csdnimg.cn/bf1659094a5b4541a19a93c14fafa5d1.png#pic_center)
[Python人工智能] 四十五.命名实体识别 (6)利用keras构建CNN-BiLSTM-ATT-CRF实体识别模型(注意力问题探讨)
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前文讲解融合Bert的实体识别研究,使用bert4keras和kears包来构建Bert+BiLSTM-CRF模型。这篇文章将详细结合如何利用keras和tensorflow构建基于注意力机制的CNN-BiLSTM-ATT-CRF模型,并实现中文实体识别…
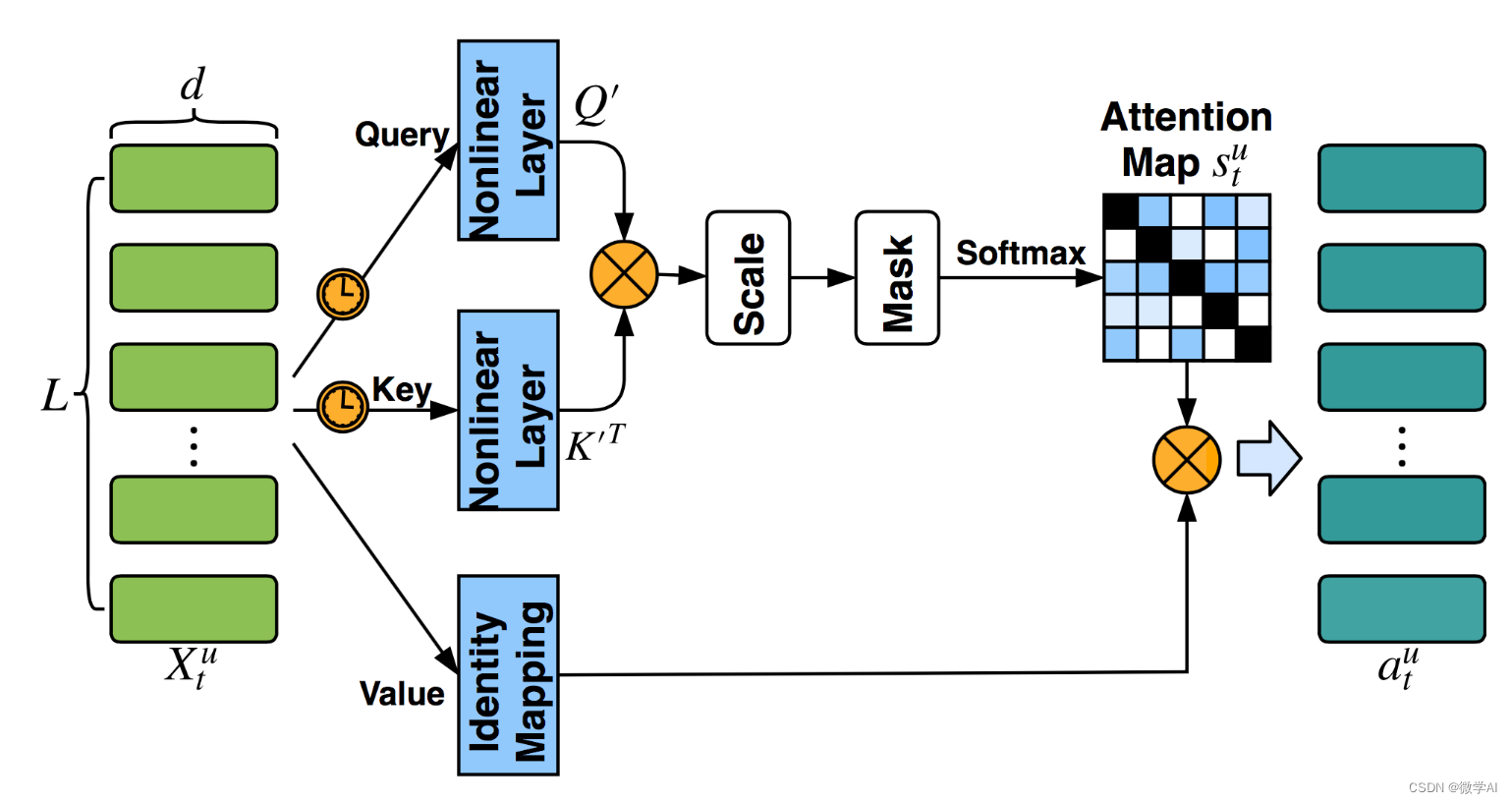
计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用,该项目主要引导大家使用pytorch深度学习框架,并熟悉注意力机制模型的搭建,这个…

Llama2模型的优化版本:Llama-2-Onnx
Llama2模型的优化版本:Llama-2-Onnx。
Llama-2-Onnx是Llama2模型的优化版本。Llama2模型由一堆解码器层组成。每个解码器层(或变换器块)由一个自注意层和一个前馈多层感知器构成。与经典的变换器相比,Llama模型在前馈层中使用了不…
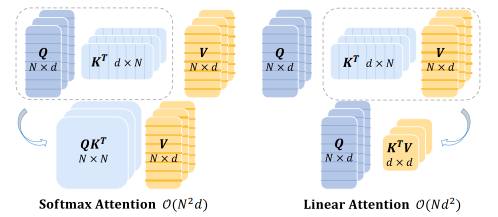
线性注意力机制全新升级!性能显著提高,速度、精度更优
线性注意力机制通过对传统注意力机制中的Softmax操作进行线性化处理,可以提高Transformer模型的并行性能、降低复杂度,在计算效率、模型表达能力等方面都具有优势。
作为一种常用有效的优化方法,线性注意力机制可以在保证模型性能的同时提高…

【LLM加速】注意力优化(基于位置/内容的稀疏注意力 | flashattention)
note
(1)近似注意力:
Routing Transformer采用K-means 聚类方法,针对Query和Key进行聚类,类中心向量集合为 { μ i } i 1 k \left\{\boldsymbol{\mu}_i\right\}_{i1}^k {μi}i1k ,其中k 是类中心的…
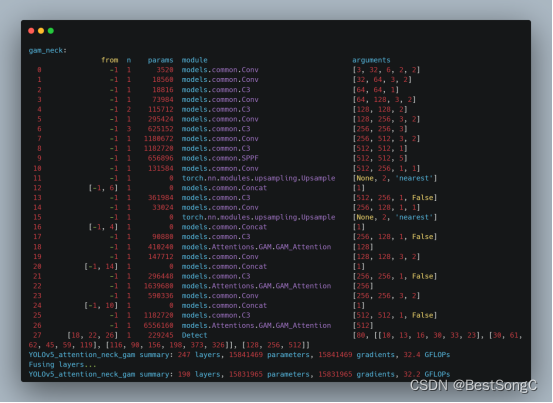
YOLO改进系列之注意力机制(GAM Attention模型介绍)
模型结构
为了提高计算机视觉任务的性能,人们研究了各种注意力机制。然而以往的方法忽略了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,liu提出了一种通过减少信息弥散和放大全局交互表示来提高深度神经网络性能的全局注意力机制。作者的目…
分类预测 | Matlab基于TTAO-CNN-LSTM-Attention三角拓扑聚合优化算法优化卷积神经网络-长短期记忆网络-注意力机制的数据分类预测
分类预测 | Matlab基于TTAO-CNN-LSTM-Attention三角拓扑聚合优化算法优化卷积神经网络-长短期记忆网络-注意力机制的数据分类预测 目录 分类预测 | Matlab基于TTAO-CNN-LSTM-Attention三角拓扑聚合优化算法优化卷积神经网络-长短期记忆网络-注意力机制的数据分类预测分类效果基…
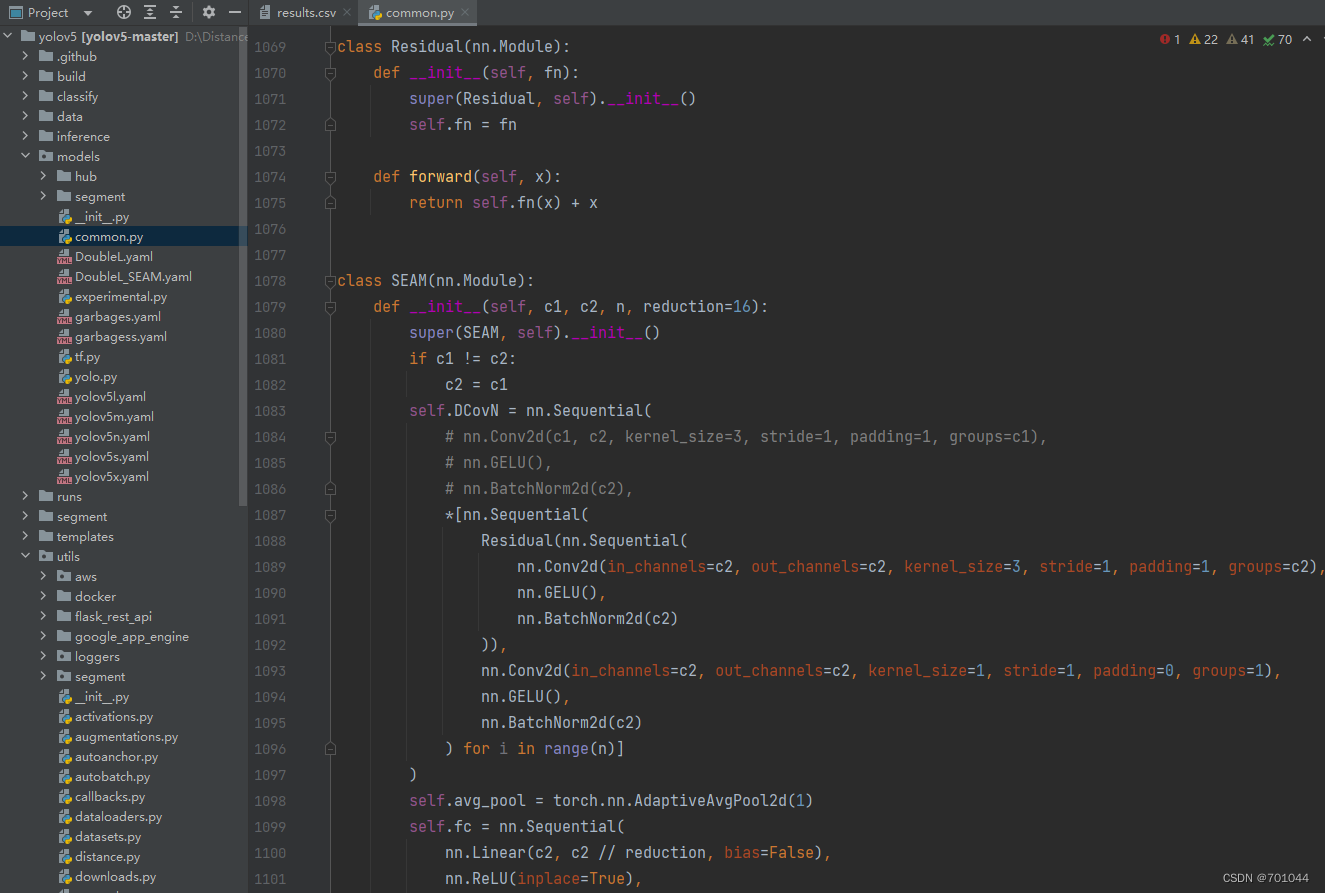
YOLOv5、YOLOv7 注意力机制改进SEAM、MultiSEAM、TripletAttention
用于学习记录 文章目录 前言一、SEAM、MultiSEAM1.1 models/common.py1.2 models/yolo.py1.3 models/SEAM.yaml1.4 models/MultiSEAM.yaml1.5 SEAM 训练结果图1.6 MultiSEAM 训练结果图二、TripletAttention2.1 models/common.py2.2 models/yolo.py2.3 yolov7/cfg/training/Tri…

深度学习实战49-基于卷积神经网络和注意力机制的汽车品牌与型号分类识别的应用
大家好,我是微学AI,今天给大家介绍一下深度学习实战49-基于卷积神经网络和注意力机制的汽车品牌与型号分类识别的应用,该项目就像是一只智慧而敏锐的眼睛,专注地凝视着汽车世界。这个项目使用PyTorch作为强有力的工具,提供了一个深度学习的舞台,让我们能够设计和训练一个…
注意力机制(一):注意力提示、注意力汇聚、Nadaraya-Watson 核回归
专栏:神经网络复现目录
注意力机制
注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语…

神经网络学习小记录78——Keras CA(Coordinate attention)注意力机制的解析与代码详解
神经网络学习小记录78——Keras CA(Coordinate attention)注意力机制的解析与代码详解 学习前言代码下载CA注意力机制的概念与实现注意力机制的应用 学习前言
CA注意力机制是最近提出的一种注意力机制,全面关注特征层的空间信息和通道信息。…
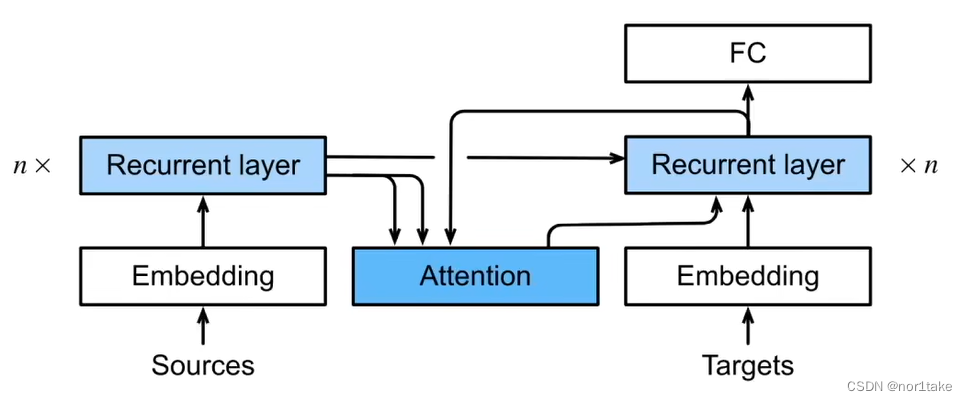
seq2seq与引入注意力机制的seq2seq
1、什么是 seq2seq?
就是字面意思,“句子 到 句子”。比如翻译。
2、seq2seq 有一些特点
seq2seq 的整体架构是 “编码器-解码器”。
其中,编码器是 RNN,并将 最后一个hidden state(隐藏状态)【即&…

NLP中的Seq2Seq与attention注意力机制
文章目录 RNN循环神经网络seq2seq模型Attention(注意力机制)总结参考文献RNN循环神经网络
RNN循环神经网络被广泛应用于自然语言处理中,对于处理序列数据有很好的效果,常见的序列数据有文本、语音等,至于为什么要用到循环神经网络而不是传统的神经网络,我们在这里举一个…
深度学习缝模块怎么描述创新点?(附写作模板+涨点论文)
深度学习缝了别的模块怎么描述创新点、怎么讲故事写成一篇优质论文?
简单框架:描述自己这个领域,该领域出现了什么问题,你用了什么方法解决,你的方法有了多大的性能提升。
其中,重点讲清楚这两点…

分类预测 | Matlab实现CWT-DSCNN-MSA基于时序特征、cwt小波时频图的双流卷积融合注意力机制的分类预测
分类预测 | Matlab实现CWT-DSCNN-MSA基于时序特征、cwt小波时频图的双流卷积融合注意力机制的分类预测 目录 分类预测 | Matlab实现CWT-DSCNN-MSA基于时序特征、cwt小波时频图的双流卷积融合注意力机制的分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述
1.Matlab…

即插即用篇 | YOLOv8 引入 NAM 注意力机制 | 《NAM: Normalization-based Attention Module》
论文名称:《NAM: Normalization-based Attention Module》
论文地址:https://arxiv.org/pdf/2111.12419.pdf
代码地址:https://github.com/Christian-lyc/NAM 文章目录 1 原理2 源代码3 添加方式4 模型 yaml 文件template-backbone.yamltemplate-small.yamltemplate-large…
SE、CBAM、ECA注意力机制(网络结构详解+详细注释代码+核心思想讲解+注意力机制优化神经网络方法)——pytorch实现
这期博客我们来学习一下神秘已久的注意力机制,刚开始接触注意力机制的时候,感觉很有意思,事实上学会之后会发现比想象中的要简单,复杂的注意力机制后续会讲解,这期博客先讲解最常见的三种SE、CBAM、ECA注意力机制。 注意力机制更详细的可以被称为资源分配机制,神经网络的…

Google新作synthesizer:Rethinking Self-Attention in Transformer Models
0. 背景
机构:Google Research 作者:Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, Che Zheng 论文地址:https://arxiv.org/abs/2005.00743
0.1 摘要
以当下基于Transformer的各种先进模型来看,使用点积自注意…
PyTorch实现注意力机制及使用方法汇总,附30篇attention论文
还记得鼎鼎大名的《Attention is All You Need》吗?不过我们今天要聊的重点不是transformer,而是注意力机制。
注意力机制最早应用于计算机视觉领域,后来也逐渐在NLP领域广泛应用,它克服了传统的神经网络的的一些局限,…

YOLOV7 添加 CBAM 注意力机制
用于学习记录 文章目录 前言一、CBAM1.1 models/common.py1.2 models/yolo.py1.3 yolov7/cfg/training/CBAM.yaml2.4 CBAM 训练结果图 前言 一、CBAM
CBAM: Convolutional Block Attention Module
1.1 models/common.py
class ChannelAttention(nn.Module):def __init__(sel…
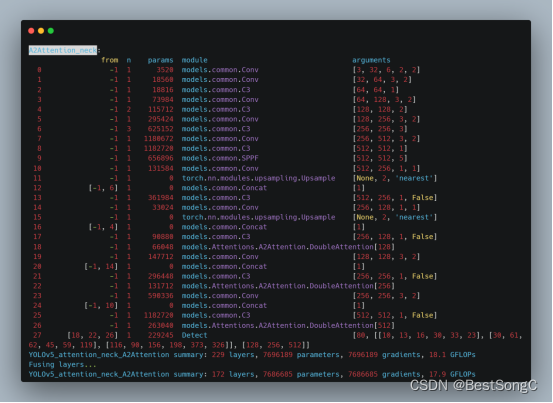
A2Attention模型介绍
A2Attention的核心思想是首先将整个空间的关键特征收集到一个紧凑的集合中,然后自适应地将其分布到每个位置,这样后续的卷积层即使没有很大的接收域也可以感知整个空间的特征。第一级的注意力集中操作有选择地从整个空间中收集关键特征,而第二…
机器学习笔记 - 结合深度学习的基于内容的图像实例检索 利用现成的DCNN模型进行检索
一、简述 上一篇,基于内容的图像实例检索综述。
https://mp.csdn.net/mp_blog/creation/editor/131415155https://mp.csdn.net/mp_blog/creation/editor/131415155 一种方案是,为分类任务而进行大规模训练的DCNN直接充当图像检索任务的现成特征检测器,也就是说,可以…

Multi-Attention Convolutional Network笔记
此篇文章记录自己对2017年的ICCV一篇关于图像领域的注意力模型的理解。(论文题目《Learning Multi-Attention Convolutional Neural Network for Fine-Grained Image Recognition》) Approach
整个结构由三部分组成,分别是特征提取的卷积层、…
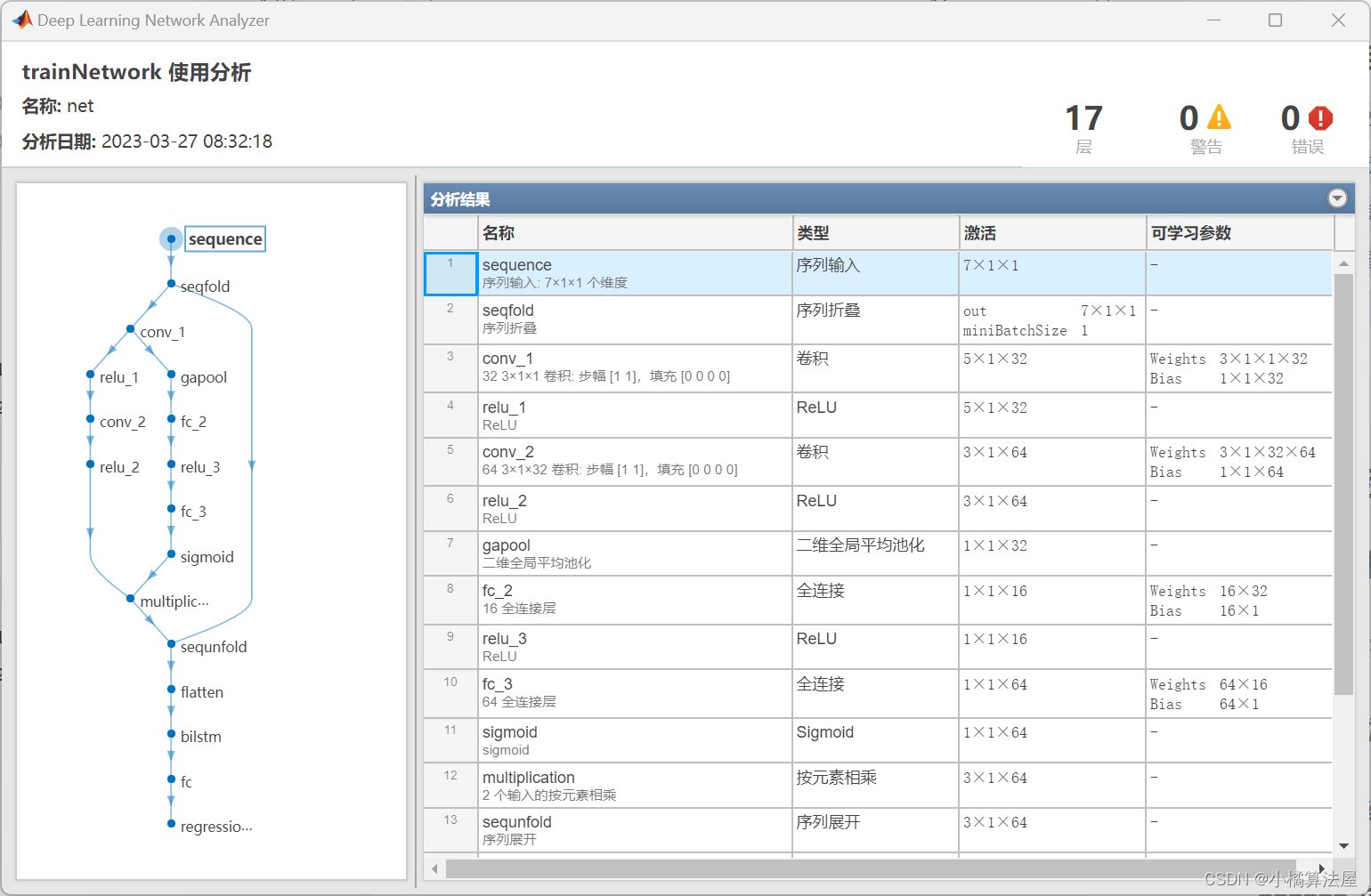
注意力机制 | CNN-BiLSTM-Attention基于卷积-双向长短期记忆网络结合注意力机制多输入单输出回归预测(Matlab程序)
注意力机制 | CNN-BiLSTM-Attention基于卷积-双向长短期记忆网络结合注意力机制多输入单输出回归预测(Matlab程序) 目录 注意力机制 | CNN-BiLSTM-Attention基于卷积-双向长短期记忆网络结合注意力机制多输入单输出回归预测(Matlab程序)预测结果评价指标基本介绍程序设计参…

时序预测 | MATLAB实现Attention-GRU时间序列预测(注意力机制融合门控循环单元,TPA-GRU)
时序预测 | MATLAB实现Attention-GRU时间序列预测----注意力机制融合门控循环单元,即TPA-GRU,时间注意力机制结合门控循环单元 目录 时序预测 | MATLAB实现Attention-GRU时间序列预测----注意力机制融合门控循环单元,即TPA-GRU,时…
轻量自高斯注意力(LSGA)机制
light(轻量)Self-Gaussian-Attention vision transformer(高斯自注意力视觉transformer) for hyperspectral image classification(高光谱图像分类) 论文:Light Self-Gaussian-Attention Vision…
分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】
分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】 目录 分类预测 | Matlab实现RP-CNN-LSTM-Attention递归图优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】分类效果基本描述模型描述程…
CBAM: Convolutional Block Attention Module 卷积块注意模块详解
论文地址:https://arxiv.org/abs/1807.06521
1. 摘要
我们提出了卷积块注意模块 (CBAM), 一个简单而有效的注意模块的前馈卷积神经网络。给出了一个中间特征映射, 我们的模块按照两个独立的维度、通道和空间顺序推断出注意力映射, 然后将注意力映射相乘为自适应特…
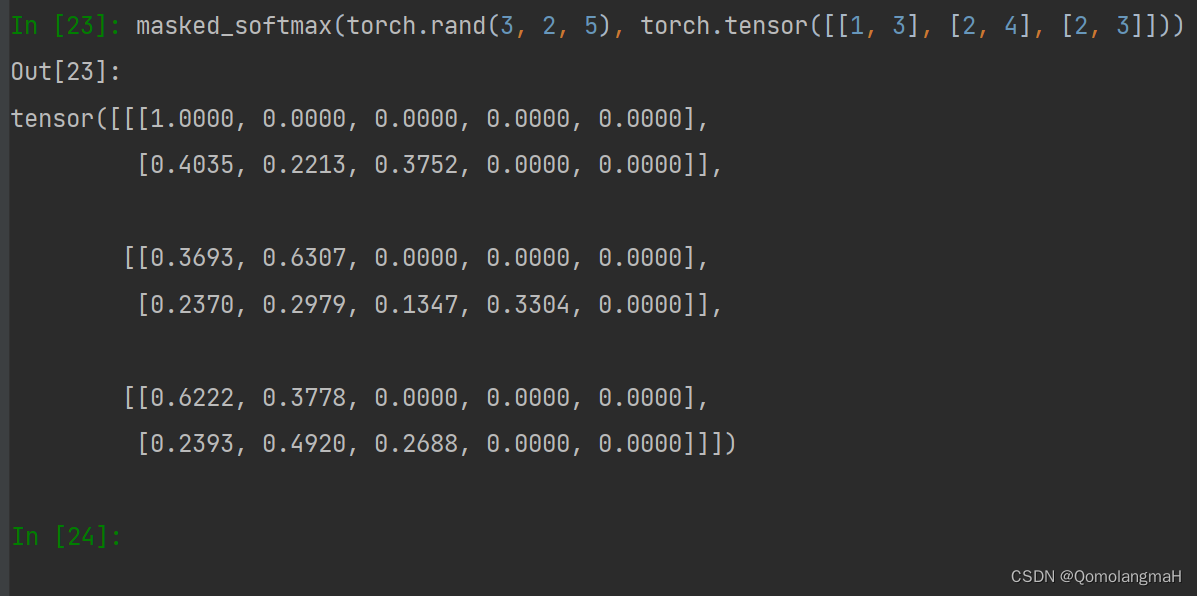
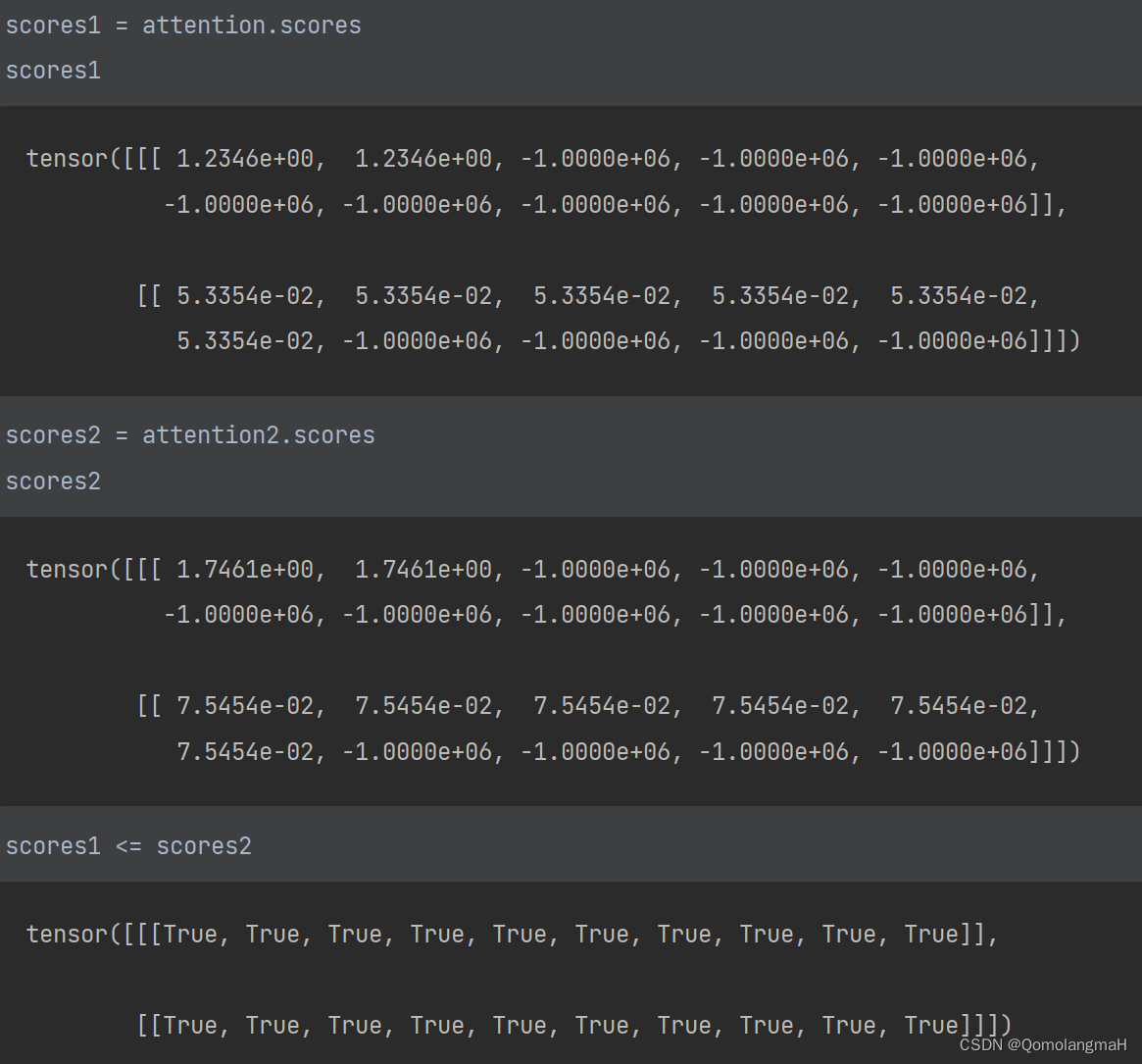
【深度学习实验】注意力机制(二):掩码Softmax 操作
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 理论介绍a. 认知神经学中的注意力b. 注意力机制: 1. 注意力权重矩阵可视化(矩阵热图)2. 掩码Softmax 操作a. 导入必要的库b. masked_softmaxc. 实验结果
…

FlashAttention算法详解
这篇文章的目的是详细的解释Flash Attention,为什么要解释FlashAttention呢?因为FlashAttention 是一种重新排序注意力计算的算法,它无需任何近似即可加速注意力计算并减少内存占用。所以作为目前LLM的模型加速它是一个非常好的解决方案&…

注意力机制——SENet原理详解及源码解析
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…

论文学习——融合注意力机制的时间卷积知识追踪模型
文章目录0 封面1 标题2 摘要3 结语4 引言5 结束阅读,方向不一致,而且TCN已经被多次使用写在前面:《华中科技大学学报(自然科学版)》;主办单位:四川省科学技术协会;中文核心ÿ…

图像处理之《基于端到端哈希生成模型的鲁棒无覆盖图像隐写》论文精读
一、文章摘要
近年来,无覆盖隐写算法因其完全抵抗隐写分析算法的能力而引起了越来越多的研究关注。然而,现有的算法在面对几何攻击和非几何攻击时,无法达到同样的鲁棒性平衡。此外,现有的方法大多需要在隐写图像的同时传输一些辅…
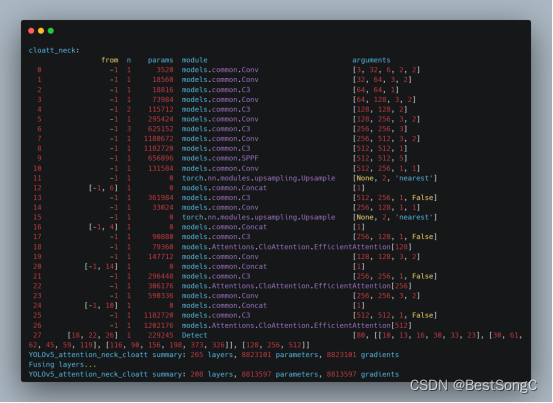
YOLO改进系列之注意力机制(CloAttention模型介绍)
CloAttention来自清华大学的团队提出的一篇论文CloFormer,作者从频域编码的角度认为现有的轻量级视觉Transformer中,大多数方法都只关注设计稀疏注意力,来有效地处理低频全局信息,而使用相对简单的方法处理高频局部信息。很少有方…
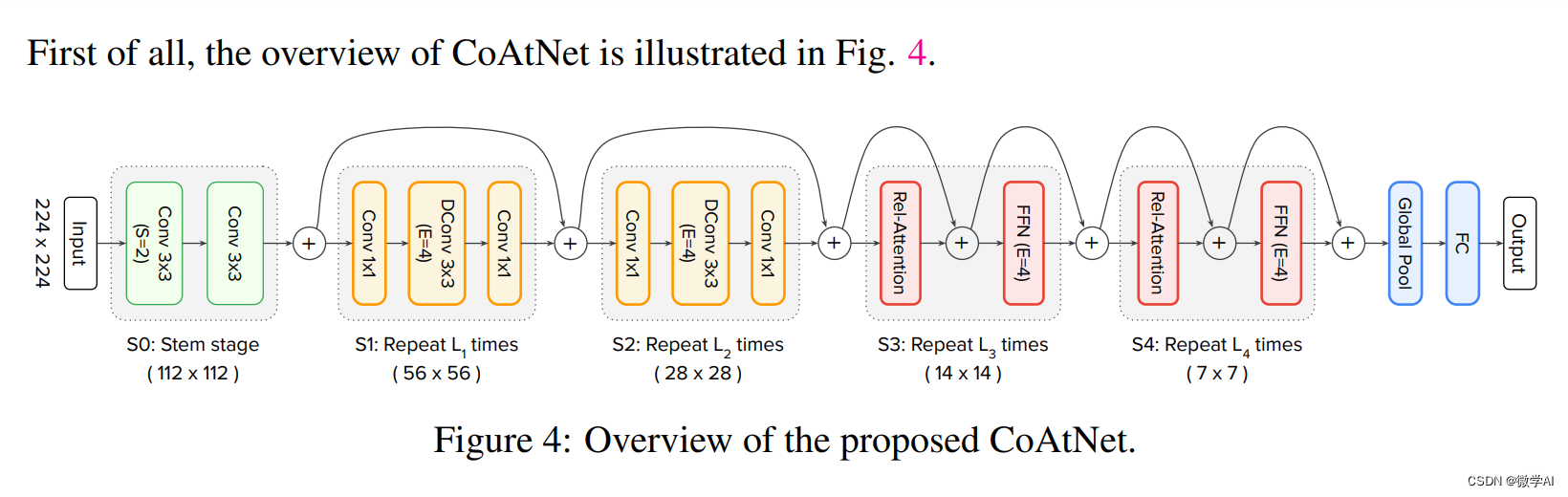
计算机视觉的应用21-基于含有注意力机制的CoAtNet模型的图像分类任务实现,利用pytorch搭建模型
大家好,我是微学AI,今天我给大家介绍一下计算机视觉的应用21-基于注意力机制CoAtNet模型的图像分类任务实现,加载数据进行模型训练。本文我们将详细介绍CoAtNet模型的原理,并通过一个基于PyTorch框架的实例,展示如何加…
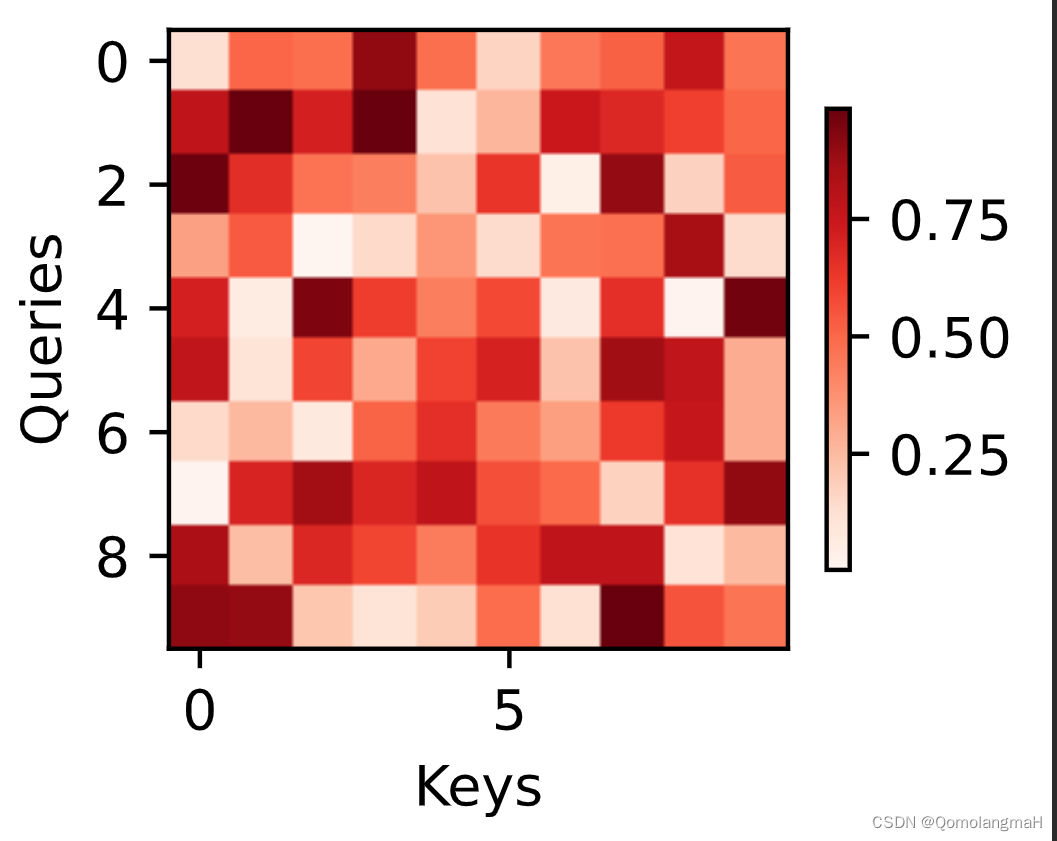
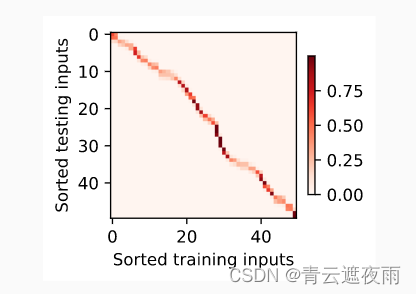
【深度学习实验】注意力机制(一):注意力权重矩阵可视化(矩阵热图heatmap)
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 理论介绍a. 认知神经学中的注意力b. 注意力机制: 1. 注意力权重矩阵可视化(矩阵热图)a. 导入必要的库b. 可视化矩阵热图(show_heatmaps࿰…
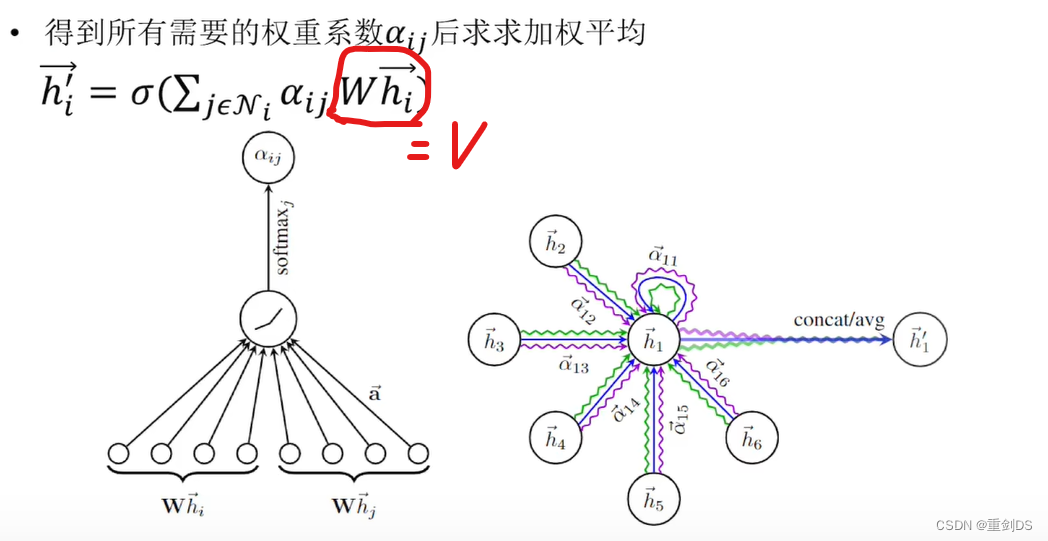
注意力机制QKV在GAT(Graph Attention Network)的体现
GAT(Graph Attention Network)被称为注意力机制的一种图神经网络,它使用了注意力机制的思想。 在GAT中,每个节点与其邻居节点之间的关系被建模为具有不同权重的注意力权重。这就涉及到了注意力机制中的Q(查询ÿ…

神经网络 || 注意力机制的Pytorch代码实现
文章目录1 注意力机制的诞生2 介绍SeNet模型及Pytorch代码实现1 注意力机制的诞生
注意力机制,起初是作为自然语言处理中的工作为大家熟知,文章Attention is all you need详细介绍了“什么是注意力机制”,有兴趣的小伙伴可以下载原文看看。 …

transformer的学习记录【完整代码+详细注释】(系列二)
文章目录1 编码器部分实现1.1 掩码张量1.1.1 用 np.triu 生产上三角矩阵1.1.2 生成掩码张量的代码1.1.3 掩码张量可视化展示1.1.4 掩码张量学习总结1.2 注意力机制1.2.1 注意力机制 vs 自注意力机制1.2.2 注意力机制代码解读1.2.3 masked_fill 函数介绍1.2.3 注意力机制的实现代…
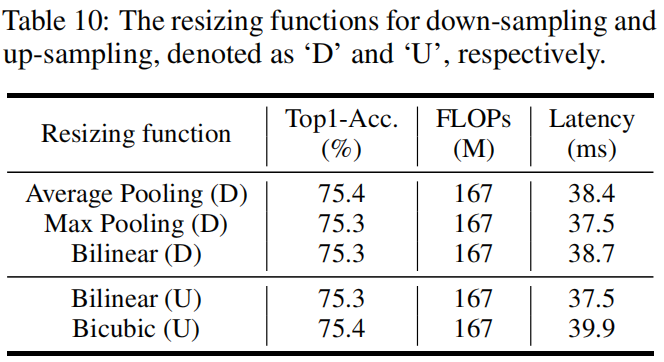
GhostNet v2(NeurIPS 2022 Spotlight)原理与代码解析
paper:GhostNetV2: Enhance Cheap Operation with Long-Range Attentioncode:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv2_pytorch背景在智能手机和可穿戴设备上部署神经网络时,不仅要考虑模型的性能&…
![深度学习基础入门篇[六(1)]:模型调优:注意力机制[多头注意力、自注意力],正则化【L1、L2,Dropout,Drop Connect】等](https://img-blog.csdnimg.cn/img_convert/aa43037280f3646179c75764402f12b3.png)
深度学习基础入门篇[六(1)]:模型调优:注意力机制[多头注意力、自注意力],正则化【L1、L2,Dropout,Drop Connect】等
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…
注意力机制在超分辨率中的应用总结
1. 注意机制可分为两种类型
根据它们所适用的范围:通道注(CA)和空间注意(SA)。CA和SA可以进一步分为三个过程:
squeeze:通过通道(CA)或空间区域(SA)从X中提取一个或多个统计量S的过程。统计量通过池化方法提取,SA可使…

SeNet || 注意力机制——源代码+注释
文章目录1 SeNet介绍2 SeNet优点3 Se模块的具体介绍4 完整代码1 SeNet介绍
SENet是Squeeze-and-Excitation Networks的简称,由Momenta公司所作并发于2017CVPR,论文中的SENet赢得了ImageNet最后一届(ImageNet 2017)的图像识别冠军…

即插即用篇 | YOLOv8 引入 SKAttention 注意力机制 | 《Selective Kernel Networks》
论文名称:《Selective Kernel Networks》
论文地址:https://arxiv.org/pdf/1903.06586.pdf
代码地址:https://github.com/implus/SKNet 文章目录 1 原理2 源代码3 添加方式4 模型 yaml 文件template-backbone.yamltemplate-small.yamltemplate-large.yaml
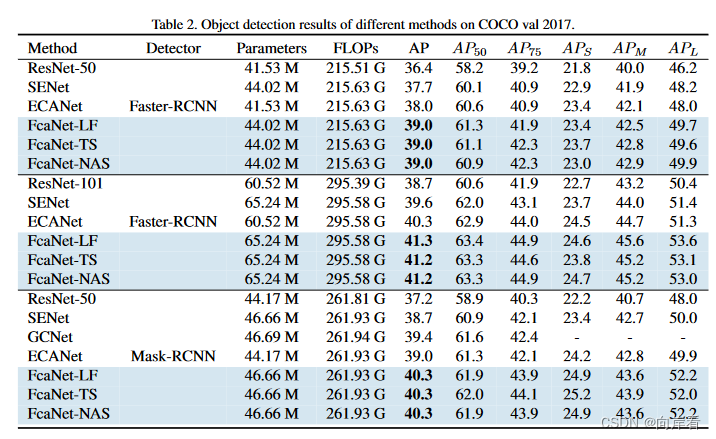
FcaNet: Frequency Channel Attention Networks论文总结和代码详解
论文:https://arxiv.org/abs/2012.11879 中文版:FcaNet: Frequency Channel Attention Networks 源码:https://github.com/cfzd/FcaNet或https://gitee.com/yasuo_hao/FcaNet 目录
一、论文背景和出发点
二、创新点
三、离散余弦变换&…

【深度学习笔记】注意力机制——注意力提示
注意力提示
🏷sec_attention-cues
感谢读者对本书的关注,因为读者的注意力是一种稀缺的资源:此刻读者正在阅读本书(而忽略了其他的书),因此读者的注意力是用机会成本(与金钱类似)来…
深度学习中的注意力机制(Attention)
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
…
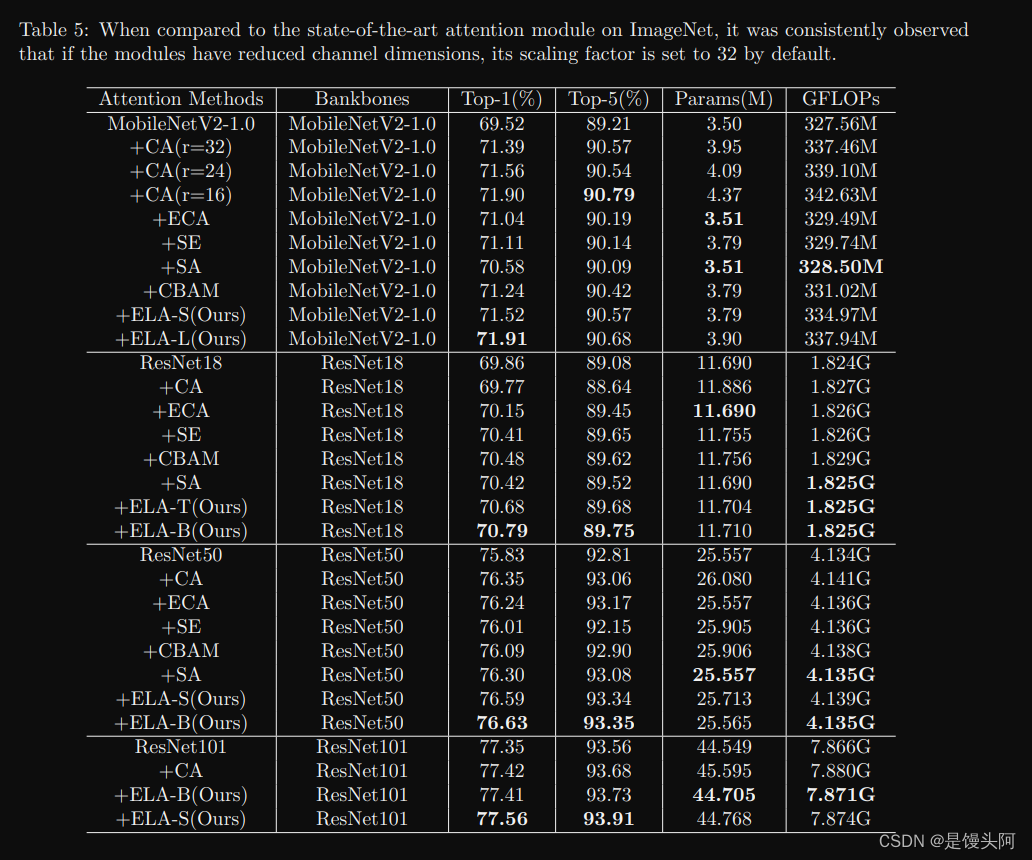
48、兰州大学、青海师范:专门用于深度CNNs的天阶斗技-ELA Local Attention
本文由兰州大学信息科学与工程学院、青海省物联网重点实验室、青海师范大学于2024年3.2日发表于ArXiv。为了解决现有的注意力模型在有效利用空间信息方面存在的限制和困难,提出了一种高效的局部注意力ELA模型。该方法通过分析坐标注意力的局限性,作者识别…
分类预测 | Matlab实现ZOA-CNN-LSTM-Attention斑马优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】
分类预测 | Matlab实现ZOA-CNN-LSTM-Attention斑马优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】 目录 分类预测 | Matlab实现ZOA-CNN-LSTM-Attention斑马优化卷积长短期记忆神经网络注意力机制的数据分类预测【24年新算法】分类效果基本描述程序设计参考…

Self-Attention-Generative-Adversarial-Networks(2019 ICML,HanZhang IanGoodfellow)
文章目录1 背景2 挑战3 创新4 方法5 实验1 背景
自从GAN提出后,其在图像合成领域一直非常火热,尤其是基于深度卷积神经网络的GAN。
对于多分类实验结果不理想,GAN擅于获取具有连续几何结构的模式,比如能精确模拟狗的毛发而对几只…
各种注意力机制,Attention、MLP、ReP等系列的PyTorch实现,含核心代码
不知道CV方向的同学在读论文的时候有没有发现这样一个问题:论文的核心思想很简单,但当你找这篇论文的核心代码时发现,作者提供的源码模块会嵌入到分类、检测、分割等任务框架中,这时候如果你对某一特定框架不熟悉,尽管…

计算机视觉注意力机制小盘一波 (学习笔记)
将注意力的阶段大改分成了4个阶段
1.将深度神经网络与注意力机制相结合,代表性方法为RAM
⒉.明确预测判别性输入特征,代表性方法为STN
3.隐性且自适应地预测潜在的关键特征,代表方法为SENet
4.自注意力机制
通道注意力
在深度神经网络中…

因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)
Causal Attention for Vision-Language Tasks
引言 这篇论文是南洋理工大学和澳大利亚莫纳什大学联合发表自2021年的CVPR顶会上的一篇文献,在当前流行的注意力机制中增加了因果推理算法,提出了一种新的注意力机制:因果注意力(CATT)ÿ…
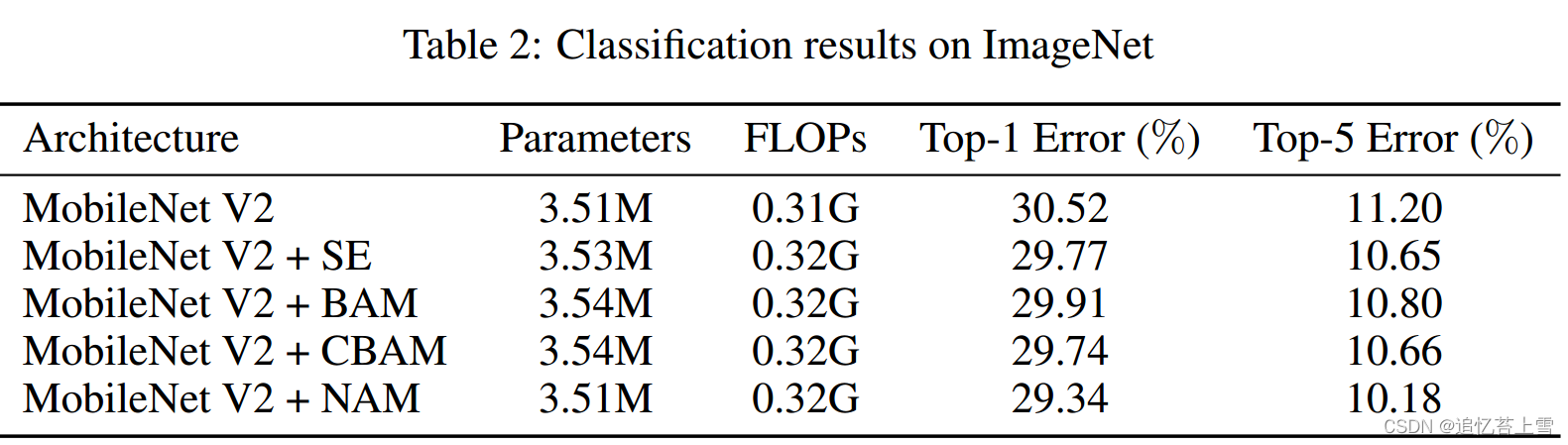
论文阅读NAM:Normalization-based Attention Module
Abstarct
识别不太显著的特征是模型压缩的关键。然而,在革命性的注意力机制中却没有对其进行研究。在这项工作中,我们提出了一种新的基于归一化的注意力模块(NAM),它抑制了不太显著的权重。它对注意力模块应用了权重稀…
深度学习技巧应用26-CNN中多种注意力机制的嵌入方法,终于搞懂注意力机制了
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用26-CNN中多种注意力机制的嵌入方法,终于搞懂注意力机制了。CNN是一种能够有效处理图像和其他二维数据的深度学习模型。在传统的CNN中,每个卷积核都会对输入的所有位置进行相同的操作,这可能导致网络无法针对特定区域…

Lecture 11 Contextual Representation
目录 Problems with Word Vectors/Embeddings 词向量/嵌入的问题RNN 语言模型Bidirectional RNN 双向 RNNEmbeddings from Language Models 基于语言模型的嵌入ELMo 架构Downstream Task: POS Tagging 下游任务:词性标注ELMo 的表现如何?Other Findings上…
注意力机制、Transformer模型、生成式模型、目标检测算法、图神经网络、强化学习、深度学习模型可解释性与可视化方法等详解
采用“理论讲解案例实战动手实操讨论互动”相结合的方式,抽丝剥茧、深入浅出讲解注意力机制、Transformer模型(BERT、GPT-1/2/3/3.5/4、DETR、ViT、Swin Transformer等)、生成式模型(变分自编码器VAE、生成式对抗网络GAN、扩散模型…
注意力机制论文笔记:Neural Machine Translation by Jointly Learning to Align and Translate
论文原文镇四方,大神护我科研顺利,顶会约稿~~ 这是注意力机制落地到自然语言处理的一篇论文,好像是第一篇,没有考究。
论文中心思想:在传统的机器翻译模型(encoder-decoder)中的decoder中加入注…
【深度学习实验】注意力机制(四):点积注意力与缩放点积注意力之比较
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 理论介绍a. 认知神经学中的注意力b. 注意力机制 1. 注意力权重矩阵可视化(矩阵热图)2. 掩码Softmax 操作3. 打分函数——加性注意力模型3. 打分函数——点积注意力与缩放…
CBAM:卷积注意力机制
文章目录 CBAM结构Channel attention moduleSpatial attention moduleArrangement of attention modules对比实验ablation对比实验通道注意力的avgpooling vs. maxpoolingSpatial attention对比实验Arrangement of the channel and spatial attention数据集验证ImageNet-1K可视…
分类预测 | Matlab实现RP-LSTM-Attention递归图优化长短期记忆神经网络注意力机制的数据分类预测【24年新算法】
分类预测 | Matlab实现RP-LSTM-Attention递归图优化长短期记忆神经网络注意力机制的数据分类预测【24年新算法】 目录 分类预测 | Matlab实现RP-LSTM-Attention递归图优化长短期记忆神经网络注意力机制的数据分类预测【24年新算法】分类效果基本描述模型描述程序设计参考资料 分…

【MVDiffusion】完美复刻场景,可多视图设计的生成式模型
文章目录 MVDiffusion1. 自回归 生成 全景图1.1 错误积累1.2 角度变换大 2. 模型结构2.1 多视图潜在扩散模型(mutil-view LDM)2.1.1 Text-conditioned generation model2.1.2 Image&text-conditioned generation model2.1.3 额外的卷积层 2.2 Correspondence-aware Attenti…
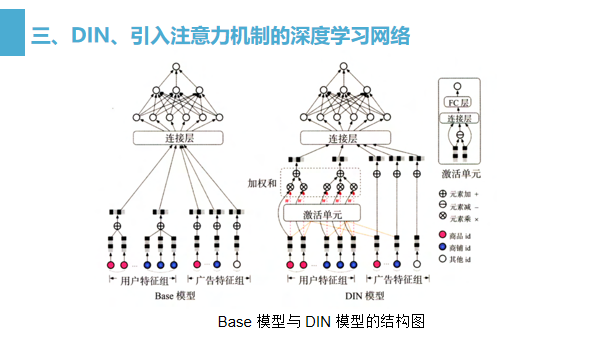
注意力机制在推荐模型中的应用
目录
一、注意力机制在推荐模型中的应用
二、AFM-引入注意力机制的FM
三、DIN、引入注意力机制的深度学习网络
四、强化学习与推荐系统结合 用户在浏览网页时,会选择性的注意页面的特定区域,忽视其他区域。 从17年开始,推荐领域开始尝试将…
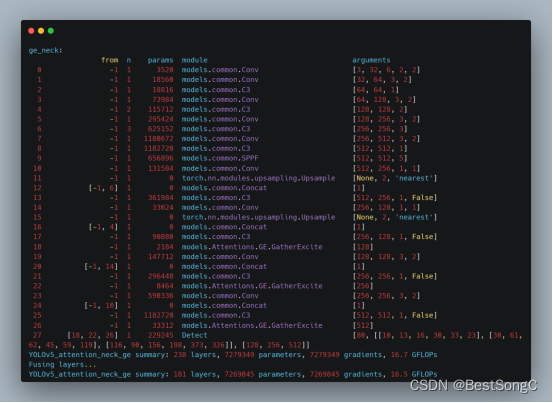
YOLO改进系列之注意力机制(GatherExcite模型介绍)
模型结构
尽管在卷积神经网络(CNN)中使用自底向上的局部运算符可以很好地匹配自然图像的某些统计信息,但它也可能阻止此类模型捕获上下文的远程特征交互。Hu等人提出了一种简单,轻量级的方法,以在CNN中更好地利用上下…
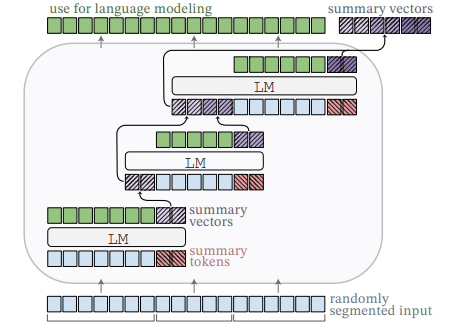
大模型提效105篇必读论文和代码汇总,涵盖预训练、注意力、微调等7个方向
大型语言模型(LLMs)在NLP领域中具有显著的优势,它们在语言理解和生成方面表现出了强大的能力,甚至可以进行复杂的推理任务。这些能力能让大模型在许多领域都有广泛的应用前景,比如文本生成、对话系统、机器翻译、情感分…
transformer的学习记录【完整代码+详细注释】(系列七)
文章目录1 模型基本测试运行——copy任务2 介绍优化器和损失函数2.1 优化器和损失函数的代码2.2 介绍 标签平滑函数2.2.1 理论知识2.2.2 具体的参数以及代码展示2.3 训练和预测第一节:transformer的架构介绍 输入部分的实现 链接:https://editor.csdn.n…
注意力机制(一)SE模块(Squeeze-and-Excitation Networks)
Squeeze-and-Excitation Networks(压缩和激励网络) 论文地址:Squeeze-and-Excitation Networks 论文中文版:Squeeze-and-Excitation Networks_中文版 代码地址:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Ne…

HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis行人属性2017
代码: https://github.com/xh-liu/HydraPlus-Net
原文:https://arxiv.org/abs/1709.09930
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis,来自SenseTime的论文,提出了一个基于注意力机制的深度网络HydraPlus…
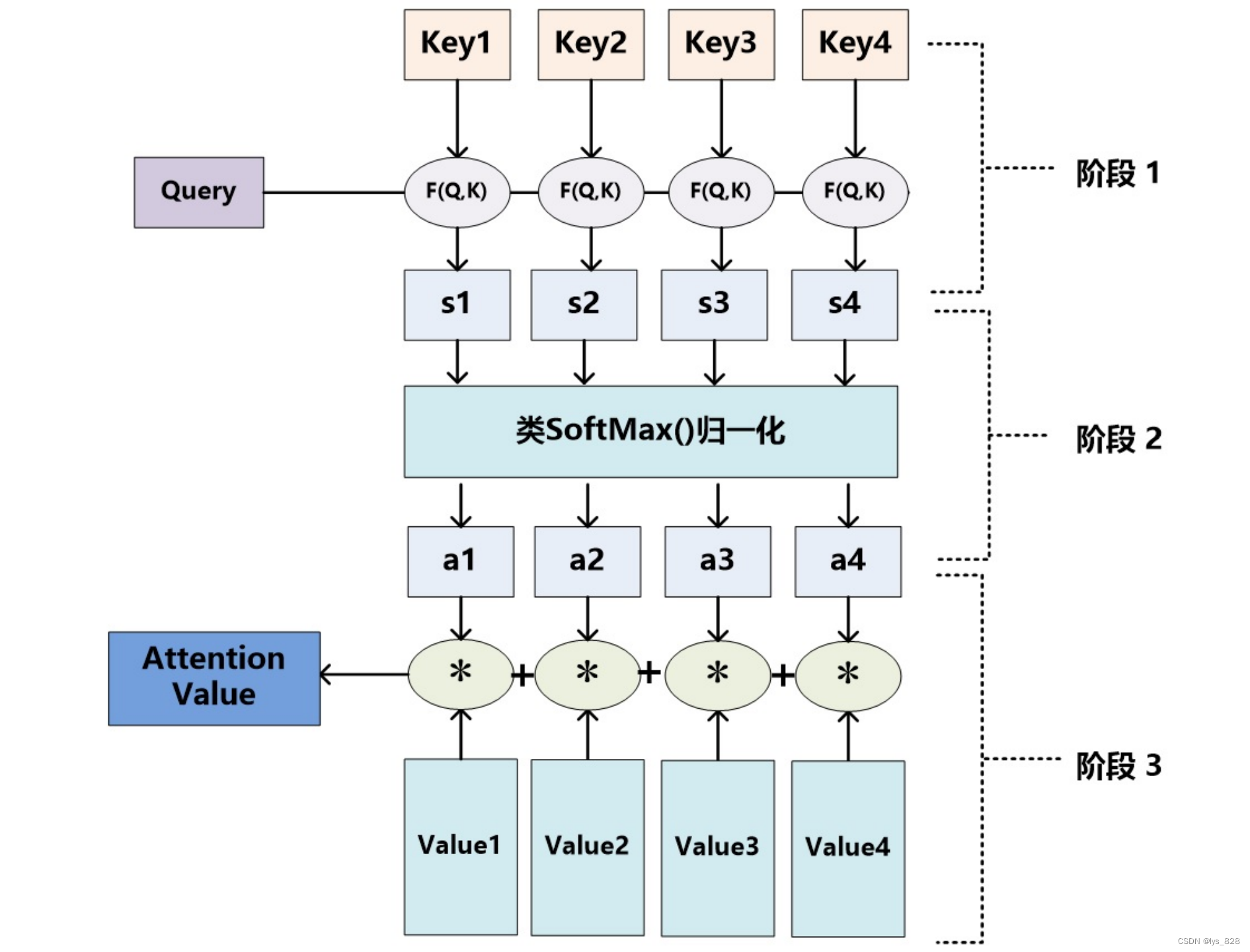
【nlp】2.8 注意力机制拓展
注意力机制拓展 1 注意力机制原理1.1 注意力机制示意图1.2 Attention计算过程1.3 Attention计算逻辑1.4 有无attention模型对比1.4.1 无attention机制的模型1.4.2 有attention机制的模型1 注意力机制原理
1.1 注意力机制示意图
Attention机制的工作原理并不复杂,我们可以用下…
自然语言处理的bert, GPT, GPT-2, transformer, ELMo, attention机制都是些何方神圣???
2018年是NLP领域巨变的一年,这个好像我们都知道,但是究竟是哪里剧变了,哪里突破了?经常听大佬们若无其事地抛出一些高级的概念,你却插不上嘴,隐隐约约知道有这么个东西,刚要开口:噢&…