原论文地址:原论文下载地址
优点:使得网络更容易训练,参数更小且计算更高效
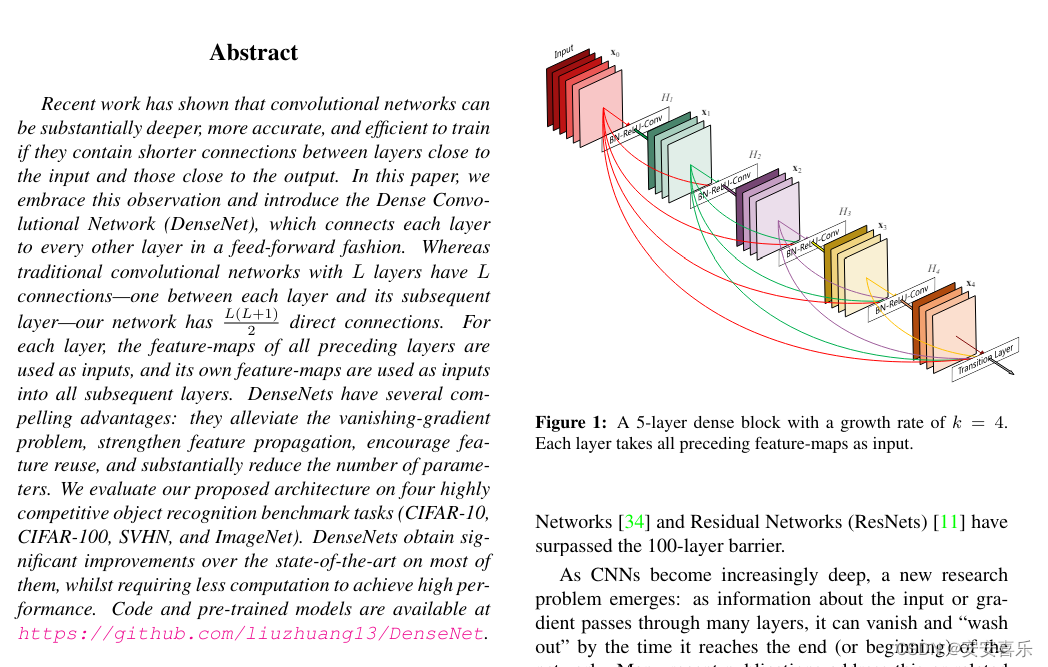
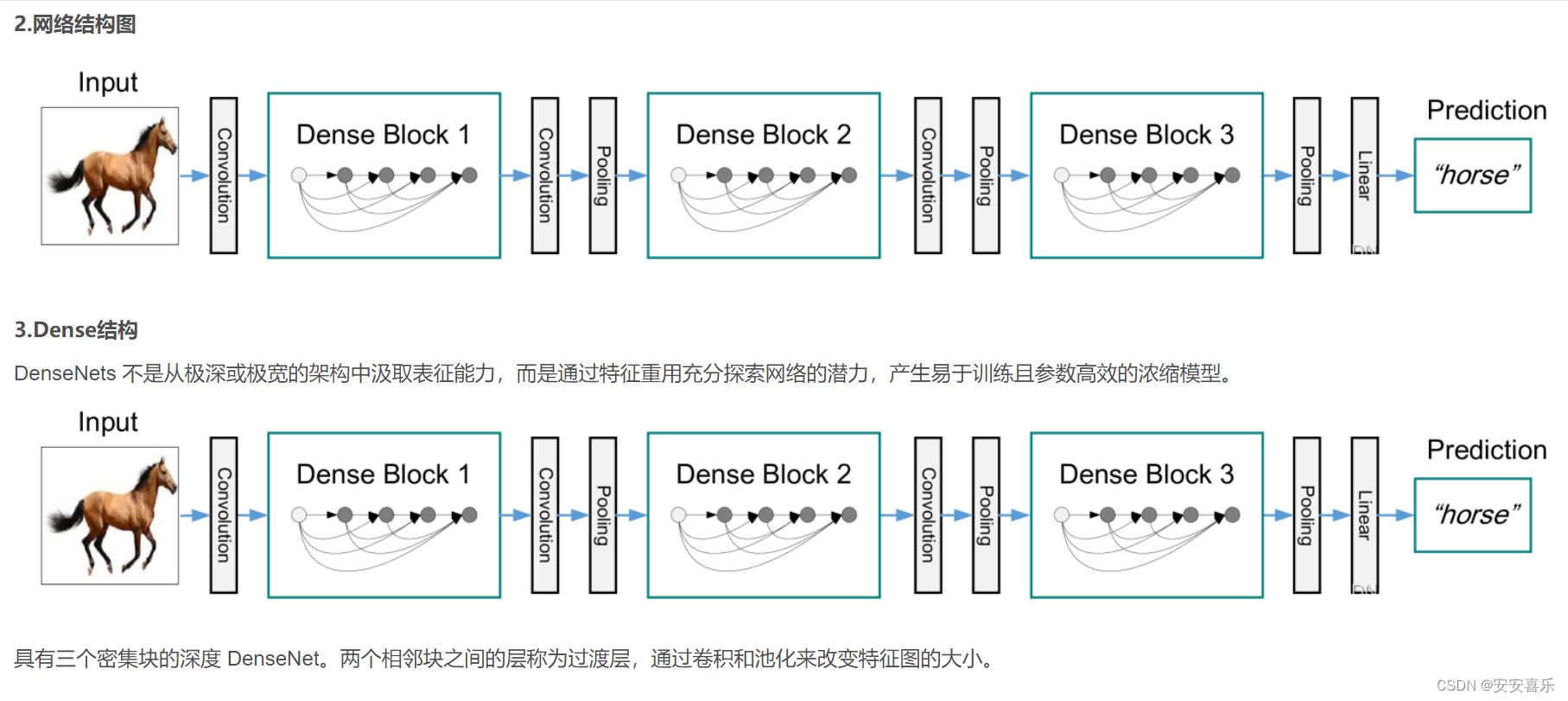
摘要:最近的研究表明,如果卷积网络在靠近输入和接近输出的层之间包含更短的连接,那么卷积网络可以更深入、更准确、更有效地训练。在本文中,我们接受了这一观察结果,并引入了密集卷积网络(DenseNet),它以前馈方式将每一层连接到其他每一层。传统的L层卷积网络有L个连接——每层和后续层之间有一个连接——而我们的网络有L(L+1) 2个直接连接。对于每一层,使用所有前一层的特征映射作为输入,并使用其自身的特征映射作为所有后续层的输入。DenseNets有几个引人注目的优点:它们缓解了梯度消失问题,加强了特征传播,鼓励特征重用,并大大减少了参数的数量。
之前的工作表明,如果卷积网络在靠近输入的层和靠近输出的层之间包含较短的连接,则它们可以更深、更准确和更有效地训练。在本文中,我们接受了这一观察并介绍了密集卷积网络(DenseNet),其中每一层以前馈方式直接连接到其他每一层。而传统的卷积网络L层有L连接,每一层与其后续层之间的连接(将输入视为层),我们的网络有L ( L + 1 )\ 2 )直接连接.


 代码文件:
代码文件:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from torch.jit.annotations import List
from timm.models.layers import BatchNormAct2d
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution iscyy
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class DenseLayer(nn.Module):
def __init__(
self, int_numss, gr, bs, norm_layer=BatchNormAct2d,
drop_rate=0., memory_efficient=False):
super(DenseLayer, self).__init__()
self.add_module('norm1', norm_layer(int_numss)),
self.add_module('conv1', nn.Conv2d(
int_numss, bs * gr, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', norm_layer(bs * gr)),
self.add_module('conv2', nn.Conv2d(
bs * gr, gr, kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bottleneck_fn(self, xs):
concated_features = torch.cat(xs, 1)
bottleneck_output = self.conv1(self.norm1(concated_features)) # noqa: T484
return bottleneck_output
def any_requires_grad(self, x):
for tensor in x:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, x):
def closure(*xs):
return self.bottleneck_fn(xs)
return cp.checkpoint(closure, *x)
@torch.jit._overload_method # mango noqa: F811
def forward(self, x):
pass
@torch.jit._overload_method # noqa: F811
def forward(self, x):
pass
def forward(self, x): # noqa: F811 iscyy/mango
if isinstance(x, torch.Tensor):
prev_features = [x]
else:
prev_features = x
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bottleneck_fn(prev_features)
new_features = self.conv2(self.norm2(bottleneck_output))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self, int_numss, gr, num_layers, bs=4, norm_layer=nn.ReLU,
drop_rate=0., memory_efficient=False):
super(DenseBlock, self).__init__()
for i in range(num_layers):
layer = DenseLayer(
int_numss + i * gr,
gr=gr,
bs=bs,
norm_layer=norm_layer,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class DenseTrans(nn.Sequential):
def __init__(self, int_numss, out_numss, kernel_size, norm_layer=nn.BatchNorm2d, aa_layer=None, act=True):
super(DenseTrans, self).__init__()
self.conv = nn.Conv2d(
int_numss, out_numss, kernel_size=kernel_size, stride=1)
self.bn = nn.BatchNorm2d(out_numss)
self.act = self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class DenseB(nn.Module):
def __init__(self, c1, c2, gr, num_layers=6):
super().__init__()
self.dense = DenseBlock(c1, gr, num_layers)
self.con = DenseTrans(c1 + gr * num_layers, c2, 1 ,1)
def forward(self, x):
x = self.con(self.dense(x))
return x
class DenseC(nn.Module):
def __init__(self, c1, c2, gr, num_layers=6):
super().__init__()
self.dense = DenseBlock(c1, gr, num_layers)
self.con = DenseTrans(c1 + gr * num_layers, c2, 1 ,1)
self.dense2 = DenseBlock(c1, gr, num_layers)
self.con2 = DenseTrans(c1 + gr * num_layers, c2, 1 ,1)
def forward(self, x):
x = self.con(self.dense(x))
x = self.con2(self.dense2(x))
return x
class DenseOne(nn.Module):
def __init__(self, c1, c2, n=1, gr=32, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(DenseB(c_, c_, gr=gr, num_layers=6) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class DenseOneC(nn.Module):
def __init__(self, c1, c2, n=1, gr=32, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(DenseC(c_, c_, gr=gr, num_layers=6) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))