目录
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
原理
遍历所有分组
高级剪枝器
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
http://t.csdnimg.cn/sVHxv
原理
传统剪枝方法的缺陷
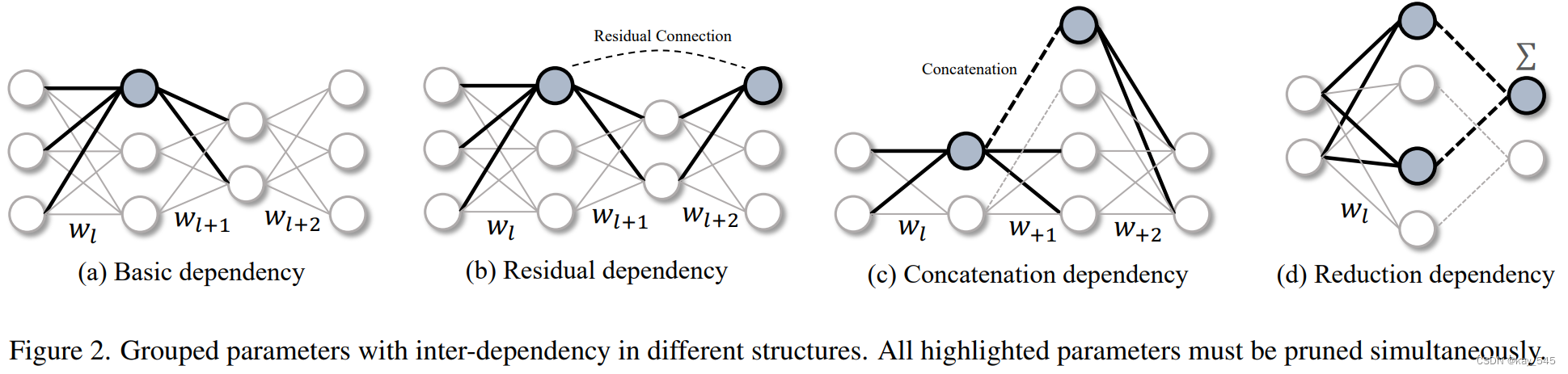
在复杂的网络结构中, 参数之间可能存在依赖关系, 这种依赖要求算法对这类参数进行同步移除以保证结构正确性,这就涉及到耦合参数的分组问题. 我们的工作通过提供一种自动化机制来对参数进行分组. 具体而言, Torch-Pruning使用伪输入来运 行模型, 跟踪网络计算图, 并记录层之间的依赖关系. 当剪枝某一层时, Torch-Pruning会识别所有耦合层, 并返回包含这些耦合信息的tp.Group.
一种通用的结构化剪枝框架DepGraph(Dependency Graph),可以应用于任意类型的神经网络架构(包括CNN、RNN、GNN和Transformer等)进行结构化剪枝。主要原理如下:
1. 神经网络内部存在着层与层之间的依赖关系,需要同时剪枝依赖的层组,否则会破坏网络结构。
2. 结构化剪枝的优势
结构化剪枝的做法是,找到网络中相互依赖的层组,把整个层组同时全部保留或全部删除,从而保证网络结构的完整性。这种做法虽然灵活性较低,但可以有效避免了网络结构被破坏的问题。
3. DepGraph通过建模层与层之间的依赖关系,明确每一层所属的层组。具体分为两种依赖关系:
a) 层间依赖(Inter-layer Dependency): 相邻连接的层之间存在依赖 层间不依赖:resnet
b) 层内依赖(Intra-layer Dependency): 同一层的输入和输出具有相同的剪枝方式时存在依赖 层内不依赖:没有共享权重的
4. 通过图遍历算法在DepGraph上找到最大连接分量作为层组,实现自动化的层组划分。总的来说,DepGraph解决了之前结构化剪枝算法依赖人工设计层组划分规则、缺乏通用性的问题,提出了一种自动建模层组依赖关系和组级剪枝重要性评估的通用框架。
5. DepGraph的工作原理
以ResNet的基本模块为例,如果要删除某个卷积层的滤波器核,由于残差连接的存在,我们必须同时删除该模块中所有层(BN层、ReLU层等)对应的通道。DepGraph通过建模层与层之间的依赖关系,自动将这些相互依赖的层划分到同一个层组中。在剪枝时,整个层组被统一评分,决定是完全保留还是完全删除,从而实现安全的结构化剪枝。
import torch
from torchvision.models import resnet18
import torch_pruning as tp
model = resnet18(pretrained=True).eval()
# 1. 构建依赖图
DG = tp.DependencyGraph()
DG.build_dependency(model, example_inputs=torch.randn(1,3,224,224))
# 2. 指定剪枝的通道维度
pruning_idxs = [2, 6, 9]
pruning_group = DG.get_pruning_group( model.conv1, tp.prune_conv_out_channels, idxs=pruning_idxs )
print(pruning_group.details()) # or print(pruning_group)
# 3. 检查剩余通道数是否<=0, 并执行剪枝
if DG.check_pruning_group(pruning_group):
pruning_group.prune()这个例子演示了使用 DepGraph剪枝的基本流程, resnet.conv1实际上会与多个层耦合在一起.通过打印返回的组, 可以看到组内各个层之间的剪枝是如何互相“触发”的.在以下输出中, “A => B”表示剪枝操作“A”触发剪枝操作“B”.group[0]是用户在DG.get_pruning_group中给出的剪枝操作.

--------------------------------
Pruning Group
--------------------------------
[0] prune_out_channels on conv1 (Conv2d(3, 61, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)) => prune_out_channels on conv1 (Conv2d(3, 61, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)), #idxs=3
[1] prune_out_channels on conv1 (Conv2d(3, 61, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)) => prune_out_channels on bn1 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), #idxs=3
[2] prune_out_channels on bn1 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)) => prune_out_channels on _ElementWiseOp_20(ReluBackward0), #idxs=3
[3] prune_out_channels on _ElementWiseOp_20(ReluBackward0) => prune_out_channels on _ElementWiseOp_19(MaxPool2DWithIndicesBackward0), #idxs=3
[4] prune_out_channels on _ElementWiseOp_19(MaxPool2DWithIndicesBackward0) => prune_out_channels on _ElementWiseOp_18(AddBackward0), #idxs=3
[5] prune_out_channels on _ElementWiseOp_19(MaxPool2DWithIndicesBackward0) => prune_in_channels on layer1.0.conv1 (Conv2d(61, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), #idxs=3
[6] prune_out_channels on _ElementWiseOp_18(AddBackward0) => prune_out_channels on layer1.0.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), #idxs=3
[7] prune_out_channels on _ElementWiseOp_18(AddBackward0) => prune_out_channels on _ElementWiseOp_17(ReluBackward0), #idxs=3
[8] prune_out_channels on _ElementWiseOp_17(ReluBackward0) => prune_out_channels on _ElementWiseOp_16(AddBackward0), #idxs=3
[9] prune_out_channels on _ElementWiseOp_17(ReluBackward0) => prune_in_channels on layer1.1.conv1 (Conv2d(61, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), #idxs=3
[10] prune_out_channels on _ElementWiseOp_16(AddBackward0) => prune_out_channels on layer1.1.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), #idxs=3
[11] prune_out_channels on _ElementWiseOp_16(AddBackward0) => prune_out_channels on _ElementWiseOp_15(ReluBackward0), #idxs=3
[12] prune_out_channels on _ElementWiseOp_15(ReluBackward0) => prune_in_channels on layer2.0.downsample.0 (Conv2d(61, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)), #idxs=3
[13] prune_out_channels on _ElementWiseOp_15(ReluBackward0) => prune_in_channels on layer2.0.conv1 (Conv2d(61, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)), #idxs=3
[14] prune_out_channels on layer1.1.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)) => prune_out_channels on layer1.1.conv2 (Conv2d(64, 61, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), #idxs=3
[15] prune_out_channels on layer1.0.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)) => prune_out_channels on layer1.0.conv2 (Conv2d(64, 61, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), #idxs=3
--------------------------------遍历所有分组
可以利用DG.get_all_groups(ignored_layers, root_module_types)来按顺序扫描所有的分组. 每个分组都会以一个"root_module_types"中所指定的层作为起点. 默认情况下, 这些组包含了完整的剪枝索引idxs=[0,1,2,3,...,K], 这个索引列表包含了所有的可修剪参数的索引. 如果我们希望对一个group进行剪枝, 我们需要使用group.prune(idxs=idxs)来指定具体的修剪通道/维度.
for group in DG.get_all_groups(ignored_layers=[model.conv1], root_module_types=[nn.Conv2d, nn.Linear]):
# handle groups in sequential order
idxs = [2,4,6] # your pruning indices
group.prune(idxs=idxs)
print(group)高级剪枝器
import torch
from torchvision.models import resnet18
import torch_pruning as tp
model = resnet18(pretrained=True)
# 重要性指标
example_inputs = torch.randn(1, 3, 224, 224)
imp = tp.importance.MagnitudeImportance(p=2) # p=2表示使用L2正则,对每个group中的每个层的权值,独立的计算重要性 重要性如何计算??什么是重要的?值大还是小?是损失吗
ignored_layers = []
for m in model.modules():
if isinstance(m, torch.nn.Linear) and m.out_features == 1000:
ignored_layers.append(m) # DO NOT prune the final classifier!
iterative_steps = 5 # 迭代式剪枝, 该示例会分五步完成50%通道剪枝 (10%->20%->...->50%)
pruner = tp.pruner.MagnitudePruner(
model,
example_inputs,
importance=imp,
iterative_steps=iterative_steps,
pruning_ratio=0.5, # 整体移除50%通道, ResNet18 = {64, 128, 256, 512} => ResNet18_Half = {32, 64, 128, 256}
ignored_layers=ignored_layers,
)
base_macs, base_nparams = tp.utils.count_ops_and_params(model, example_inputs)
for i in range(iterative_steps):
pruner.step()
macs, nparams = tp.utils.count_ops_and_params(model, example_inputs)