目录
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
摘要
PGI&GELAN
代码实现
实验结果
消融实验
可视化
结论
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
http://t.csdnimg.cn/sVHxv

摘要
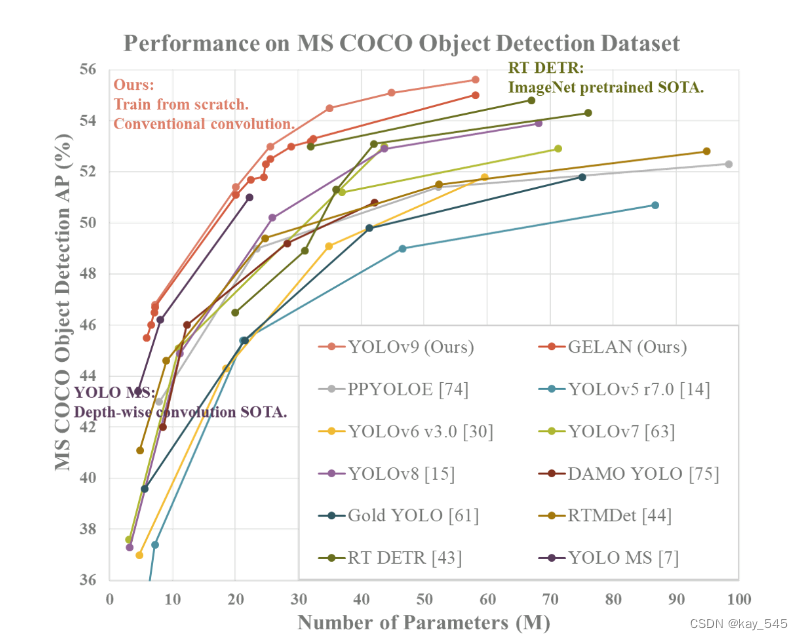
如今的深度学习方法主要关注如何设计最合适的目标函数,使模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。本文将深入研究数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。我们提出了可编程梯度信息(PGI)的概念来应对深度网络实现多个目标所需的各种变化。 PGI可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,还设计了一种基于梯度路径规划的新型轻量级网络架构——通用高效层聚合网络(GELAN)。 GELAN的架构证实了PGI在轻量级模型上取得了优异的结果。我们在基于 MS COCO 数据集的目标检测上验证了所提出的 GELAN 和 PGI。结果表明,与基于深度卷积开发的最先进方法相比,GELAN 仅使用传统的卷积算子即可实现更好的参数利用率。 PGI 可用于从轻型到大型的各种模型。它可以用来获取完整的信息,使得train-fromscratch模型能够比使用大数据集预训练的state-of-theart模型获得更好的结果,比较结果如图所示。
PGI&GELAN
在深度神经网络中,存在一个普遍现象被称为信息瓶颈,即在前馈过程中导致输入数据丢失信息。为了缓解这一问题,目前采用了几种主要方法。首先是可逆架构的使用,通过使用重复的输入数据并显式地维护输入数据的信息来缓解信息丢失。其次是采用masked建模,利用重构损失隐式地最大化特征提取并保留输入信息。第三种方法是引入深度监督概念,利用浅层特征在训练过程中建立从特征到目标的映射,以确保重要信息传递到更深层次。然而,这些方法在训练和推理过程中都存在不同的缺陷。可逆架构增加了推理成本,掩模建模中的重建损失有时与目标损失相冲突,并且与数据不正确关联。深层监督机制可能导致误差累积,特别是在训练过程中浅层监督丢失信息的情况下。这些问题在困难任务和小模型上尤为显着。
为了解决上述问题,我们提出了一个新的概念,即可编程梯度信息(PGI)。其概念是通过辅助可逆分支生成可靠的梯度,使得深层特征仍然能够保持执行目标任务的关键特征。辅助可逆分支的设计可以避免传统的融合多路径特征的深度监督过程可能造成的语义损失。换句话说,我们在不同语义层面上编程梯度信息传播,从而达到最佳的训练结果。 PGI的可逆架构建立在辅助分支上,因此没有额外的成本。由于PGI可以自由选择适合目标任务的损失函数,因此也克服了掩模建模遇到的问题。所提出的PGI机制可以应用于各种规模的深度神经网络,并且比仅适用于非常深的神经网络的深度监督机制更通用.
我们还基于ELAN设计了广义ELAN(GELAN),GELAN的设计同时考虑了参数数量、计算复杂度、准确性和推理速度。这种设计允许用户针对不同的推理设备任意选择合适的计算块。我们将提出的PGI和GELAN结合起来,然后设计了新一代YOLO系列物体检测系统,我们称之为YOLOv9。我们使用MS COCO数据集进行实验,实验结果验证了我们提出的YOLOv9在所有比较中都取得了顶尖的性能。
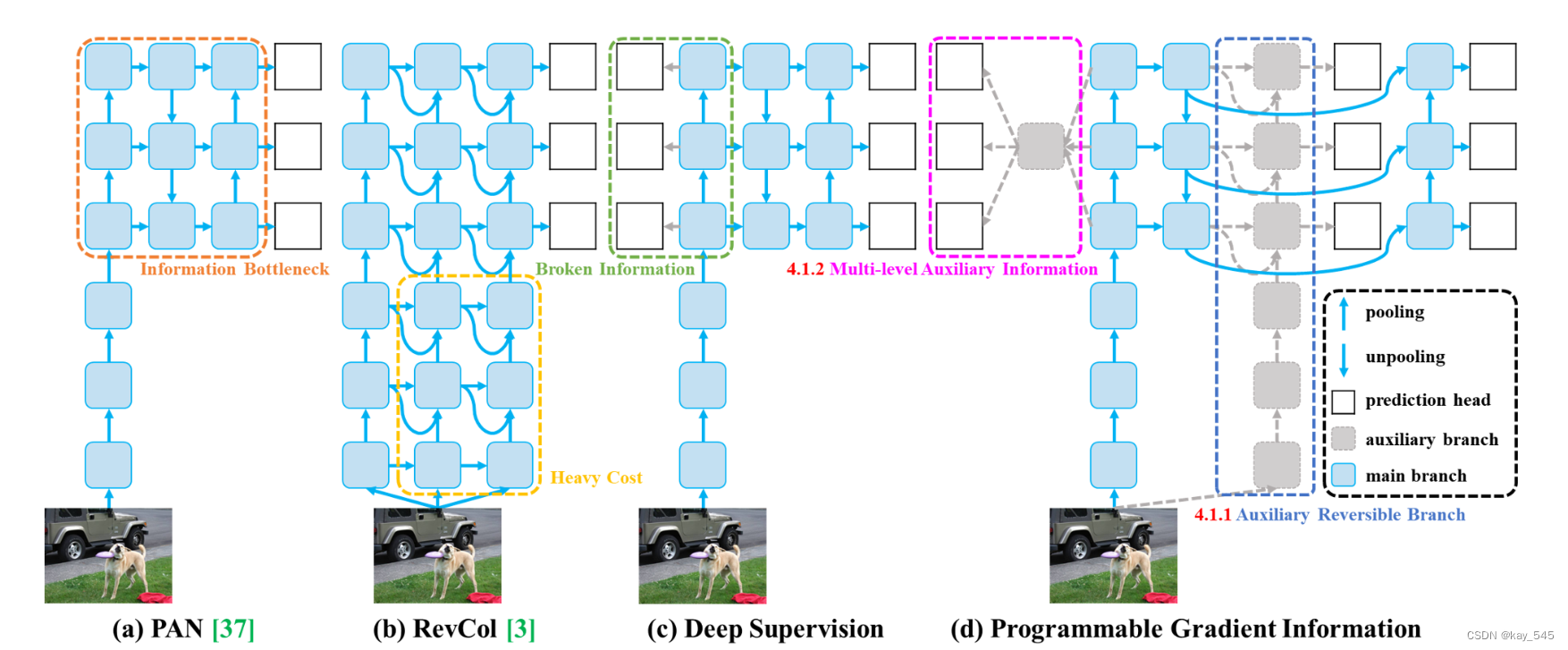
(a)路径聚合网络(PAN))
(b)可逆列(RevCol)
(c)传统深度监督
(d)我们提出的可编程梯度信息(PGI)。
PGI主要由三个部分组成:
(1)主分支:用于推理的架构,(2)辅助可逆分支:生成可靠的梯度,为主分支提供向后传输,(3)多级辅助信息:控制主分支学习可规划的多层次语义信息。
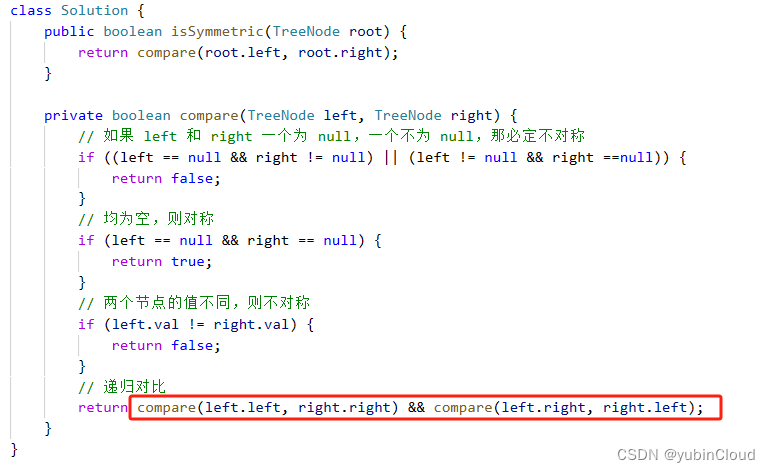
代码实现
class SPPELAN(nn.Module):
# spp-elan
def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = SP(5)
self.cv3 = SP(5)
self.cv4 = SP(5)
self.cv5 = Conv(4*c3, c2, 1, 1)
def forward(self, x):
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.cv5(torch.cat(y, 1))
class RepNCSPELAN4(nn.Module):
# csp-elan
def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3//2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3+(2*c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
class RepConvN(nn.Module):
"""RepConv is a basic rep-style block, including training and deploy status
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process"""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process"""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _avg_to_3x3_tensor(self, avgp):
channels = self.c1
groups = self.g
kernel_size = avgp.kernel_size
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')实验结果
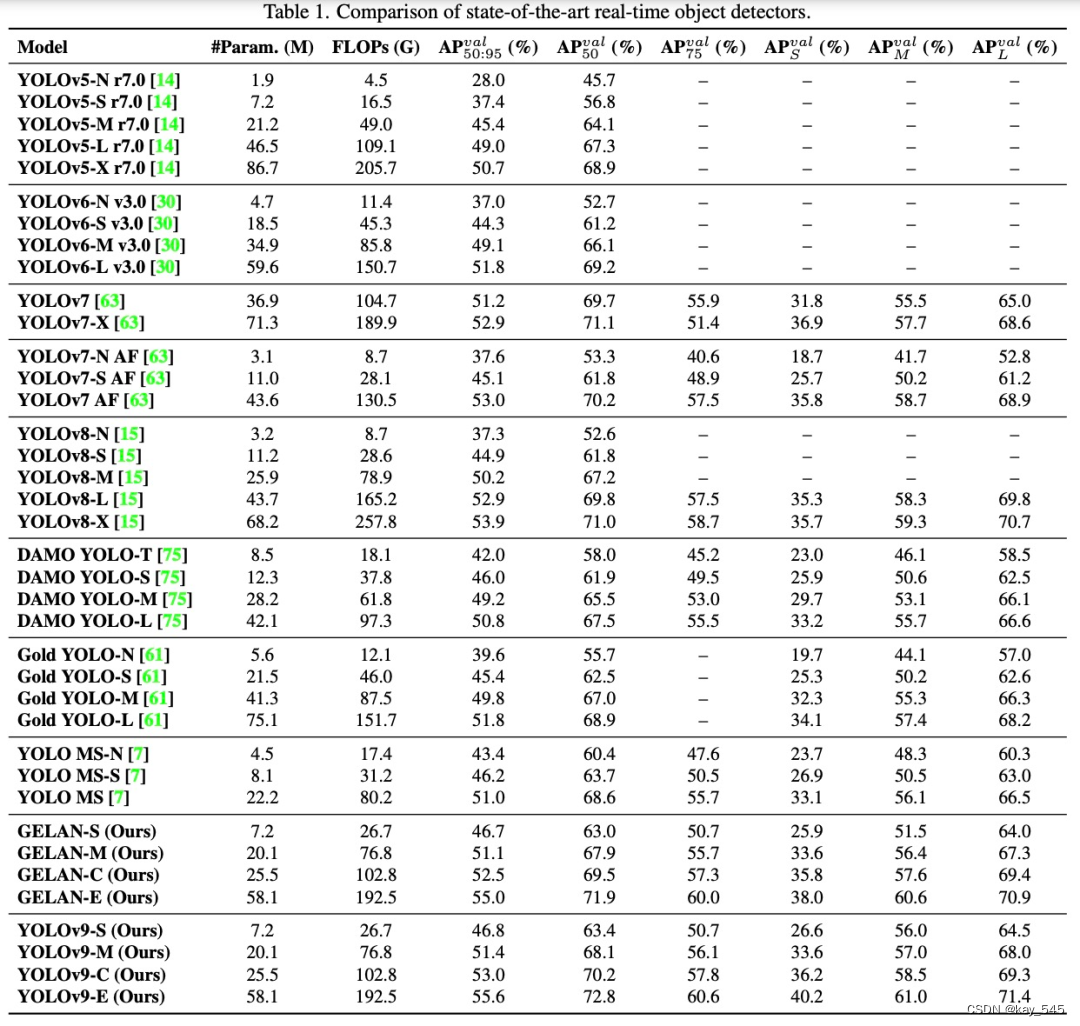
为了评估 YOLOv9 的性能,该研究首先将 YOLOv9 与其他从头开始训练的实时目标检测器进行了全面的比较,结果如下表所示。
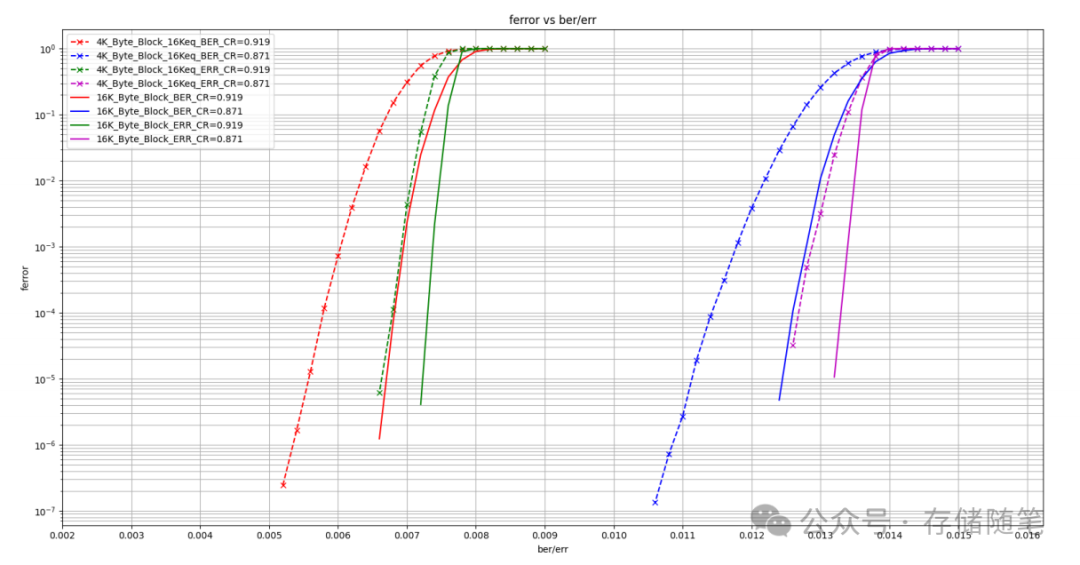
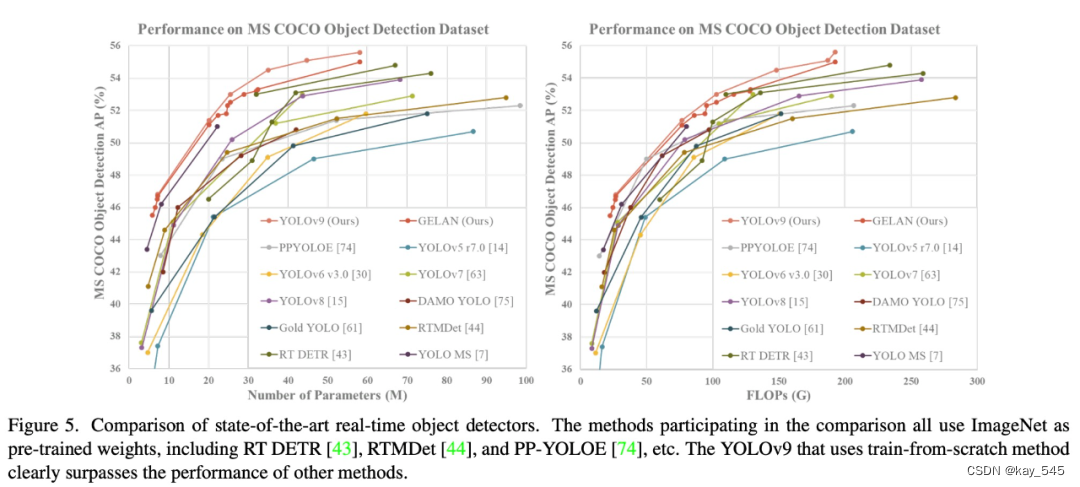
该研究还将 ImageNet 预训练模型纳入比较中,结果如下图 所示。值得注意的是,使用传统卷积的 YOLOv9 在参数利用率上甚至比使用深度卷积的 YOLO MS 还要好。
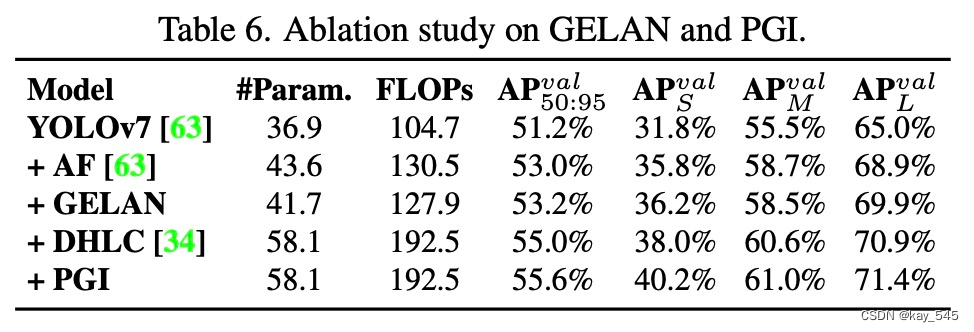
消融实验
为了探究 YOLOv9 中各个组件的作用,该研究进行了一系列消融实验。
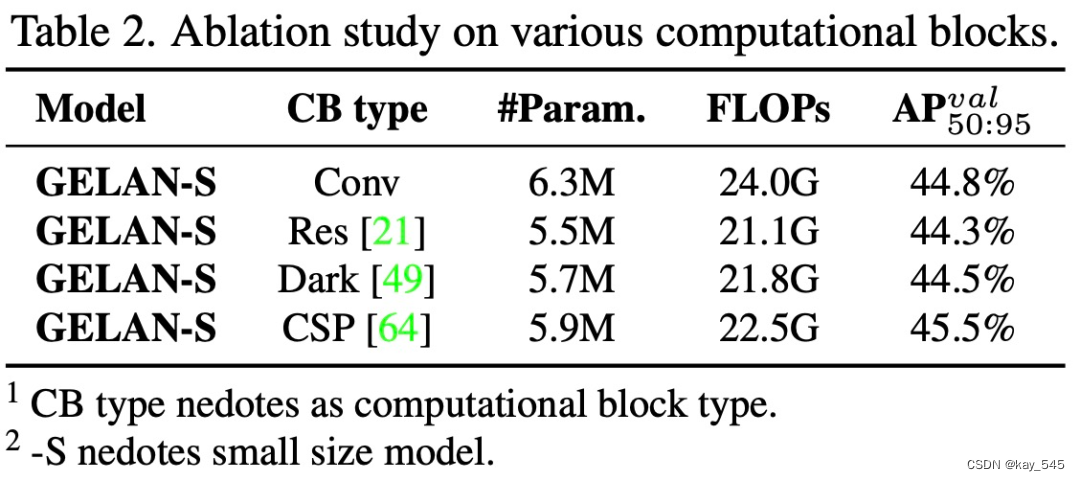
该研究首先对 GELAN 的计算块进行消融实验。如下表所示,该研究发现用不同的计算块替换 ELAN 中的卷积层后,系统可以保持良好的性能。
然后该研究又在不同尺寸的 GELAN 上针对 ELAN 块深度和 CSP 块深度进行了消融实验,结果如下表所示。

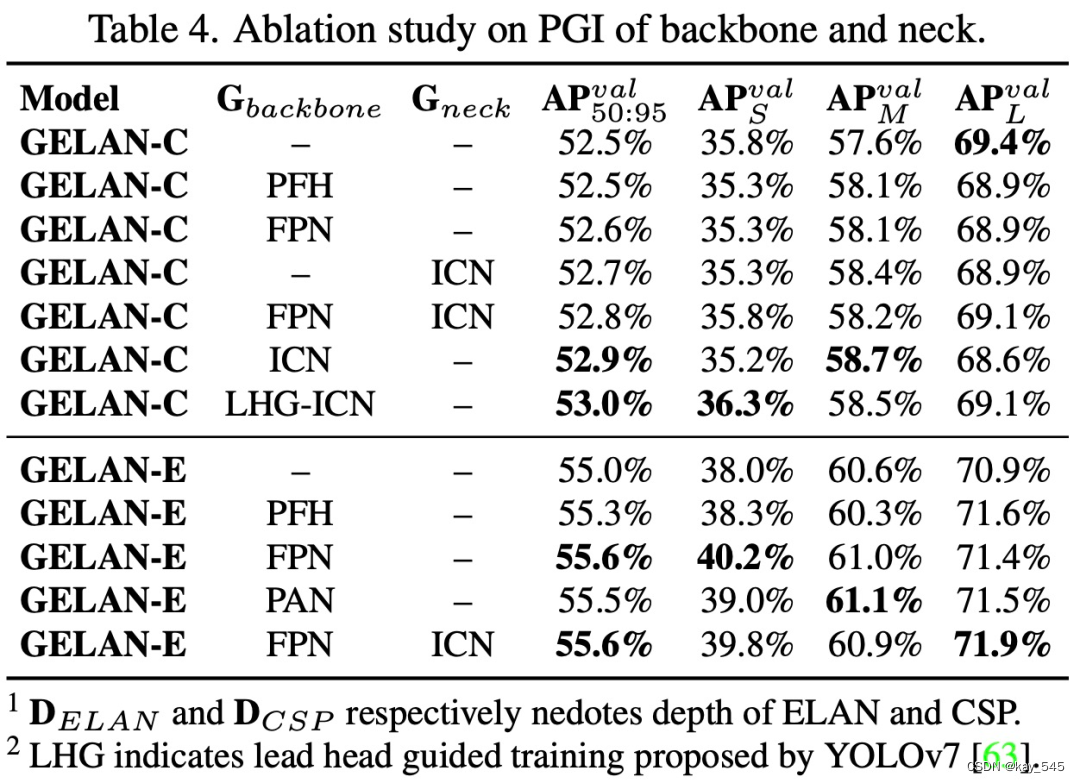
在 PGI 方面,研究者分别在主干网络和 neck 上对辅助可逆分支和多级辅助信息进行了消融研究。表 4 列出了所有实验的结果。从表 4 中可以看出,PFH 只对深度模型有效,而本文提出的 PGI 在不同组合下都能提高精度。
研究者进一步在不同大小的模型上实现了 PGI 和深度监控,并对结果进行了比较,结果如表 5 所示。
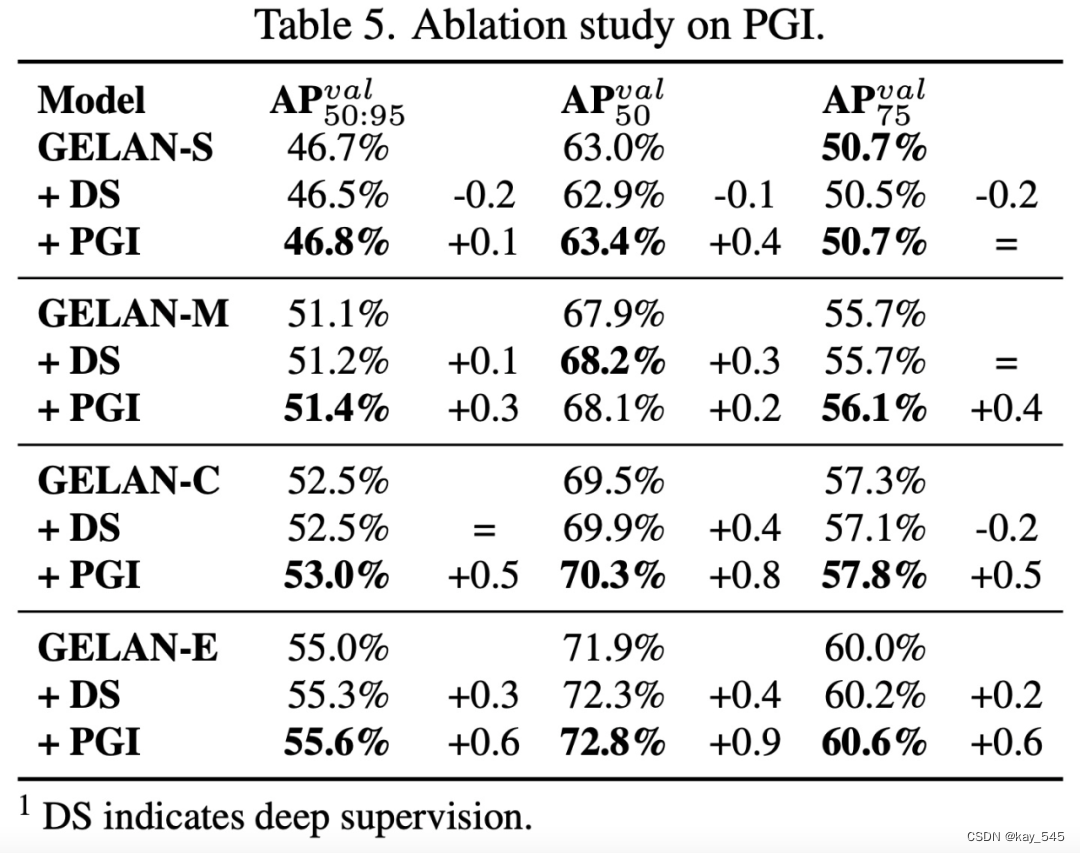
图 6 显示了从基准 YOLOv7 到 YOLOv9- E 逐步增加组件的结果
可视化
研究者探讨了信息瓶颈问题,并将其进行了可视化处理,图 6 显示了在不同架构下使用随机初始权重作为前馈获得的特征图的可视化结果。

图 7 说明了 PGI 能否在训练过程中提供更可靠的梯度,从而使用于更新的参数能够有效捕捉输入数据与目标之间的关系。

结论
本文中,作者提出的可编程梯度信息(PGI)旨在克服信息瓶颈和深度监督在轻量级网络中应用的局限性。GELAN,一种新型高效且轻量的网络架构,被设计出来以优化目标检测任务。GELAN证明了其在不同计算单元和深度配置下的强大性能和稳定性,表明其具有广泛适用性。
PGI的引入显著提升了轻量级及深层模型的准确度。YOLOv9,结合了PGI和GELAN的设计,展现出了卓越的性能。与YOLOv8相比,YOLOv9在参数和计算量上分别减少了49%和43%,同时在MS COCO数据集上的平均精度(AP)提升了0.6%。
附录A中提供了YOLOv9的训练细节,包括使用SGD优化器进行500周期的训练,以及特定的数据增强设置。YOLOv9的网络架构基于YOLOv7 AF,采用CSP-ELAN块替换了原有的ELAN块,优化了下采样模块,并在预测层进行了调整。
附录B中,作者将YOLOv9与采用不同训练策略的先进实时目标检测模型进行了比较,包括从头开始训练、使用ImageNet预训练、知识蒸馏和更复杂的训练过程等。结果显示,YOLOv9在所有比较中均表现最佳,展示了其在参数效率和计算效率上的优势。
综上所述,YOLOv9不仅在不同规模模型中展示了帕累托最优性,而且在处理计算复杂度与准确度权衡时表现出色,强调了PGI和GELAN的创新设计在提高深度学习模型性能方面的重要贡献。