接上篇一直更换torch、opencv版本都无法解决这个问题(seg调用dnn报错)。那问题会不会出在yolov8源码本身呢。yolov8的讨论区基本都看过了,我决定尝试在其前身yolov5的讨论区上找找我不信没人遇到这个问题。很快找到下面的讨论第一个帖子:
Fix infer yolov5-seg.onnx with opencv-dnn error by UNeedCryDear · Pull Request #9645 · ultralytics/yolov5 · GitHub
按照大佬提供的如下代码快速尝试了问题:
!git clone https://github.com/UNeedCryDear/yolov5 -b master # clone
%cd yolov5
%pip install -r requirements.txt # install(-qr改为-r 可能是笔误)
!python export.py --weights yolov5s-seg.pt --include onnx
!python segment/predict.py --weights yolov5s-seg.onnx --dnn
################################### the same error
!pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111
! pip uninstall torchtext
!python export.py --weights yolov5s-seg.pt --include onnx
!python segment/predict.py --weights yolov5s-seg.onnx --dnn他认为是torch的版本问题该了版本回1.8就没问题但是我运行的结果是还是一样报错:
默认版本不改推理如下:
python segment/predict.py --weights yolov5s-seg.onnx --dnn
segment/predict: weights=['yolov5s-seg.onnx'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/predict-seg, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=True, vid_stride=1, retina_masks=False
YOLOv5 🚀 v6.1-877-gdf48c20 Python-3.8.18 torch-2.2.0+cu121 CUDA:0 (Tesla T4, 14927MiB)
Loading yolov5s-seg.onnx for ONNX OpenCV DNN inference...
Traceback (most recent call last):
File "segment/predict.py", line 285, in <module>
main(opt)
File "segment/predict.py", line 280, in main
run(**vars(opt))
File "/home/inference/miniconda3/envs/yolov5/lib/python3.8/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "segment/predict.py", line 132, in run
pred, proto = model(im, augment=augment, visualize=visualize)[:2]
ValueError: not enough values to unpack (expected 2, got 1)
改版本到1.8:
pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111再次推理如下还是一样的报错:
python segment/predict.py --weights yolov5s-seg.onnx --dnn
segment/predict: weights=['yolov5s-seg.onnx'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/predict-seg, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=True, vid_stride=1, retina_masks=False
YOLOv5 🚀 v6.1-877-gdf48c20 Python-3.8.18 torch-1.8.2+cu111 CUDA:0 (Tesla T4, 14927MiB)
Loading yolov5s-seg.onnx for ONNX OpenCV DNN inference...
Traceback (most recent call last):
File "segment/predict.py", line 285, in <module>
main(opt)
File "segment/predict.py", line 280, in main
run(**vars(opt))
File "/home/inference/miniconda3/envs/yolov5/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "segment/predict.py", line 132, in run
pred, proto = model(im, augment=augment, visualize=visualize)[:2]
ValueError: not enough values to unpack (expected 2, got 1)真的我哭死,已经距离帖子发布的时间比较长了了,难道我要把相关库的版本都复原么,不死心再尝试找找,终于找到如下第二个帖子:Onnx inference not working for image instance segmentation, maybe a bug in ONNX model? · Issue #10578 · ultralytics/yolov5 · GitHubSearch before asking I have searched the YOLOv5 issues and discussions and found no similar questions. Question I have trained my model with Yolov7 at github, but cannot run the inherence (predict.py) without issues when exported to ONNX...![]() https://github.com/ultralytics/yolov5/issues/10578这个贴子的评论区还是上个帖子的UNeedCryDear 这个大佬提到的如下图:
https://github.com/ultralytics/yolov5/issues/10578这个贴子的评论区还是上个帖子的UNeedCryDear 这个大佬提到的如下图:
这里针对dnn的推理结果在源码上做了改动,再次看了yolov5源码发现没做改动,我手动改下方便复制如下:
elif self.dnn: # ONNX OpenCV DNN
im = im.cpu().numpy() # torch to numpy
self.net.setInput(im)
output_layers = self.net.getUnconnectedOutLayersNames()
if len(output_layers) == 2:
output0, output1 = self.net.forward(output_layers)
if len(output0.shape) < len(output1.shape):
y = output0, output1
else:
y = output1, output0
else:
y = self.net.forward()再次推理终于成功了如下:
python segment/predict.py --weights yolov5s-seg.onnx --dnn
segment/predict: weights=['yolov5s-seg.onnx'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/predict-seg, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=True, vid_stride=1, retina_masks=False
YOLOv5 🚀 v6.1-877-gdf48c20 Python-3.8.18 torch-1.8.2+cu111 CUDA:0 (Tesla T4, 14927MiB)
Loading yolov5s-seg.onnx for ONNX OpenCV DNN inference...
image 1/2 /home/inference/yolov5/data/images/bus.jpg: 640x640 4 persons, 1 bus, 734.5ms
image 2/2 /home/inference/yolov5/data/images/zidane.jpg: 640x640 2 persons, 1 tie, 722.3ms
Speed: 0.6ms pre-process, 728.4ms inference, 111.8ms NMS per image at shape (1, 3, 640, 640)
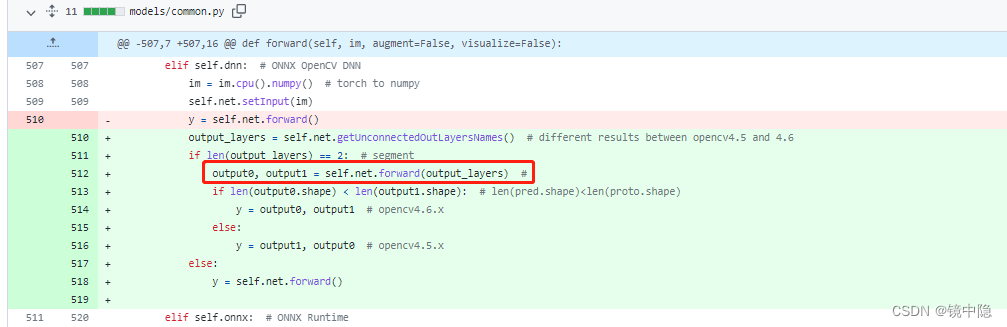
无语了,原来yolov5的作者没处理UNeedCryDear这个大佬第一个帖子的合并请求。再看看yolov8的这段dnn推理代码果然没有同样的问题在https://github.com/ultralytics/ultralytics/blob/main/ultralytics/nn/autobackend.py同样位置完成如yolov5那样的修改如下(方便和我一样的初学者理解我再写下,387行):
elif self.dnn: # ONNX OpenCV DNN
im = im.cpu().numpy() # torch to numpy
self.net.setInput(im)
output_layers = self.net.getUnconnectedOutLayersNames()
if len(output_layers) == 2:
output0, output1 = self.net.forward(output_layers)
if len(output0.shape) < len(output1.shape):
y = output0, output1
else:
y = output1, output0
else:
y = self.net.forward()再次推理yolov8-seg的dnn依旧是报错如下:
yolo predict task=segment model=yolov8n-seg.onnx imgsz=640 dnn
WARNING ⚠️ 'source' is missing. Using default 'source=/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/assets'.
Ultralytics YOLOv8.1.17 🚀 Python-3.9.18 torch-1.11.0+cu102 CUDA:0 (Tesla T4, 14927MiB)
Loading yolov8n-seg.onnx for ONNX OpenCV DNN inference...
WARNING ⚠️ Metadata not found for 'model=yolov8n-seg.onnx'
Traceback (most recent call last):
File "/home/inference/miniconda3/envs/yolov8v2/bin/yolo", line 8, in <module>
sys.exit(entrypoint())
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/cfg/__init__.py", line 568, in entrypoint
getattr(model, mode)(**overrides) # default args from model
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/engine/model.py", line 429, in predict
return self.predictor.predict_cli(source=source) if is_cli else self.predictor(source=source, stream=stream)
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/engine/predictor.py", line 213, in predict_cli
for _ in gen: # noqa, running CLI inference without accumulating any outputs (do not modify)
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 43, in generator_context
response = gen.send(None)
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/engine/predictor.py", line 290, in stream_inference
self.results = self.postprocess(preds, im, im0s)
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/models/yolo/segment/predict.py", line 30, in postprocess
p = ops.non_max_suppression(
File "/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/utils/ops.py", line 230, in non_max_suppression
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
RuntimeError: Trying to create tensor with negative dimension -881: [0, -881]
但与cv2.dnn.readNetFromONNX读取yolov8的onnx报错解决过程_opencvsharp.dnn.net.readnetfromonnx(onnxfile);-CSDN博客文章浏览阅读479次,点赞5次,收藏7次。找到解决方法如下转换时要设置(关键是添加opset=11)上述是尝试用opencv读取模型时的报错信息。_opencvsharp.dnn.net.readnetfromonnx(onnxfile);https://blog.csdn.net/qq_36401512/article/details/136189767?spm=1001.2014.3001.5501里面报错不一致了dimension -837: [0, -837]改为了dimension -881: [0, -881]了,肯定哪里还要做调整。
用如下源码进行调是对别(dnn调用还是onnxruntime调用,pt先转onnx):
# -*-coding:utf-8-*-
from ultralytics import YOLO
model = YOLO("/home/inference/Amplitudemode_AI/all_model_and_pred/AI_Ribfrac_ths/yolov8n-seg.onnx") # 模型加载
results = model.predict(
source='/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/assets', imgsz=640, dnn=True, save=True, boxes=False) # save plotted images 保存绘制图片用dnn=True or False 控制,最终确认是https://github.com/ultralytics/ultralytics/blob/main/ultralytics/utils/ops.py 里215行的问题
nc = nc or (prediction.shape[1] - 4) # number of classes再细看就是Metadata这个字典的问题导致类别数量错误,也就是下面的警告:
WARNING ⚠️ Metadata not found for 'model=/home/inference/Amplitudemode_AI/all_model_and_pred/AI_Ribfrac_ths/yolov8n-seg.onnx'我根据onnxruntime调用的结构抄写一个为保存为metadata.yaml内容如下:
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
task: segment
stride: 32
imgsz: [640,640]
batch: 1放到与onnx模型统一目录下,修改代码https://github.com/ultralytics/ultralytics/blob/main/ultralytics/nn/autobackend.py168行:
elif dnn: # ONNX OpenCV DNN
LOGGER.info(f"Loading {w} for ONNX OpenCV DNN inference...")
check_requirements("opencv-python>=4.5.4")
net = cv2.dnn.readNetFromONNX(w)
metadata = Path(w).parent / "metadata.yaml"再次推理分割模型结果如下:
yolo predict task=segment model=yolov8n-seg.onnx imgsz=640 dnn
WARNING ⚠️ 'source' is missing. Using default 'source=/home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/assets'.
Ultralytics YOLOv8.1.17 🚀 Python-3.9.18 torch-1.11.0+cu102 CUDA:0 (Tesla T4, 14927MiB)
Loading yolov8n-seg.onnx for ONNX OpenCV DNN inference...
image 1/2 /home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/assets/bus.jpg: 640x640 4 persons, 1 bus, 1 skateboard, 304.4ms
image 2/2 /home/inference/miniconda3/envs/yolov8v2/lib/python3.9/site-packages/ultralytics/assets/zidane.jpg: 640x640 2 persons, 2 ties, 309.0ms
Speed: 2.3ms preprocess, 306.7ms inference, 2.4ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs/segment/predict21
💡 Learn more at https://docs.ultralytics.com/modes/predict
终于完结了,虽然耗费了比较多的时间。但是大致理解了yolov8推理代码的整理逻辑和部分细节获益匪浅。