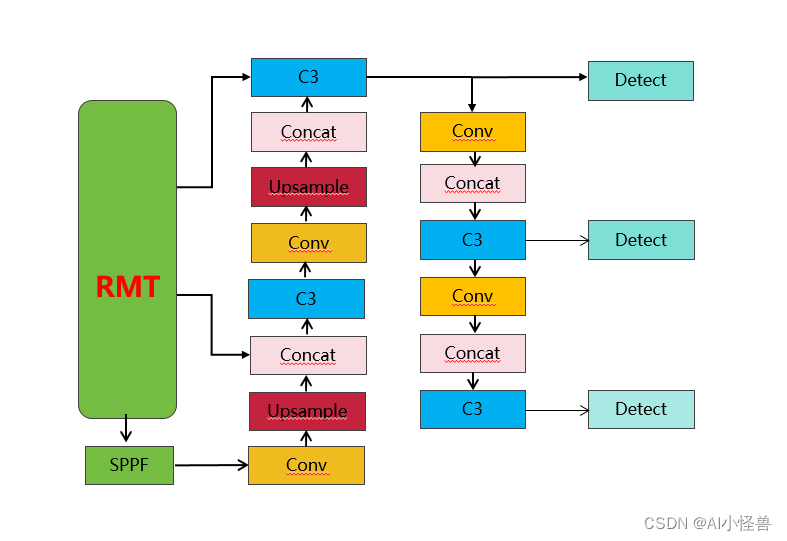
💡💡💡本文独家改进:RMT:一种强大的视觉Backbone,灵活地将显式空间先验集成到具有线性复杂度的视觉主干中,在多个下游任务(分类/检测/分割)上性能表现出色!
💡💡💡Transformer 在各个领域验证了可行性,在多个数据集下能够实现涨点
改进结构图如下:

收录
YOLOv5原创自研
https://blog.csdn.net/m0_63774211/category_12511931.html
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡
💡💡💡本文独家改进:RMT:一种强大的视觉Backbone,灵活地将显式空间先验集成到具有线性复杂度的视觉主干中,在多个下游任务(分类/检测/分割)上性能表现出色!
💡💡💡Transformer 在各个领域验证了可行性,在多个数据集下能够实现涨点
改进结构图如下:
收录
YOLOv5原创自研
https://blog.csdn.net/m0_63774211/category_12511931.html
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡