paper:YOLOX: Exceeding YOLO Series in 2021
official implementation:https://github.com/Megvii-BaseDetection/YOLOX
本文的创新点
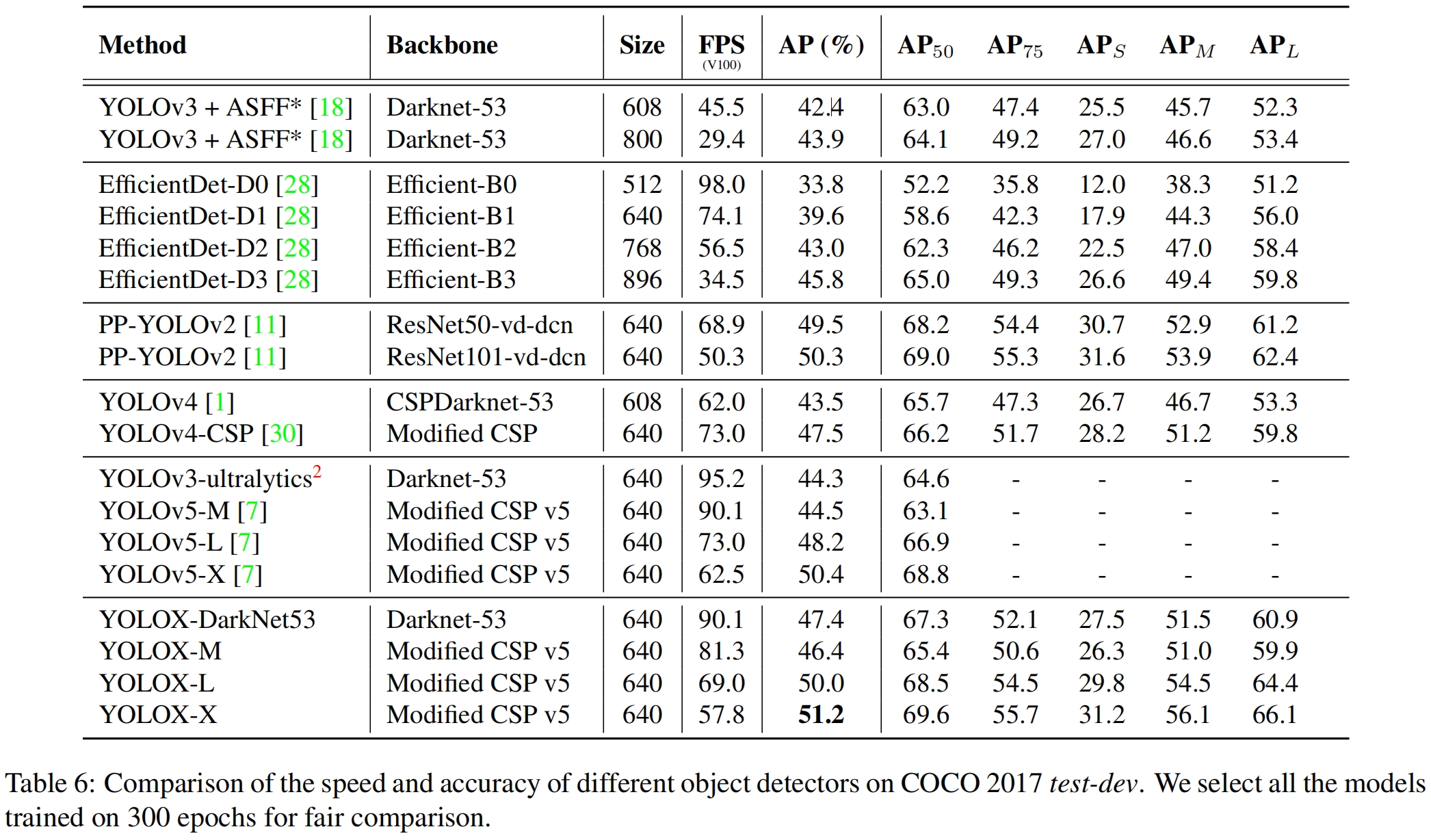
本文在YOLOv3的基础上进行了一些改进:包括将检测头进行解耦的decoupled head、从anchor-based转为anchor-free、标签分配使用OTA的简化版本SimOTA,提出了YOLOX,在large-scale和light-weight模型方面都取得了SOTA的结果,如图1所示。
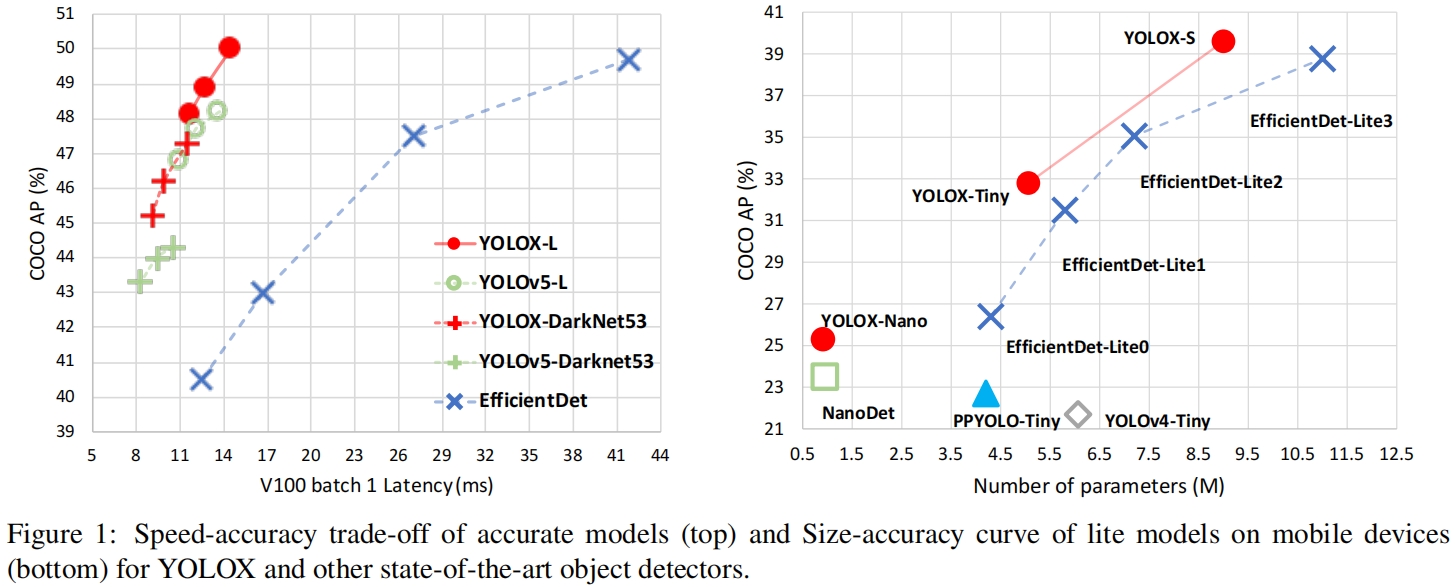
YOLOX
YOLOX-DarkNet53
Implementation details 训练设置从baseline到最终的模型基本是一致的。我们在COCO train2017上总共训练了300个epoch,包括5个epoch的warm-up。优化器选择SGD。使用 \(lr\times Batchsize/64\) 的学习率,初始 \(lr=0.01\) 和cosine lr schedule。weight decay大小为0.0005,SGD momentum为0.9。对于8-GPU的设置,batch size默认为128。输入大小以步长32均匀的从448到832。本文中FPS和lantency都是在Tesla V100上以FP16精度和batch=1进行测量。
YOLO v3 baseline baseline采用DarkNet-53和SPP层的YOLOv3。与原来的实现相比,作者稍微改变了一些训练策略,增加了EMA权重更新、余弦学习衰减策略、IoU损失和IoU-aware分支。用BCE loss训练 \(cls\) 和 \(obj\) 分支,用IoU loss训练 \(reg\) 分支。这些通用的训练技巧与YOLOX的关键改进是orthogonal的关系,因此把它们放到了baseline上。此外,我们只进行随机水平翻转RandomHorizontalFlip、颜色抖动ColorJitter和多尺度multi-scale的数据增强,并丢弃了RandomResizedCrop,因为作者发现RandomResizedCrop和mosaic增强有一些重叠。通过这些增强,baseline在COCO val上得到了38.5% AP,如表2所示。
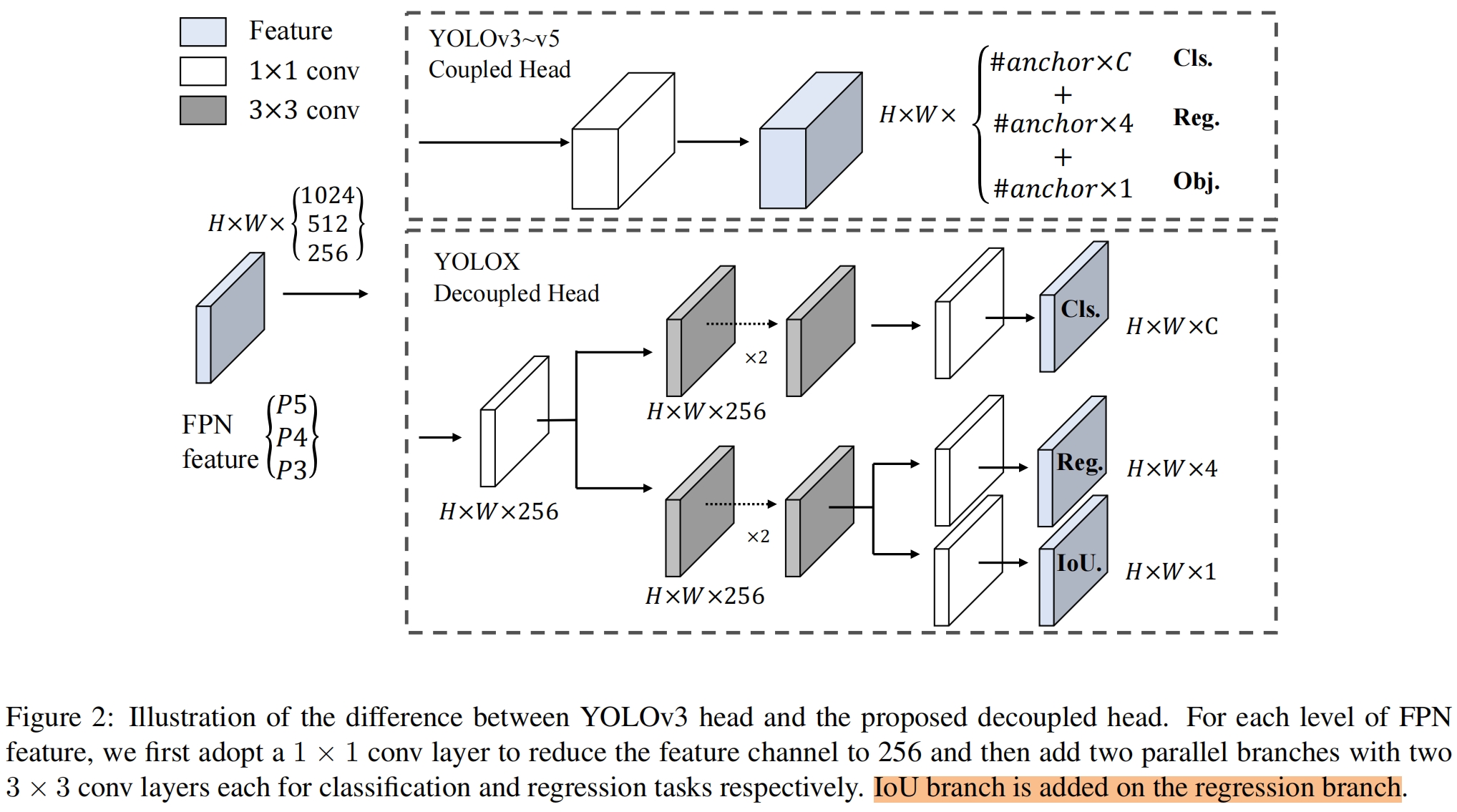
Decoupled head 在目标检测中,分类和回归任务之间的conflit是一个众所周知的问题,因此解耦头decoupled head被广泛用于大多数one-stage和two-stage检测模型中。但YOLO系列骨干网络和特征金字塔不断进化,检测头却仍然是coupled,如图2所示。
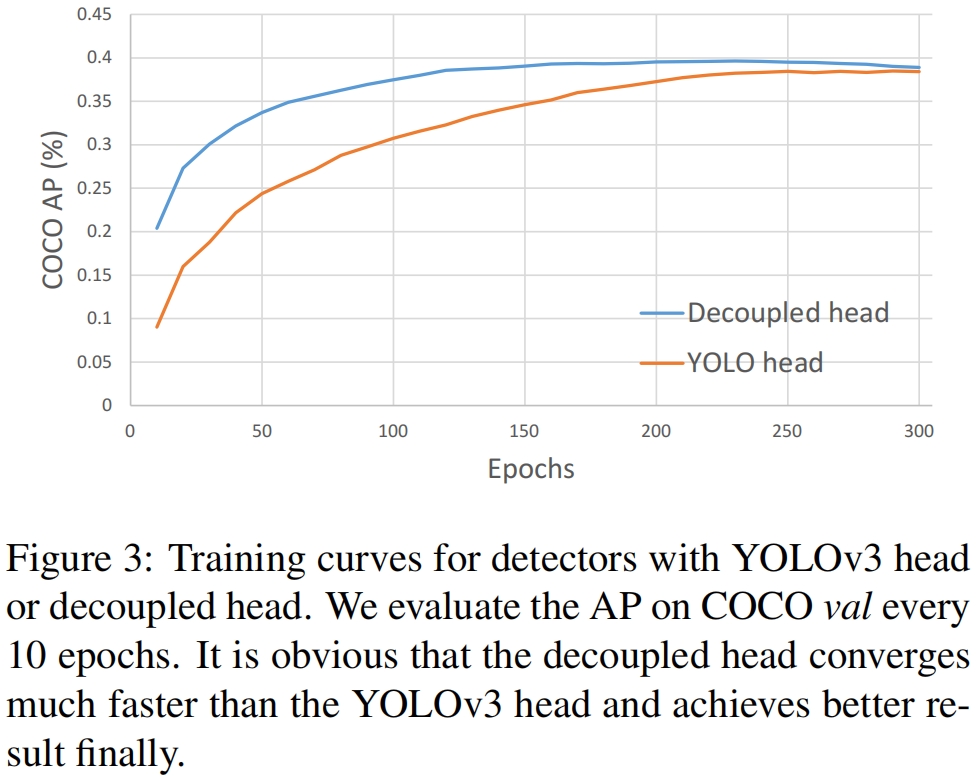
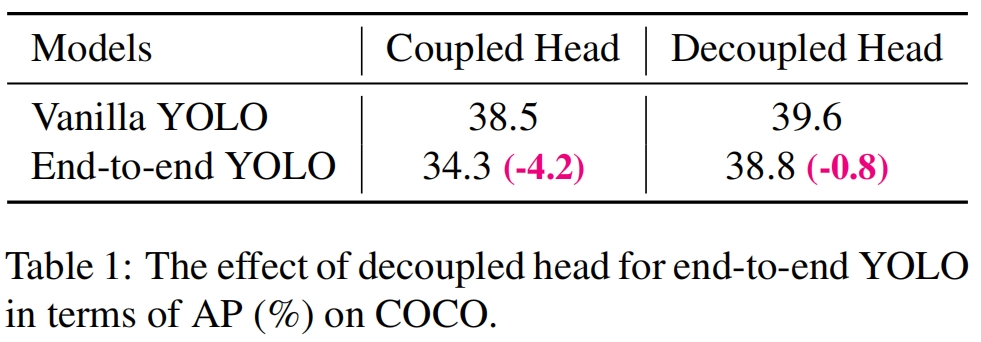
两个分析实验表明coupled head可能会损害性能。1)用decoupled head代替coupled head,大大提高了收敛速度,如图3所示。2)decoupled head对end-to-end版本的YOLO至关重要(后面会详述)。
从表1可以看出,耦合头的端到端版本AP下降了4.2,而解耦头只下降了0.8。因此我们将coupled head换成了decoupled head,如图2所示。具体而言,它包含一个1x1卷积层用来降低通道维度,两个平行分支中各有两个3x3卷积层。从表2可以看出,decoupled head带来了额外1.1ms的推理时间(11.6ms v.s. 10.5ms)。
Strong data augmentation 我们添加了Mosaic和MixUp到数据增强策略中来提高YOLOX的性能。Mosaic是ultralytics-YOLOv3提出的一种有效的数据增强策略,后续被广泛用于YOLOv4、YOLOv5和其它检测模型中。MixUp最初是为图像分类设计的,后来在BoF中修改用于目标检测训练。在我们的模型中,我们使用了Mosaic和MixUp,并在最后15个epoch关闭它们,得到了42%的AP,如表2所示。在使用了更强的数据增强后,我们发现ImageNet预训练不再有用,因此接下来的模型我们全部都从头训练。
Anchor-free YOLOv4和YOLOv5都遵循了YOLOv3最初基于anchor的pipeline。然而,anchor机制存在许多问题。首先,为了达到最优检测性能,需要在训练前进行聚类分析以确定一组最优anchor,这些anchor是特定于领域的并且泛化性较差。其次,anchor机制增加了检测head的复杂性以及每张图片的预测数量。在一些边缘AI系统中,在设备之间(例如从NPU到CPU)移动如此大量的预测可能成为总体延迟的潜在瓶颈。
Anchor-free机制在过去两年发展迅速,这些工作表明,anchor-free检测模型的性能可以达到anchor-based模型的相同水平。Anchor-free机制显著减少了为了获得好的性能需要的启发式调优和相关trick的设计参数(比如Anchor Clustering, Grid Sensitive),使得检测模型,特别是训练和解码阶段变得非常简洁。
将YOLO转换到anchor-free的方式非常简单,我们将每个位置的预测数量从3减为1,并直接预测四个值,即相对网格左上角的两个偏移和预测框的宽高。我们将每个对象的中心位置指定为正样本,并像FCOS一样预先定义一个尺度范围来指定每个对象所属的FPN层级。这种修改减少了检测模型的参数和GFLOPs使其更快,并取得了更高的性能 - 42.9% AP,如表2所示。
Multi positives 为了和YOLOv3的分配规则一致,上述anchor-free的版本只为每个对象分配了一个正样本(中心位置),但同时忽略了其它高质量的预测。但是,优化这些高质量的预测也会带来有益的梯度,这可能会缓解训练过程中正负样本的极端不平衡。因此我们将中心3x3区域分配为正样本,这在FCOS中被称为"center sampling"。如图2所示,检测模型的性能提升到了45.0% AP,已经超越了目前最好的ultralytics-YOLOv3(44.3% AP)。
SimOTA 先进的标签分配方法是近年来目标检测领域的另一项重要进展。基于我们自研的OTA,我们总结了先进标签分配的四个关键点:1)loss/quality aware 损失/质量感知的,2)center prior 中心先验,3)每个ground-truth动态的positive anchor数量(简写为动态top-k),4)global view 全局视野。OTA同时满足了上述四条,因此我们选择它作为候选标签分配策略。关于OTA的具体介绍见OTA: Optimal Transport Assignment for Object Detection 原理与代码解读-CSDN博客
具体来说,OTA从全局角度来分析标签分配,并将分配过程定义为一个最优传输问题(Optimal Transport, OT),在现有的分配策略中取得了SOTA的性能。但是我们发现通过Sinkhorn-Knopp算法解决OT问题导致训练时长增加了25%,对于训练300个epoch来说代价很大。因此我们将其简化为动态top-k策略,成为SimOTA,以得到一个近似解。
SimOTA首先计算每对prediction-gt的匹配程度,即cost。SimOTA中,gt \(g_{i}\) 和预测 \(p_j\) 之间的cost计算如下
![]()
其中 \(\lambda\) 是平衡系数,\(L_{ij}^{cls}\) 和 \(L_{ij}^{reg}\) 分别是 \(g_{i}\) 和 \(p_j\) 的分类损失和回归损失。然后对于 \(g_{i}\),我们在一个固定的中心区域内选择cost最小的 \(k\) 个预测作为它的正样本。最后,这些positive预测对应的网格grid划分为正样本,其余的grid作为负样本。注意对于不同ground-truth,\(k\) 值也不同,具体可以参考OTA中的Dynamic \(k\) Estimation策略。
SimOTA不仅减少了训练时间,而且避免了inkhorn-Knopp算法中额外的超参。如表2所示,SimOTA将模型的AP从45.0%提升到47.3%,比SOTA的ultralytics-YOLOv3高了3.0%,显示出了先进标签分配策略的作用。
End-to-end YOLO 作者遵循《Object detection made simpler by eliminating heuristic nms》的方法额外添加了两个卷积层,一对一的标签分配,停止梯度。这使模型可以端到端的执行检测,但会略微降低性能和推理速度,如表2所示。作者这里将它作为一个可选的模块,并不包含在最终的模型中。
Other Backbones
除了DarkNet53,作者还在其它不同大小的backbone上测试了YOLOX,都得到了提升。
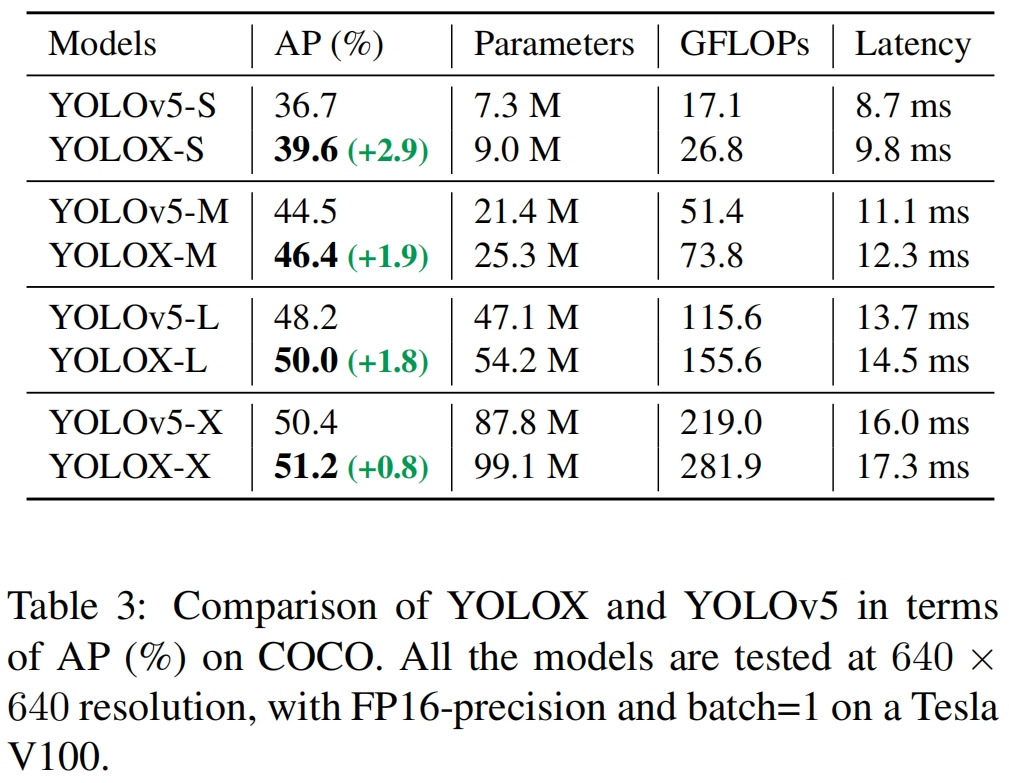
Modified CSPNet in YOLOv5 为了公平比较,我们采用了YOLOv5的backbone,包括改进的CSPNet,SiLU激活,和PAN检测头。我们还仿照其缩放规则得到了YOLOX-S,YOLOX-M,YOLOX-L和YOLOX-X。如表3所示,和YOLOv5相比,我们的模型得到了一致的提升,~3.0%到~1.0%,只增加了少量的时间(来自于decoupled head)。
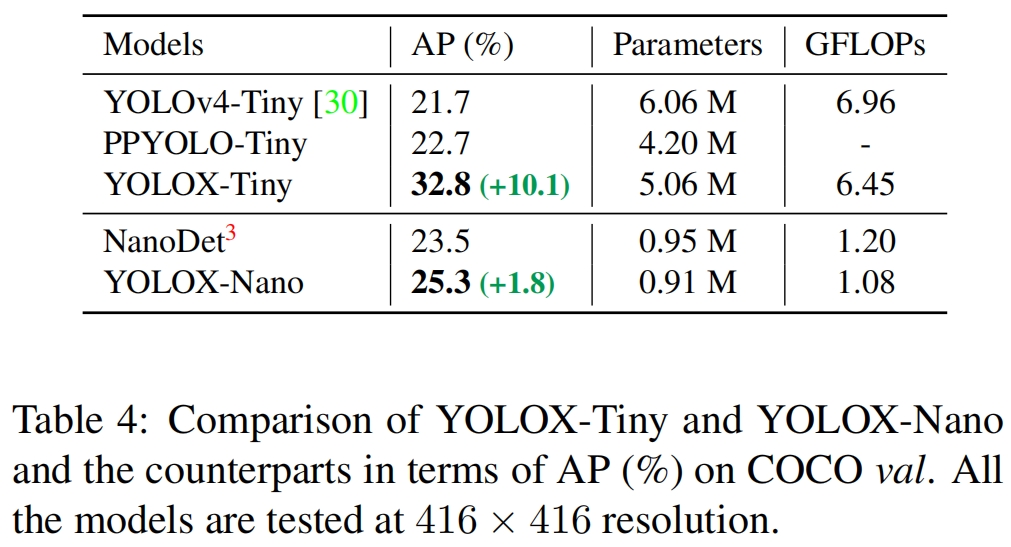
Tiny and Nano Detectors 我们进一步缩小得到了YOLOX-Tiny从而可以和YOLOv4-Tiny进行比较。对于移动设备,我们采用深度构建了YOLOX-Nano,该模型只有0.91M的参数和1.08G的FLOPs。如表4所示,YOLOX在更小的模型上也表现良好。
Model size and data augmentation 在我们的实验中,所有的模型都使用了相同的learning schedule和优化参数。但我们发现,对不同大小的模型,合适的数据增强策略也不同。如表5所示,对YOLOX-L应用MixUp可以提高0.9% AP,对小模型最好减小数据增强的强度。具体来说,当训练小模型(YOLOX-S, YOLOX-Tiny, YOLOX-Nano)时,我们去掉了mix-up并削弱了mosaic(尺度范围从[0.1, 2.0]变成[0.5, 1.5])。这将YOLOX-Nano的AP从24.0%提高到了25.3%。
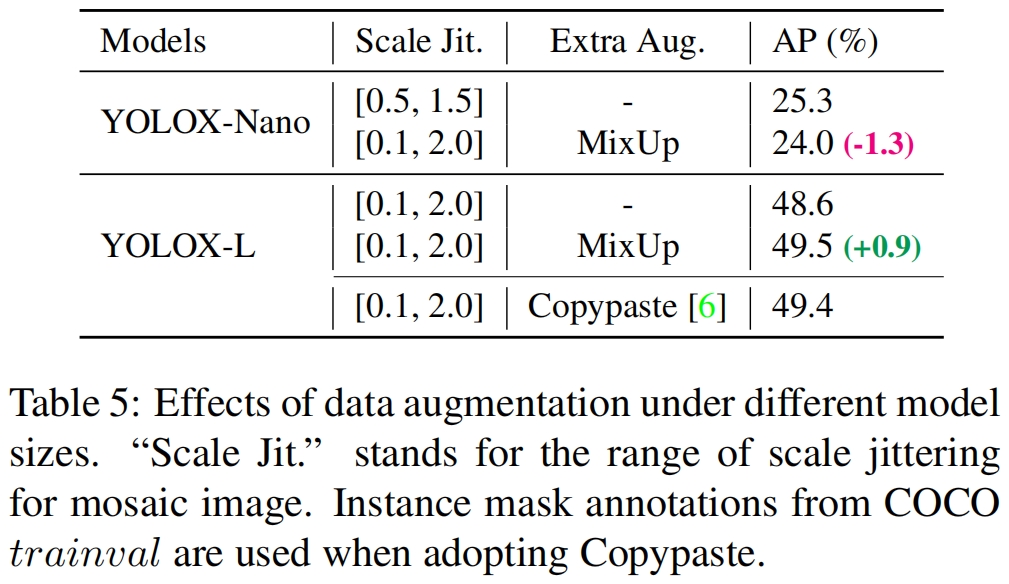
对于大模型,我们发现更强的数据增强更有帮助。实际上,我们的MixUp实现比原始实现heavier一些。受Copypaste(具体介绍见Copy-Paste(CVPR 2021)原理与代码解析-CSDN博客)的启发,在mixup之前,我们对两张图片都进行了抖动,抖动的比例因子是随机采样的。为了理解Mixup结合scale jittering的表现,我们将其与YOLOX-L上的Copypaste进行比较,注意到Copypaste需要额外的instance mask标注而MixUp不需要。但如表5所示,这两种方法获得了差不多的精度,表明当没有实例掩码标注时,MixUp结合scale jittering是CopyPaste的合格替代品。
Comparision with the SOTA