提出背景
论文:https://arxiv.org/pdf/2303.16900.pdf
代码:https://github.com/sail-sg/inceptionnext
受到视觉变换器(ViTs)长距离建模能力的启发,近期广泛研究并采用了大核心卷积技术,以扩大感受野并提高模型性能,像是ConvNeXt的杰出工作所示,它采用了7×7深度卷积。
虽然这种深度操作只消耗少量的浮点操作数(FLOPs),但由于高内存访问成本,在强大的计算设备上大大降低了模型效率。
目前仍不清楚如何在保持性能的同时加速基于大核心的CNN模型。
为了解决这一问题,受到Inception的启发,我们提议将大核心深度卷积分解为沿着通道维度的四个并行分支,即小正方形核心、两个正交的带状核心以及一个恒等映射。
通过这种新型的Inception深度卷积,我们构建了一系列网络,命名为IncepitonNeXt,它们不仅具有高吞吐量,还保持了竞争力的性能。
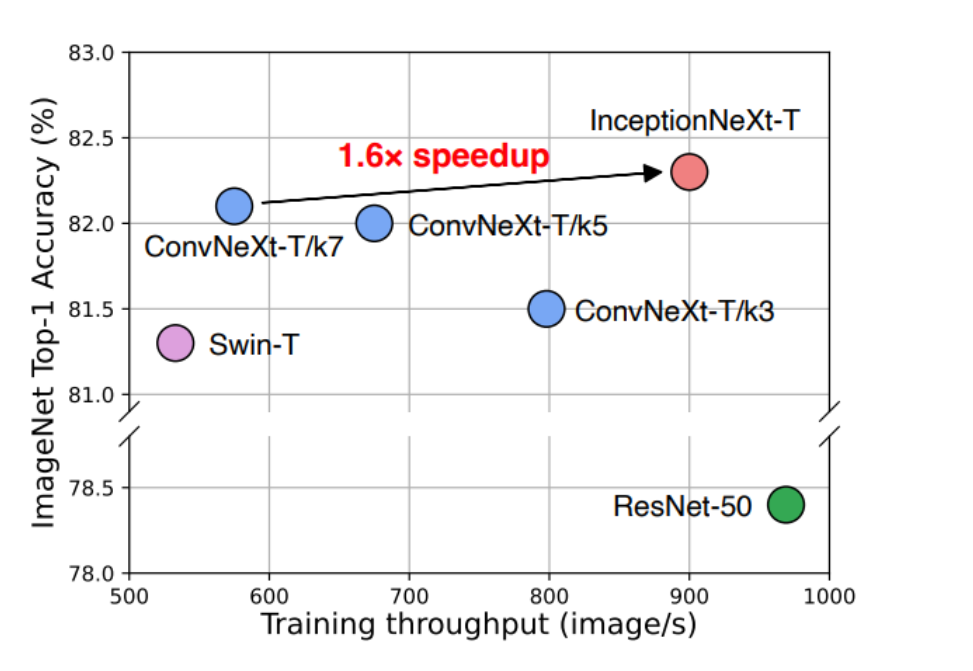
InceptionNeXt模型在保持与ConvNeXt(大卷积核)相近的准确率的同时,训练速度提高了约1.6倍,这表明InceptionNeXt在效率和性能之间取得了良好的平衡。
-
部分通道不进行深度卷积操作:我们的初步发现表明,并非所有输入通道都需要进行计算成本高昂的深度卷积操作。
因此,我们提出只对部分通道进行深度卷积操作,而其他通道保持不变。
这是因为深度卷积操作的高计算成本特性。
-
将大核心深度卷积分解为多组小核心卷积:接着,我们提出将大核心的深度卷积分解为几组小核心的卷积,采用Inception风格。
具体来说,对于进行处理的通道,1/3的通道使用3×3的核心,1/3的通道使用1×k的核心,剩余1/3的通道使用k×1的核心。
这种方法是因为大核心深度卷积的内存访问成本高和速度慢的特征。
问题: 如何提高大核心卷积的效率,同时保持或提升模型性能?
- 解法: 通过改进大核心卷积的结构和计算方法来提高效率,同时保持性能。
- 子特征1: 采用堆叠3×3卷积替代大核心卷积,如VGG模型所示。
- 原因: 通过重复使用小核心卷积,可以在不牺牲感受野的情况下提高计算效率。
- 子特征2: 将k×k卷积分解为1×k和k×1的卷积顺序堆叠,如Inception v3所做。
- 原因: 该方法通过减少参数数量和计算量来提高大核心卷积的效率。
- 子特征3: 分解大核心卷积为多个小组的小核心卷积,以及采用结构重参数化技术等。
- 原因: 这些方法旨在简化大核心卷积的计算,提高模型的运行速度,同时尽可能保持模型的性能。
- 子特征1: 采用堆叠3×3卷积替代大核心卷积,如VGG模型所示。
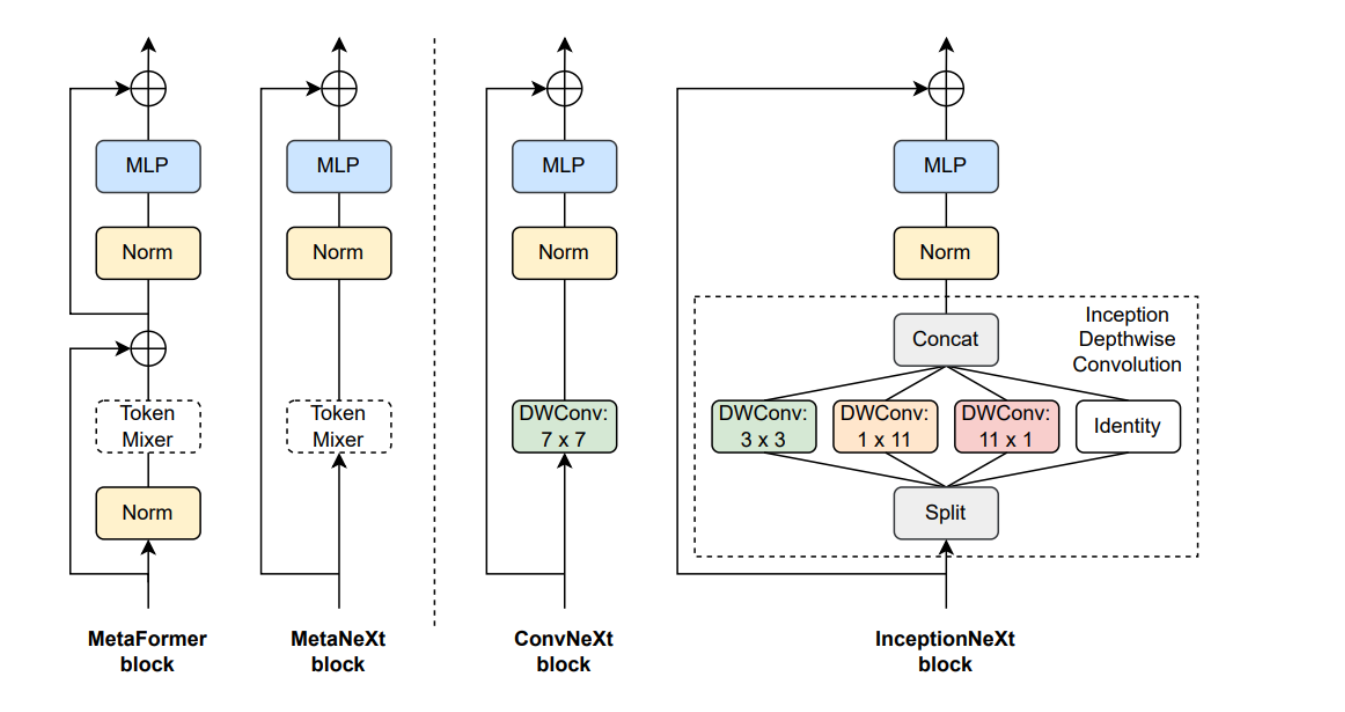
四种不同的模型块结构:MetaFormer块、MetaNeXt块、ConvNeXt块和InceptionNeXt块。
这些块是构建深度学习模型时的基本单元。
MetaFormer块是一个基础结构,包含了标准的MLP和Normalization层,以及一个用于空间信息交互的Token Mixer。
MetaNeXt块是从ConvNeXt块简化而来的,合并了MetaFormer的两个残差子块。
ConvNeXt块采用了7x7的深度卷积作为Token Mixer,而InceptionNeXt块则采用了分解的Inception风格深度卷积,将大核心卷积分解为更小的多个并行分支,这样做可以提高效率。
改进思路
MetaNeXt提供了改进空间信息处理效率的初始框架,Inception深度卷积进一步针对深度卷积的效率进行了优化,最后,InceptionNeXt模型整合了这些优化,构建出既高效又性能卓越的CNN模型。
-
MetaNeXt构建相当于大楼的设计蓝图:
- 就像建筑师设计摩天大楼的蓝图一样,MetaNeXt提供了一个初始框架,确立了基本结构和核心功能。这一步骤确保了大楼(即模型)在满足基本需求的同时,能够高效处理空间信息,为后续的优化和提升奠定基础。
-
Inception深度卷积的创新类似于引入高效的建筑材料和先进的施工技术:
- 正如建筑师选择轻质但强度高的材料,以及采用先进技术来提升建造效率和建筑性能,Inception深度卷积通过优化深度卷积操作,将大核心操作分解为多个小核心操作,类似于采用更高效的材料和技术来提升整个大楼的建造效率和性能。
-
InceptionNeXt模型的构建就像是最终将设计蓝图和先进材料技术整合,建成一座摩天大楼:
- 在有了设计蓝图(MetaNeXt构建)和高效的建筑材料及技术(Inception深度卷积)之后,建筑师和工程师合作,将这些元素整合起来,建造出既美观又高效的摩天大楼。InceptionNeXt模型正是将MetaNeXt的基础框架和Inception深度卷积的优化技术整合在一起,构建出一个既高效又性能卓越的CNN模型,它能够在处理复杂视觉任务时展现出卓越的性能。
就像是从设计蓝图到选择材料和技术,再到最终建造出一座现代化、高效的摩天大楼的整个过程。
MetaNeXt
-
问题: 如何提高模型在处理空间信息时的效率和性能?需要一个高效处理空间信息的模型结构。
-
解法: 提出MetaNeXt块,将深度卷积抽象为token混合器,负责空间信息交互。
- 子特征1: 使用TokenMixer简化深度卷积过程。
- 原因: 为了在保持空间信息交互能力的同时提高处理速度和简化模型结构。
- 子特征2: 在MetaNeXt块中采用标准化和MLP模块以及1×1卷积。
- 原因: 这些操作有助于进一步提升模型的特征提取能力和计算效率。
- 子特征1: 使用TokenMixer简化深度卷积过程。
提出MetaNeXt块,使用TokenMixer简化深度卷积,增加标准化和MLP模块以及1×1卷积,以提高处理速度和简化模型结构,同时保持空间信息交互能力。
MetaNeXt块的设计提供了改进深度卷积处理效率和性能的基础框架,为进一步的优化铺平了道路。
Inception深度卷积
-
问题: 如何解决传统大核心深度卷积在模型速度上的瓶颈?
-
解法: 提出Inception深度卷积,通过分解大核心操作为多个小核心操作来提高效率。
- 子特征1: 对输入通道进行分组,部分通道保持不变,作为恒等映射分支。
- 原因: 研究表明,对于深度卷积层,处理部分通道就足够,这有助于减少计算负担。
- 子特征2: 将处理的通道通过不同的小核心分支进行并行处理。
- 原因: 通过避免使用大的方形核心,而是采用小的方形核心和带状核心,可以在不牺牲感受野的前提下提高计算效率。
- 子特征1: 对输入通道进行分组,部分通道保持不变,作为恒等映射分支。
通过Inception深度卷积的设计,将大核心操作分解为多个小核心操作,对输入通道进行分组并通过不同的小核心分支并行处理。
Inception深度卷积的提出直接针对MetaNeXt块中深度卷积的效率问题,通过更细致的操作优化,实现了更高的计算效率和性能。
这一创新是基于MetaNeXt设计理念的进一步发展和精细化。
InceptionNeXt
- 问题: 如何构建一个既高效又性能卓越的CNN模型?
- 解法: 基于InceptionNeXt块构建一系列模型,采用四阶段框架,并根据ConvNeXt的设计指导原则进行调整。
- 子特征1: 模型采用四阶段框架,与ConvNeXt和ResNet类似。
- 原因: 这种框架结构被证明能有效提升深度学习模型的性能,同时保持良好的计算效率。
- 子特征2: 利用Inception深度卷积在每个阶段内部提升效率和性能。
- 原因: Inception深度卷积通过分解大核心操作为多个并行的小核心操作,实现了更好的速度-准确度权衡。
- 子特征1: 模型采用四阶段框架,与ConvNeXt和ResNet类似。
基于InceptionNeXt块,采用四阶段框架,并根据ConvNeXt的设计指导原则进行调整,整合Inception深度卷积的优化。
InceptionNeXt模型的构建是对MetaNeXt构建和Inception深度卷积设计理念的实际应用和综合体现。
它将MetaNeXt的基础设计理念和Inception深度卷积的具体实现策略相结合,通过一系列精心设计的模型框架,实现了对深度学习模型性能和效率的最优化。
通过这种方法论的分解,我们不仅解决了传统深度卷积操作效率低下的问题,还提出了一种新的CNN架构,即InceptionNeXt,它通过简化和优化卷积操作来提高模型的整体性能和效率。
小目标涨点
更新中…