YOLOV8_0">一、YOLOV8环境准备
YOLOv8_1">1.1 下载安装最新的YOLOv8代码
仓库地址: https://github.com/ultralytics/ultralytics
1.2 配置环境
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
1.3 安装labelme标注工具
pip install labelme
二、半自动标注
2.1 下载预训练权重yolov8n.pt
仓库:https://github.com/ultralytics/ultralytics
在YOLOv8 github上下载预训练权重:yolov8n.pt,ultralytics\ultralytics\路径下,新建weights文件夹,预训练权重放入其中。
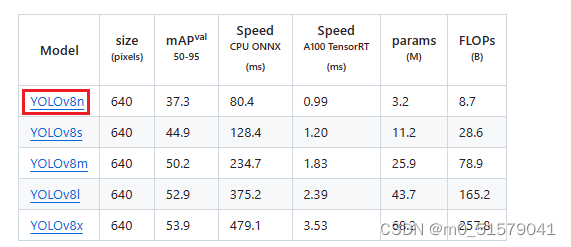
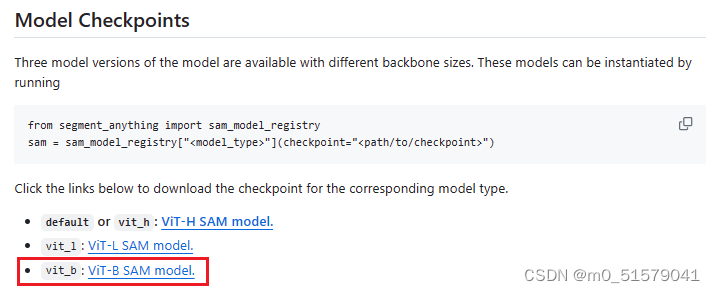
2.2 下载预训练权重ViT-B SAM model
仓库:https://github.com/facebookresearch/segment-anything?tab=readme-ov-file
在SAM github上下载预训练权重:ViT-B SAM model,将下载的权重重命名为sam_b.pt(包括文件后缀),放入ultralytics\ultralytics\weights文件夹,预训练权重放入其中。
2.3 自动标注
执行下面代码:(建议使用绝对路径)
from ultralytics.data.annotator import auto_annotate
auto_annotate(data='D:/study/cnn/yolo/ultralytics/ultralytics/assets', det_model='D:/study/cnn/yolo/ultralytics/weights/yolov8n.pt', sam_model='D:/study/cnn/yolo/ultralytics/weights/sam_b.pt')
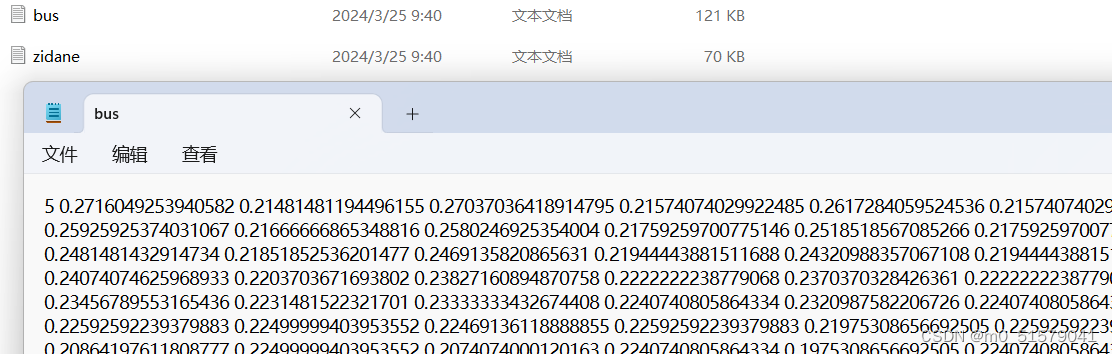
查看ultralytics\assets_auto_annotate_labels路径下,生成的txt格式标签
三、标签文件可视化
3.1 txt标签转json标签
执行下面代码:(建议使用绝对路径)
import torch
import numpy as np
import base64, os
from PIL import Image
import io
import json
def xyn2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
x = [ar.reshape(-1, 2) for ar in x]
return x
def txt2points(txtfile_path):
cls, xywh_list = [], []
with open(txtfile_path, "r") as f:
for line in f.readlines():
line = line.strip('\n').split(' ') # 去掉列表中每一个元素的换行符
cls.append(line[0])
xywh_list.append(line[1:])
return cls, xywh_list
def savejson(points_list, clses_list, img_tmp, filename, save_dir, w, h):
cur_json_dict = {
"version": "5.1.1",
"flags": {},
"shapes": [
],
}
listbigoption = []
for cls, points in zip(clses_list, points_list):
points = np.array(points, dtype=float).reshape(-1, 2)
points[:, 0] = points[:, 0] * w
points[:, 1] = points[:, 1] * h
cur_json_dict['shapes'].append(
{"label": cls, "points": points.tolist(), "group_id": None,
"shape_type": "polygon", "flags": {}})
# A['imageData'] = base64encode_img(img_tmp)
cur_json_dict["imageData"] = None
cur_json_dict["imageHeight"] = h
cur_json_dict["imageWidth"] = w
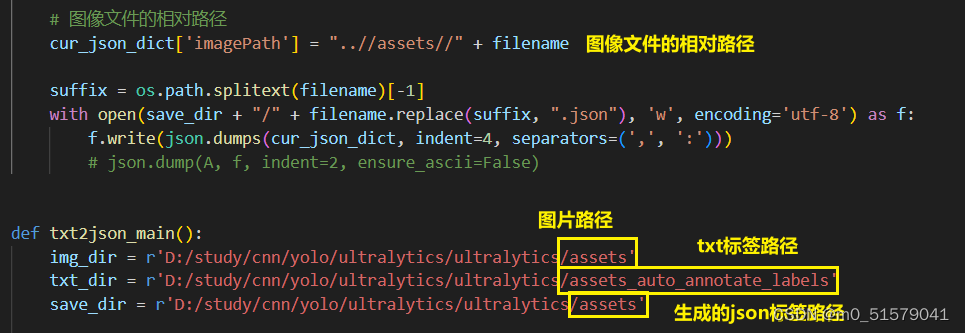
# 图像文件的相对路径
cur_json_dict['imagePath'] = "..//assets//" + filename
suffix = os.path.splitext(filename)[-1]
with open(save_dir + "/" + filename.replace(suffix, ".json"), 'w', encoding='utf-8') as f:
f.write(json.dumps(cur_json_dict, indent=4, separators=(',', ':')))
# json.dump(A, f, indent=2, ensure_ascii=False)
def txt2json_main():
img_dir = r'D:/study/cnn/yolo/ultralytics/ultralytics/assets'
txt_dir = r'D:/study/cnn/yolo/ultralytics/ultralytics/assets_auto_annotate_labels'
save_dir = r'D:/study/cnn/yolo/ultralytics/ultralytics/assets'
for imgfile in os.listdir(img_dir):
print(imgfile)
name, suffix = os.path.splitext(imgfile)
txtfile = imgfile.replace(suffix, '.txt')
txt_path = os.path.join(txt_dir, txtfile)
if not os.path.isfile(txt_path):
continue
img_path = os.path.join(img_dir, imgfile)
img = Image.open(img_path)
w, h = img.size
cls, xyxy = txt2points(txt_path)
# print(cls)
# print(xyxy)
# print()
savejson(xyxy, cls, img, imgfile, save_dir, w, h)
if __name__ == '__main__':
txt2json_main()
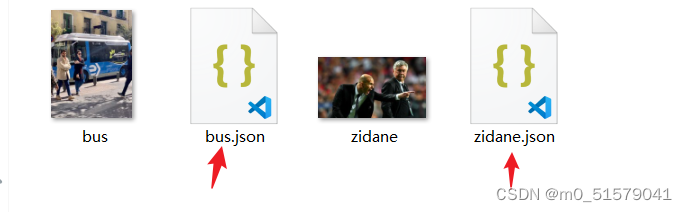
查看生成结果
3.2 使用labelme工具进行可视化