目录
yolov8%E5%AF%BC%E8%88%AA-toc" style="margin-left:0px;">yolov8导航
YOLOv8%EF%BC%88%E9%99%84%E5%B8%A6%E5%90%84%E7%A7%8D%E4%BB%BB%E5%8A%A1%E8%AF%A6%E7%BB%86%E8%AF%B4%E6%98%8E%E9%93%BE%E6%8E%A5%EF%BC%89-toc" style="margin-left:40px;">YOLOv8(附带各种任务详细说明链接)
搭建环境说明
不同版本模型性能对比
不同版本对比
模型参数解释
不同版本说明
训练
训练示意代码
训练用数据集与 .yaml 配置方法
.yaml配置
数据说明
数据集路径
训练参数说明
训练过程示意
训练结果文件说明
weights文件夹
best.pt:损失值最小的模型文件
last.pt:训练到最后的模型文件
args.yaml
confusion_matrix.png - 混淆矩阵
confusion_matrix_normalized.png - 标准化混淆矩阵:
F1_curve.png - F1-置信度曲线
labels.jpg - 标签分布图和边界框分布图
labels_correlogram.jpg - 标签相关图
P_curve.png - 精确度-置信度曲线
PR_curve.png - 精确度-召回曲线
R_curve.png - 召回-置信度曲线
results.png 和 results.csv - 训练结果图表和数据
验证
验证示意代码
验证结果
验证参数
预测
预测示意代码
box输出结果示意
xywh输出示意
cls输出示意
输出参数含义解释
预测参数说明
总结
yolov8导航
如果大家想要了解关于yolov8的其他任务和相关内容可以点击这个链接,我这边整理了许多其他任务的说明博文,后续也会持续更新,包括yolov8模型优化、sam等等的相关内容。
YOLOv8%EF%BC%88%E9%99%84%E5%B8%A6%E5%90%84%E7%A7%8D%E4%BB%BB%E5%8A%A1%E8%AF%A6%E7%BB%86%E8%AF%B4%E6%98%8E%E9%93%BE%E6%8E%A5%EF%BC%89" style="text-align:center;">YOLOv8(附带各种任务详细说明链接)
搭建环境说明
如果不知道如何搭建的小伙伴可以参考这个博文:
超级详细的!多种方式YOLOV8安装及测试
操作系统:win10 x64
编程语言:python3.9
开发环境:Anaconda
示例项目下载地址:
计算机视觉-YOLOv8目标检测-COCO128数据集应用分析
不同版本模型性能对比
不同版本对比
| 模型 | 尺寸 (像素) | 准确率 Top1 | 准确率 Top5 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
模型参数解释
-
尺寸(size): 模型处理的图像尺寸,这里所有模型的输入分辨率均为224x224像素。
-
准确率(accuracy):
- top1: 模型在ImageNet验证集上预测最可能类别的正确率。
- top5: 模型在ImageNet验证集上预测的前五个最可能类别中包含正确类别的概率。
-
速度: 衡量模型处理单张图像所需时间的指标,单位是毫秒(ms)。
- CPU ONNX: 在CPU上使用ONNX格式时的处理速度。
- A100 TensorRT: 在NVIDIA A100 GPU上使用TensorRT加速时的处理速度。
-
参数数量(params (M)): 模型中的参数总数,以百万(M)为单位。
-
浮点运算次数(FLOPs (B) at 640): 执行一次前向传播所需的浮点运算次数,以十亿(B)为单位,这里基于640像素的输入计算。
不同版本说明
-
YOLOv8n-cls: 这是系列中最轻量的模型,拥有最快的处理速度但准确率相对较低。适合资源有限或对速度要求较高的场景。
-
YOLOv8s-cls: 相比YOLOv8n,它在保持较高速度的同时,准确率有所提升。适合需要在速度和准确度之间取得平衡的应用。
-
YOLOv8m-cls: 在准确率上有显著提升,适合对准确度有更高要求,但仍然需要考虑处理速度的场景。
-
YOLOv8l-cls: 更高的准确率使其适用于对准确度要求较高的应用,但处理速度较慢。
-
YOLOv8x-cls: 在这个系列中,它提供了最高的准确率,但速度最慢,需要较强的硬件支持。适合在准确度至关重要的高端应用。
训练
训练示意代码
from ultralytics import YOLO
# 加载模型
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML构建并转移权重
if __name__ == '__main__':
# 训练模型
results = model.train(data='coco128.yaml', epochs=10, imgsz=512)
metrics = model.val()这个代码和图像分类任务中数据指定方式略有不同,图像分类中直接指向数据的文件夹即可,在目标检测中需要你指向配置好的 .yaml 文件。
训练用数据集与 .yaml 配置方法
.yaml配置
# 这里的path需要指向你项目中数据集的目录
path: C:/Users/admin/Desktop/CSDN/YOLOV8_DEF/ultralytics-detect/datasets/coco128/
# 这里分别指向你训练、验证、测试的文件地址,只需要指向图片的文件夹即可。但是要注意图片和labels名称要对应
train: images/train2017 # train images (relative to 'path') 128 images
val: images/test2017 # val images (relative to 'path') 128 images
test: images/test2017 # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
......
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush上面的则是 yaml文件的配置示意方法。注意这里我直接把测试集和验证集都指向了一个文件夹,正式项目的时候建议这两个数据集都单独准备。
数据说明
在使用YOLOv8进行目标检测时,每个图像通常都伴随一个.txt文件,该文件包含了关于图像中对象的标注信息。这些.txt文件中的每一行都代表图像中的一个对象,包含以下信息:
-
类别ID:这是一个整数,代表了对象所属的类别。例如,如果你的数据集有“人”、“车”和“狗”三个类别,那么可能分别用0、1和2来表示这些类别。
-
中心X坐标:这是一个归一化后的值,代表对象边界框中心的X坐标(水平方向)。这个值是相对于整个图像宽度的比例。
-
中心Y坐标:这是一个归一化后的值,代表对象边界框中心的Y坐标(垂直方向)。这个值是相对于整个图像高度的比例。
-
边界框宽度:这也是一个归一化后的值,代表对象边界框的宽度。这个值是相对于整个图像宽度的比例。
-
边界框高度:这同样是一个归一化值,代表对象边界框的高度。这个值是相对于整个图像高度的比例。
举例来说,如果一个.txt文件中的一行是1 0.5 0.5 0.2 0.3,这意味着该对象属于类别1(例如“车”),其边界框的中心位于图像中心(X和Y坐标均为0.5),边界框的宽度是图像宽度的20%,高度是图像高度的30%。
数据集路径
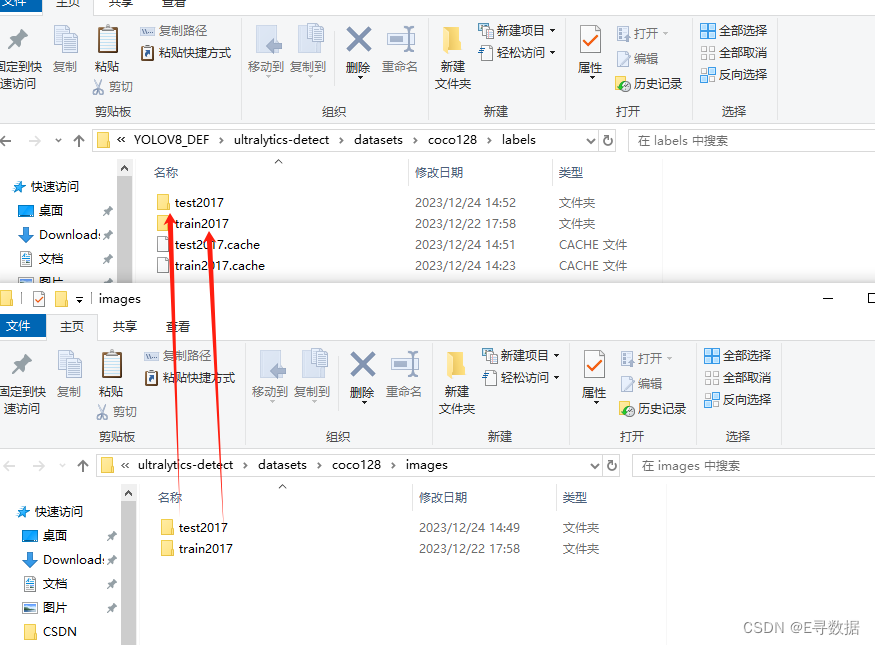
这里需要注意,训练集测试集的图片和标签都要一一对应。同时,注意观察这里面的路径是和 .yaml文件中都是对应的关系。
训练参数说明
| 参数 | 默认值 | 描述 | 设置建议 |
|---|---|---|---|
| model | None | 模型文件路径,如 yolov8n.pt, yolov8n.yaml | 根据需要选择合适的预训练模型文件 |
| data | None | 数据文件路径,如 coco128.yaml | 选择合适的数据集配置文件 |
| epochs | 100 | 训练的周期数 | 根据数据集大小和模型复杂度调整 |
| time | None | 训练时间(小时),如果提供,将覆盖epochs参数 | 根据实际训练时间需求设置 |
| patience | 50 | 早停的周期数,等待无显著改进的周期数 | 根据模型训练动态调整 |
| batch | 16 | 每个批次的图像数量 | 根据硬件资源调整 |
| imgsz | 640 | 输入图像的尺寸 | 根据硬件和模型性能要求调整 |
| save | True | 是否保存训练检查点和预测结果 | 通常保持默认 |
| save_period | -1 | 每x周期保存检查点,如果<1则禁用 | 根据需要设置 |
| cache | False | 是否使用数据加载缓存,选项:True/ram, disk 或 False | 根据硬件资源和数据集大小决定 |
| device | None | 运行设备,如 cuda device=0 或 device=cpu | 根据可用的硬件资源设置 |
| workers | 8 | 数据加载的工作线程数 | 根据系统资源调整 |
| project | None | 项目名称 | 根据需要自定义 |
| name | None | 实验名称 | 自定义实验名以便识别 |
| exist_ok | False | 是否覆盖现有实验 | 如果需要重复实验,设置为True |
| pretrained | True | 是否使用预训练模型 | 通常对于新的训练任务保持True |
| optimizer | 'auto' | 优化器,可选项:SGD, Adam等 | 根据模型和数据集特性选择合适的优化器 |
| verbose | False | 是否打印详细输出 | 开发和调试时可设为True |
| seed | 0 | 重现性的随机种子 | 需要重现结果时设置确定值 |
| deterministic | True | 是否启用确定性模式 | 需要确保结果一致性时设置为True |
| single_cls | False | 是否将多类数据作为单类训练 | 特定应用场景下调整 |
| rect | False | 矩形训练,每个批次为最小填充 | 特定应用场景下调整 |
| cos_lr | False | 是否使用余弦学习率调度器 | 根据训练策略调整 |
| close_mosaic | 10 | 关闭马赛克增强的最后周期数 | 根据训练需求调整 |
| resume | False | 从最后检查点恢复训练 | 需要从中断的训练继续时设置为True |
| amp | True | 是否使用自动混合精度训练 | 根据硬件支持选择 |
| fraction | 1.0 | 训练的数据集比例 | 如需使用数据集的子集进行训练,调整此值 |
| profile | False | 训练期间记录ONNX和TensorRT速度 | 性能分析时启用 |
| freeze | None | 冻结训练期间的前n层或特定层 | 特定模型调整时使用 |
| lr0 | 0.01 | 初始学习率 | 根据模型和数据集特性调整 |
| lrf | 0.01 | 最终学习率 | 根据训练策略调整 |
| momentum | 0.937 | SGD动量/Adam beta1 | 根据优化器类型调整 |
| weight_decay | 0.0005 | 优化器权重衰减 | 通常保持默认值 |
| warmup_epochs | 3.0 | 热身周期数 | 根据模型特性调整 |
| warmup_momentum | 0.8 | 热身初始动量 | 根据训练策略调整 |
| warmup_bias_lr | 0.1 | 热身初始偏置学习率 | 根据训练策略调整 |
| box | 7.5 | 盒子损失增益 | 根据模型特性和训练数据调整 |
| cls | 0.5 | 类别损失增益 | 根据分类任务的复杂性调整 |
| dfl | 1.5 | DFL损失增益 | 根据具体应用调整 |
| pose | 12.0 | 姿态损失增益(仅限姿态) | 仅在姿态检测任务中使用 |
| kobj | 2.0 | 关键点目标损失增益(仅限姿态) | 仅在姿态检测任务中使用 |
| label_smoothing | 0.0 | 标签平滑(比例) | 根据训练策略调整 |
| nbs | 64 | 标称批量大小 | 根据硬件资源调整 |
| overlap_mask | True | 掩码在训练期间是否重叠(仅限分割训练) | 仅在分割任务中使用 |
| mask_ratio | 4 | 掩码下采样比例(仅限分割训练) | 仅在分割任务中使用 |
| dropout | 0.0 | 使用dropout正则化(仅限分类训练) | 仅在分类任务中使用 |
| val | True | 训练期间进行验证/测试 | 通常保持默认 |
| plots | False | 训练/验证期间保存图表和图像 | 需要可视化训练过程时设置为True |
训练过程示意
在可以正常执行训练的时候,咱们就可以看到一个个Epoch的迭代记录了。
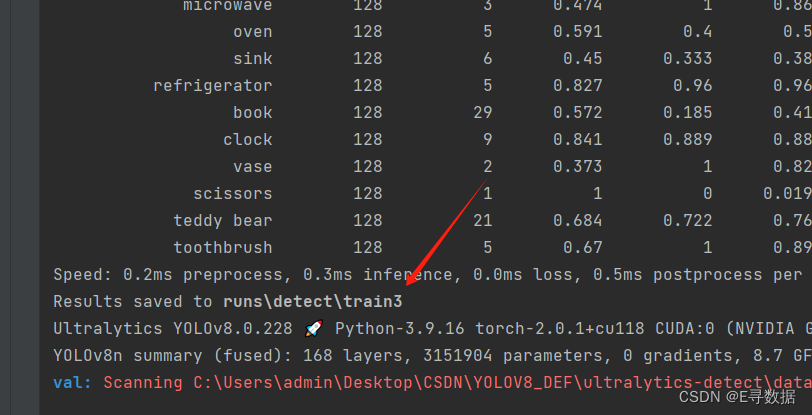
看到了这个Results saved to runs\detect\train这个路径的时候说明模型已经训练完了,并且把训练的结果已经保存到了这个文件夹中。输出的结果如下:
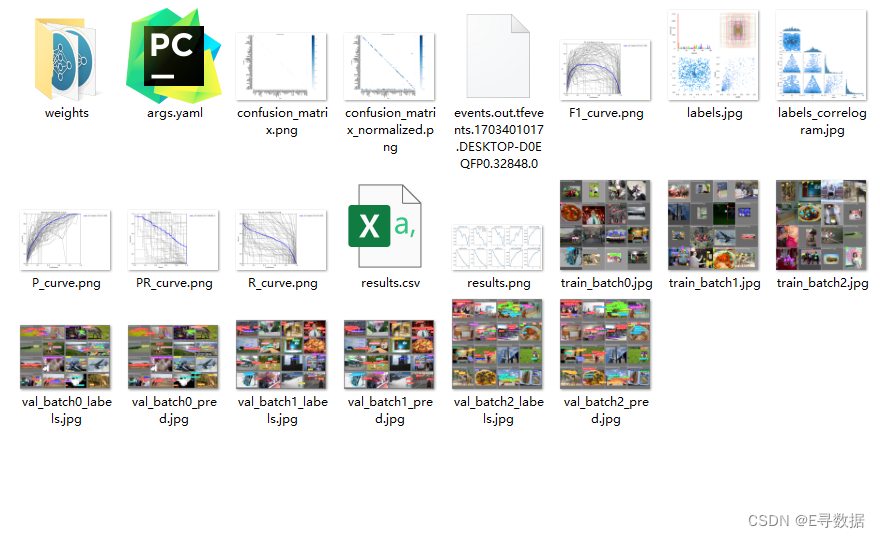
训练结果文件说明
weights文件夹
best.pt:损失值最小的模型文件
last.pt:训练到最后的模型文件
args.yaml
模型训练的配置参数
confusion_matrix.png - 混淆矩阵
这张图展示了分类模型的性能。每一行代表模型预测的类别,每一列代表实际的类别。对角线上的数值表示模型正确预测的数量。对角线上较深的颜色表示该类别预测正确的数量较多。
confusion_matrix_normalized.png - 标准化混淆矩阵:
与普通混淆矩阵类似,但这里的值显示的是每个类别的预测正确比例。这有助于比较不同类别的预测准确性,尤其是在类别样本数量不平衡的情况下。
F1_curve.png - F1-置信度曲线
此曲线显示了F1得分随着置信度阈值的变化。F1得分是精确度和召回率的调和平均值,曲线的峰值表示给定置信度阈值下精确度和召回率的最佳平衡点。
labels.jpg - 标签分布图和边界框分布图
柱状图显示了不同类别的实例分布数量。散点图则展示了目标检测任务中边界框的空间分布情况,反映了常见的尺寸和长宽比。
labels_correlogram.jpg - 标签相关图
相关图提供了不同类别标签之间的关系,以及它们在图像中位置的相关性。这有助于理解模型在识别不同类别时可能出现的关联或混淆。
P_curve.png - 精确度-置信度曲线
这张曲线图展示了模型预测的精确度随着置信度阈值的变化。精确度是模型预测正确正例与预测为正例总数的比值。
PR_curve.png - 精确度-召回曲线
这张曲线图展示了模型的精确度与召回率之间的关系。理想情况下,模型应在精确度和召回率之间保持良好的平衡。
R_curve.png - 召回-置信度曲线
此曲线图显示了模型的召回率随置信度阈值的变化。召回率是模型正确预测的正例与实际正例总数的比值。
results.png 和 results.csv - 训练结果图表和数据
这些图表和数据文件展示了模型在训练过程中的性能变化,包括损失函数的变化和评估指标(如精确度、召回率和mAP)的变化。
这些图表对于评估和理解模型在分类或目标检测任务中的性能至关重要,帮助我们确定模型的强项和弱点,以及可能需要改进的地方。
验证
验证示意代码
# 验证模型
metrics = model.val() # 无需参数,数据集和设置已记忆上文中进行模型训练的时候有这个代码,是直接对模型基于验证数据集进行验证测试模型实际预测效果。
验证结果
当执行完了验证之后会输出如下文件:
验证参数
| 键 | 值 | 描述 |
|---|---|---|
| data | None | 数据文件的路径,例如 coco128.yaml |
| imgsz | 640 | 输入图像的大小,以整数表示 |
| batch | 16 | 每批图像的数量(AutoBatch 为 -1) |
| save_json | False | 将结果保存至 JSON 文件 |
| save_hybrid | False | 保存混合版本的标签(标签 + 额外预测) |
| conf | 0.001 | 用于检测的对象置信度阈值 |
| iou | 0.6 | NMS(非极大抑制)用的交并比(IoU)阈值 |
| max_det | 300 | 每张图像的最大检测数量 |
| half | True | 使用半精度(FP16) |
| device | None | 运行所用的设备,例如 cuda device=0/1/2/3 或 device=cpu |
| dnn | False | 使用 OpenCV DNN 进行 ONNX 推理 |
| plots | False | 在训练期间显示图表 |
| rect | False | 矩形验证,每批图像为了最小填充整齐排列 |
| split | val | 用于验证的数据集分割,例如 'val'、'test' 或 'train' |
预测
预测示意代码
from ultralytics import YOLO
# 读取模型,这里传入训练好的模型
model = YOLO('yolov8n.pt')
# 模型预测,save=True 的时候表示直接保存yolov8的预测结果
metrics = model.predict(['im1.jpg', 'im2.jpg'], save=True)
# 如果想自定义的处理预测结果可以这么操作,遍历每个预测结果分别的去处理
for m in metrics:
# 获取每个boxes的结果
box = m.boxes
# 获取box的位置,
xywh = box.xywh
# 获取预测的类别
cls = box.cls
print(box, xywh, cls)box输出结果示意
0: 640x640 4 persons, 1 bus, 1: 640x640 6 persons, 1 car, 64.9ms
Speed: 2.5ms preprocess, 32.5ms inference, 18.5ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs\detect\predict3
ultralytics.engine.results.Boxes object with attributes:
cls: tensor([0., 5., 0., 0., 0.], device='cuda:0')
conf: tensor([0.8845, 0.8296, 0.3599, 0.3571, 0.3444], device='cuda:0')
data: tensor([[4.3449e+02, 2.1734e+02, 5.5059e+02, 4.9711e+02, 8.8453e-01, 0.0000e+00],
[4.7913e+01, 8.7620e+00, 7.1790e+02, 4.0818e+02, 8.2957e-01, 5.0000e+00],
[4.3854e+02, 1.7932e+02, 4.9143e+02, 2.6983e+02, 3.5992e-01, 0.0000e+00],
[4.9167e+02, 1.5904e+02, 5.2241e+02, 2.6426e+02, 3.5714e-01, 0.0000e+00],
[5.6224e+02, 1.8580e+02, 5.8750e+02, 2.3147e+02, 3.4444e-01, 0.0000e+00]], device='cuda:0')
id: None
is_track: False
orig_shape: (500, 727)
shape: torch.Size([5, 6])
xywh: tensor([[492.5402, 357.2264, 116.0933, 279.7678],
[382.9070, 208.4702, 669.9885, 399.4163],
[464.9885, 224.5762, 52.8898, 90.5052],
[507.0404, 211.6490, 30.7484, 105.2242],
[574.8698, 208.6357, 25.2673, 45.6745]], device='cuda:0')
xywhn: tensor([[0.6775, 0.7145, 0.1597, 0.5595],
[0.5267, 0.4169, 0.9216, 0.7988],
[0.6396, 0.4492, 0.0728, 0.1810],
[0.6974, 0.4233, 0.0423, 0.2104],
[0.7907, 0.4173, 0.0348, 0.0913]], device='cuda:0')
xyxy: tensor([[434.4935, 217.3425, 550.5868, 497.1103],
[ 47.9128, 8.7620, 717.9013, 408.1783],
[438.5436, 179.3236, 491.4334, 269.8288],
[491.6662, 159.0369, 522.4146, 264.2610],
[562.2361, 185.7984, 587.5034, 231.4729]], device='cuda:0')
xyxyn: tensor([[0.5977, 0.4347, 0.7573, 0.9942],
[0.0659, 0.0175, 0.9875, 0.8164],
[0.6032, 0.3586, 0.6760, 0.5397],
[0.6763, 0.3181, 0.7186, 0.5285],
[0.7734, 0.3716, 0.8081, 0.4629]], device='cuda:0')xywh输出示意
tensor([[492.5402, 357.2264, 116.0933, 279.7678],
[382.9070, 208.4702, 669.9885, 399.4163],
[464.9885, 224.5762, 52.8898, 90.5052],
[507.0404, 211.6490, 30.7484, 105.2242],
[574.8698, 208.6357, 25.2673, 45.6745]], device='cuda:0')
tensor([[117.5208, 281.1165, 109.7290, 153.1513],
[163.9415, 275.8445, 58.6842, 165.7656],
[407.1587, 270.8329, 53.9834, 169.9082],
[443.5874, 269.0132, 81.5869, 171.1809],
[463.1820, 269.4791, 120.3752, 171.6237],
[512.3868, 202.5452, 74.8936, 62.6308],
[404.3465, 251.4608, 48.4166, 132.9844]], device='cuda:0')cls输出示意
tensor([0., 5., 0., 0., 0.], device='cuda:0')
tensor([0., 0., 0., 0., 0., 2., 0.], device='cuda:0')输出参数含义解释
-
cls: 这是一个张量(Tensor),表示每个检测到的对象的类别索引。例如,
tensor([0., 5., 0., 0., 0.], device='cuda:0')中的0和5表示第一个对象被分类为类别0,第二个对象被分类为类别5,以此类推。 -
conf: 这是一个张量,表示每个检测到的对象的置信度分数。分数越高,模型对其检测结果越有信心。
-
data: 这个张量包含了检测到的对象的边界框(bounding box)信息,通常格式为[x, y, width, height, confidence, class]。
-
xywh: 这是边界框的坐标和尺寸,格式为[中心点x坐标, 中心点y坐标, 宽度, 高度]。
-
xywhn: 这些是归一化的边界框坐标和尺寸,意味着这些值相对于图像的尺寸进行了归一化,取值范围通常在0到1之间。
-
xyxy: 这是边界框的坐标,但是以两个角的坐标表示,格式为[左上角x坐标, 左上角y坐标, 右下角x坐标, 右下角y坐标]。
-
xyxyn: 这些是归一化的xyxy格式的边界框坐标。
-
is_track: 表示是否使用跟踪算法跟踪对象。
-
orig_shape 和 shape: 分别表示原始图像的形状和处理后的张量的形状。
预测参数说明
在执行预测的时候,model() 等同与 model.predict(),里面有如下参数:
| 名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
source | str | 'ultralytics/assets' | 图像或视频的源目录 |
conf | float | 0.25 | 检测对象的置信度阈值 |
iou | float | 0.7 | 用于NMS的交并比(IoU)阈值 |
imgsz | int or tuple | 640 | 图像大小,可以是标量或(h, w)列表,例如(640, 480) |
half | bool | False | 使用半精度(FP16) |
device | None or str | None | 运行设备,例如 cuda device=0/1/2/3 或 device=cpu |
show | bool | False | 如果可能,显示结果 |
save | bool | False | 保存带有结果的图像 |
save_txt | bool | False | 将结果保存为.txt文件 |
save_conf | bool | False | 保存带有置信度分数的结果 |
save_crop | bool | False | 保存带有结果的裁剪图像 |
show_labels | bool | True | 隐藏标签 |
show_conf | bool | True | 隐藏置信度分数 |
max_det | int | 300 | 每张图像的最大检测数量 |
vid_stride | bool | False | 视频帧速率跳跃 |
stream_buffer | bool | False | 缓冲所有流媒体帧(True)或返回最新帧(False) |
line_width | None or int | None | 边框线宽度。如果为None,则按图像大小缩放。 |
visualize | bool | False | 可视化模型特征 |
augment | bool | False | 应用图像增强到预测源 |
agnostic_nms | bool | False | 类别不敏感的NMS |
retina_masks | bool | False | 使用高分辨率分割掩码 |
classes | None or list | None | 按类别过滤结果,例如 classes=0,或 classes=[0,2,3] |
boxes | bool | True | 在分割预测中显示框 |
总结
这篇博文提供了一个关于使用YOLOv8进行目标检测的全面指南,包括环境搭建、模型训练、验证和预测的详细步骤,以及如何解释训练过程中生成的各种图表和数据。整篇文章为读者提供了一个关于如何利用YOLOv8进行目标检测的实践指南,从环境搭建到模型部署,再到结果分析,每一部分都给出了详细的步骤和解释。此外,还有对于模型输出的解释,帮助读者更好地理解和使用YOLOv8模型。如果有哪里写的不够清晰,小伙伴本可以给评论或者留言,我这边会尽快的优化博文内容,另外如有需要,我这边可支持技术答疑与支持。