动物姿态估计是计算机视觉的一个研究领域,是人工智能的一个子领域,专注于自动检测和分析图像或视频片段中动物的姿势和位置。目标是确定一种或多种动物的身体部位(例如头部、四肢和尾巴)的空间排列。这项技术具有广泛的应用,从研究动物行为和生物力学到野生动物保护和监测。
在这篇博文中,我们将专门处理狗的关键点估计,并向您展示如何微调 Ultralytics 非常流行的 YOLOv8 姿势模型。
微调动物关键点的姿态模型可能具有挑战性,需要微调多个超参数。幸运的是,YOLOv8 在模型微调期间提供了相当多的超参数自定义。准确地说,我们将微调以下 YOLOv8 姿势模型:
YOLOv8m(中)
YOLOv8l(大)
此外,通过比较 YOLOv7 和 MediaPipe 姿态模型之间的推理结果,查看我们深入的人体姿态分析。
1. 斯坦福狗的动物姿势估计数据集
2. 用于动物姿态估计的数据集异常
2.1 处理跨框和关键点的不匹配的地面实况注释,以进行动物姿态估计
3. 为训练和验证数据创建与 YOLOv8 一致的注解
3.1 下载图像数据和关键点元数据
3.2 创建用于动物姿态估计的 YOLO 训练和验证目录
3.3 创建最终的 YOLO 注释文本文件
4 动物姿态估计的超参数设置和微调
4.1 训练配置
4.2 数据配置
4.3 动物姿势估计的微调和训练
5 YOLOv8在动物姿态估计中的评价
6 动物姿势图像预测的可视化
7 结论
8 引用
斯坦福狗的动物姿势估计数据集
对于我们的动物姿势估计实验,我们将使用斯坦福数据集,该数据集包含 120 个品种的狗,分布在 20,580 张图像中。此外,数据集还包含这些图像的边界框注释。
关键点注释需要通过填写谷歌表单从 StandfordExtra 数据集下载。在 12,538 张图像中提供了 20 个狗姿势关键点的关键点注释(每条腿 3 个,每只耳朵 2 个,尾巴、鼻子和下巴 2 个)。
下载的注释将包含以下结构:
StanfordExtra_V12
├── StanfordExtra_v12.json
├── test_stanford_StanfordExtra_v12.npy
├── train_stanford_StanfordExtra_v12.npy
└── val_stanford_StanfordExtra_v12.npy
训练、验证和测试拆分分别作为原始数据的索引提供,这些数据分别包含 6773、4062 和 1703 图像的注释。StanfordExtra_v12.json
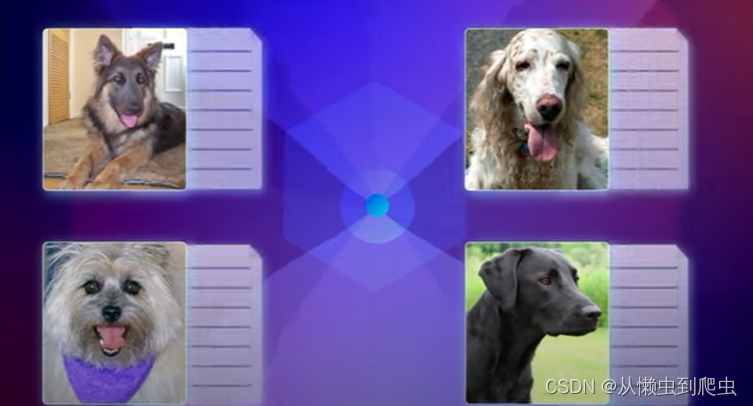
作者还以文件的形式提供了关键点元数据,其中包含动物姿势名称、每个关键点的颜色编码等。但是,它包含 24 个关键点(每个眼睛、喉咙和肩膀各 1 个)的信息。可以使用下图来说明关键点。CSV

需要微调的狗关键点
在总共 24 个关键点中,只有 20 个存在注释。对于遗漏的 4 个关键点(2 个用于眼睛、喉咙和凋零),坐标标记为 0。
还有一个额外的布尔可见性标志,它与 20 个关键点相关联:
0:不可见
1:可见
用于动物姿态估计的数据集异常
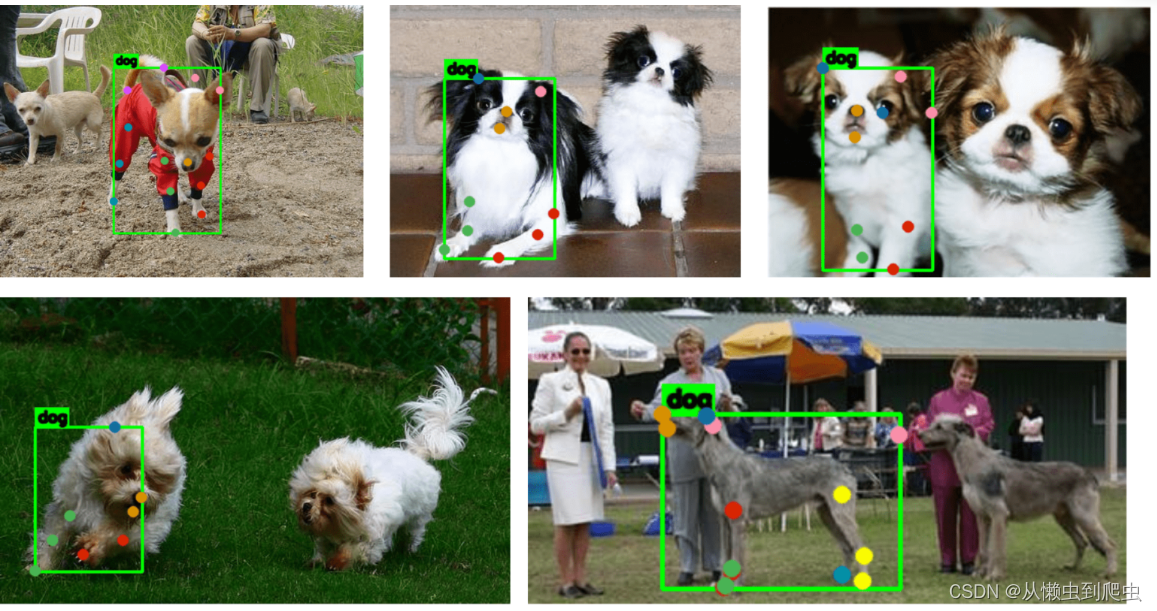
边界框和关键点的真值注释仅适用于单个对象实例。此外,仍然有相当多的不正确的注释,从下面的示例中可以看出。

边界框和关键点的真值注释仅适用于单个对象实例。此外,仍然有相当多的不正确的注释,从下面的示例中可以看出。
从最左上角的图像中可以看出,边界框和关键点已针对两个不同的对象实例进行了注释。第一行的第二张和第四张图片(从左到右)以及第二行的第一张和第三张图片也反映了这一点。
此外,关键点也被错误地注释了,如第一行的第三张图片所示,下颌和左耳尖被错误地注释。第二行的第一张图像也是如此,其中左耳的尖端被错误标记。第二行的第四张图片中出现了另一个不正确的注释,其中两个耳塞都被贴错了标签。
如前所述,每个图像只有单个实例注释。观察第二行的第二张图片(从左到右),我们只有左边的狗的注释,而有三个狗的实例。
处理跨框和关键点的不匹配的地面实况注释,以进行动物姿态估计
处理不匹配的框和关键点注释的一种直观方法是根据给定的关键点估计矩形。这可以使用实用程序函数来近似给定一组坐标的矩形来完成。请稍等片刻,看看下面的示例。cv2.boundingRect
处理不匹配的边界框和关键点批注
尽管边界框并不完美,但使用上述方法处理不匹配的边界框和关键点注释可能成本低廉。我们可以运行一个检测模型,如 YOLOv8 来获得更准确的框注释,然后将关键点与最接近的边界框映射。
但是,我们将坚持使用原始 JSON 文件中提供的注释进行实验。
为训练和验证数据创建与 YOLOv8 一致的注解
在准备数据之前,我们需要精通 Ultralytics 的 YOLOv8 姿态模型所接受的关键点检测注释格式。以下几点突出显示了用于微调 Ultralytics 的 YOLOv8 Pose 模型的数据集格式:
用于训练YOLO姿态模型的数据集格式如下:
每张图片一个文本文件:数据集中的每张图片都有一个对应的文本文件,其名称和扩展名与图片相同。.txt
每个对象一行:文本文件中的每一行对应于图像中的一个对象实例。
每行对象信息:每行包含有关对象实例的以下信息:
对象类索引:表示对象类的整数(例如,人、汽车等)。01
对象中心坐标:对象中心的 x 和 y 坐标归一化为 和 。01
对象宽度和高度:对象的宽度和高度被规范化为介于 和 之间。01
对象宽度和高度:对象的宽度和高度被规范化为介于 和 之间。01
此外,可见性标志与关键点坐标相关联。它可以包含以下三个值之一:
0:未标记
1:已标记但不可见
2:已标记且可见。
JSON 注释包含一个额外的布尔可见性标志和前面讨论的关键点坐标。我们将所有可见关键点的标志设置为 。2
Ultralytics 中微调姿态模型的关键点注释对应于以下语法:
…
0 0.55991 0.503 0.76688 0.918 0.39143 0.91133 2.0 0.44227 0.72467 2.0
条目中的第一项是CLASS_ID,后跟边界框数据(规范化 x中心、y中心、宽度、高度),最后是归一化坐标以及可见性标志(即,对于两个关键点)。[x y]2
下载图像数据和关键点元数据
在开始数据准备之前,我们需要先下载图像数据。让我们定义一个实用程序函数,用于下载和提取包含图像的文件。此外,我们还将下载包含关键点元数据的元数据,例如动物姿势名称、每个关键点的颜色编码等,涵盖所有关键点。images.tarkeypoint_definitions.csv24
def download_and_unzip(url, save_path):
print("Downloading and extracting assets...", end="")
file = requests.get(url)
open(save_path, "wb").write(file.content)
try:
# Extract tarfile.
if save_path.endswith(".tar"):
with tarfile.open(save_path, "r") as tar:
tar.extractall(os.path.split(save_path)[0])
现在让我们指定图像和元数据 URL 并下载它们。
IMAGES_URL = r"http://vision.stanford.edu/aditya86/ImageNetDogs/images.tar"
IMAGES_DIR = "Images"
IMAGES_TAR_PATH = os.path.join(os.getcwd(), f"{IMAGES_DIR}.tar")
ANNS_METADATA_URL = r"https://github.com/benjiebob/StanfordExtra/raw/master/keypoint_definitions.csv"
ANNS_METADATA = "keypoint_definitions.csv"
# Download if dataset does not exists.
if not os.path.exists(IMAGES_DIR):
download_and_unzip(IMAGES_URL, IMAGES_TAR_PATH)
os.remove(IMAGES_TAR_PATH)
if not os.path.isfile(ANNS_METADATA):
download_and_unzip(ANNS_METADATA_URL, ANNS_METADATA)
所有下载的图像都将提取到目录中。它具有以下目录结构:Images
Images/
├── n02085620-Chihuahua
│ ├── n02085620_10074.jpg
│ ├── n02085620_10131.jpg
│ └── ...
├── n02085782-Japanese_spaniel
│ ├── n02085782_1039.jpg
│ ├── n02085782_1058.jpg
│ └── n02085782_962.jpg
└── ...
它指定了所有 120 个类别的狗的图像文件。
创建用于动物姿态估计的 YOLO 训练和验证目录
在为动物姿态估计创建训练和验证数据之前,我们需要有注释 JSON 文件。该目录包含文件以及训练、验证和测试拆分。StanfordExtra_V12StanfordExtra_v12.json
StanfordExtra_V12
├── StanfordExtra_v12.json
├── test_stanford_StanfordExtra_v12.npy
├── train_stanford_StanfordExtra_v12.npy
└── val_stanford_StanfordExtra_v12.npy
现在让我们阅读注释文件。
NN_PATH = "StanfordExtra_V12"
JSON_PATH = os.path.join(ANN_PATH, "StanfordExtra_v12.json")
with open(JSON_PATH) as file:
json_data = json.load(file)
列表中的每个条目都是一个字典,其中包含图像和注释信息。示例实例可以是以下内容:json_data
{'img_path': 'n02091134-whippet/n02091134_3263.jpg',
'img_width': 360,
'img_height': 480,
'img_bbox': [21, 55, 328, 422],
'is_multiple_dogs': False,
'joints': [[175.33333333333334, 453.3333333333333, 1],
[260.0, 367.0, 1],
[248.0, 296.6666666666667, 1],
[337.6666666666667, 302.6666666666667, 1],
[333.0, 265.0, 1],
[329.3333333333333, 231.33333333333334, 1],
[48.666666666666664, 415.0, 1],
[167.0, 340.5, 1],
[182.66666666666666, 280.3333333333333, 1],
[0, 0, 0],
[250.5, 253.0, 0],
[277.0, 211.0, 0],
[297.0, 200.5, 0],
[0, 0, 0],
[263.0, 117.0, 1],
[193.66666666666666, 113.33333333333333, 1],
[238.33333333333334, 182.0, 1],
它具有以下密钥:
img_path:图像文件的路径。
img_width:图像宽度。
img_height:图像高度。
img_box:[x 中的边界框注释分钟、y分钟、宽度、高度] 格式。
is_multiple_dogs:一个布尔值,表示存在单个或多个狗实例。
joints:每个 24 个关键点像素坐标 (x, y) 的列表,每个坐标都与可见性标志 和 相关联。01
seg:运行长度编码 (RLE) 中的分段掩码。
文件:,并由与原始列表相关的训练和验证索引组成。
为简单起见,我们将使用测试数据进行验证。训练集和测试集分别包括 6773 个和 1703 个样本。train_stanford_StanfordExtra_v12.npytest_stanford_StanfordExtra_v12.npyjson_data
"train_stanford_StanfordExtra_v12.npy"))
val_ids = np.load(os.path.join(ANN_PATH,
"test_stanford_StanfordExtra_v12.npy"))
现在,我们将为每个 YOLO 创建训练和验证目录。具体来说,它将具有以下目录结构:
animal-pose-data
├── train
│ ├── images (6773 files)
│ └── labels (6773 files)
└── valid
├── images (1703 files)
└── labels (1703 files)
现在,让我们初始化并创建训练和验证数据的目录路径。
DATA_DIR = "animal-pose-data"
TRAIN_DIR = f"train"
TRAIN_FOLDER_IMG = f"images"
TRAIN_FOLDER_LABELS = f"labels"
TRAIN_IMG_PATH = os.path.join(DATA_DIR, TRAIN_DIR, TRAIN_FOLDER_IMG)
TRAIN_LABEL_PATH = os.path.join(DATA_DIR, TRAIN_DIR, TRAIN_FOLDER_LABELS)
VALID_DIR = f"valid"
VALID_FOLDER_IMG = f"images"
VALID_FOLDER_LABELS = f"labels"
VALID_IMG_PATH = os.path.join(DATA_DIR, VALID_DIR, VALID_FOLDER_IMG)
VALID_LABEL_PATH = os.path.join(DATA_DIR, VALID_DIR, VALID_FOLDER_LABELS)
接下来,我们将使用和使用之前获得的图像和注释数据来收集图像和注释数据。train_idsval_idsjson_data
train_json_data = []
for train_id in train_ids:
train_json_data.append(json_data[train_id])
val_json_data = []
for val_id in val_ids:
val_json_data.append(json_data[val_id])
现在,我们将使用图像路径将图像文件从之前创建的 和 数据复制到相应的文件夹。train_json_dataval_json_dataimagestrainvalid
for data in train_json_data:
img_file = data["img_path"]
filename = img_file.split("/")[-1]
copyfile(os.path.join(IMAGES_DIR, img_file),
os.path.join(TRAIN_IMG_PATH, filename))
for data in val_json_data:
img_file = data["img_path"]
filename = img_file.split("/")[-1]
copyfile(os.path.join(IMAGES_DIR, img_file),
os.path.join(VALID_IMG_PATH, filename))
YOLO__287">创建最终的 YOLO 注释文本文件
我们数据准备的最后一项任务是根据 Ultralytics 的 YOLO 创建框和关键点注释。由于我们将处理单个类(即狗),因此我们将类索引设置为 。0
CLASS_ID = 0
鉴于框和地标处于绝对坐标中,我们需要在相对于图像分辨率的范围内对它们进行归一化。[0, 1]
该函数执行以下任务:create_yolo_boxes_kpts
修改关键点的可见性指示器(将标记关键点的可见性设置为 )。2
规范化边界框和关键点相对于图像尺寸的坐标。
将边界框转换为规范化形式。
def create_yolo_boxes_kpts(img_size, boxes, lm_kpts):
IMG_W, IMG_H = img_size
# Modify kpts with visibilities as 1s to 2s.
vis_ones = np.where(lm_kpts[:, -1] == 1.)
lm_kpts[vis_ones, -1] = 2.
# Normalizing factor for bboxes and kpts.
res_box_array = np.array([IMG_W, IMG_H, IMG_W, IMG_H])
res_lm_array = np.array([IMG_W, IMG_H])
# Normalize landmarks in the range [0,1].
norm_kps_per_img = lm_kpts.copy()
norm_kps_per_img[:, :-1] = norm_kps_per_img[:, :-1] / res_lm_array
# Normalize bboxes in the range [0,1].
norm_bbox_per_img = boxes / res_box_array
# Create bboxes coordinates to YOLO.
# x_c, y_c = x_min + bbox_w/2. , y_min + bbox_h/2.
yolo_boxes = norm_bbox_per_img.copy()
yolo_boxes[:2] = norm_bbox_per_img[:2] + norm_bbox_per_img[2:]/2.
return yolo_boxes, norm_kps_per_img
以下是 的输入参数:create_yolo_boxes_kpts
img_size:指示图像尺寸(宽度、高度)的元组。
boxes:格式中的边界框。[xmin, ymin, width, height]
lm_kpts:具有形状 ( 的 ) 的地标关键点。[24, 3]3[x, y, visibility]
我们最终将根据之前获得的 和 为 YOLO 创建文件。该函数使用上述实用程序函数在 YOLO 中创建所需的注释。txttrain_json_dataval_json_datacreate_yolo_txt_files.txtcreate_yolo_boxes_kpts
def create_yolo_txt_files(json_data, LABEL_PATH):
for data in json_data:
IMAGE_ID = data["img_path"].split("/")[-1].split(".")[0]
IMG_WIDTH, IMG_HEIGHT = data["img_width"], data["img_height"]
landmark_kpts = np.nan_to_num(np.array(data["joints"], dtype=np.float32))
landmarks_bboxes = np.array(data["img_bbox"], dtype=np.float32)
bboxes_yolo, kpts_yolo = create_yolo_boxes_kpts(
(IMG_WIDTH, IMG_HEIGHT),
landmarks_bboxes,
landmark_kpts)
TXT_FILE = IMAGE_ID+".txt"
with open(os.path.join(LABEL_PATH, TXT_FILE), "w") as f:
x_c_norm, y_c_norm, box_width_norm, box_height_norm = round(bboxes_yolo[0],5),\
round(bboxes_yolo[1],5),\
round(bboxes_yolo[2],5),\
round(bboxes_yolo[3],5),\
kps_flattend = [round(ele,5) for ele in kpts_yolo.flatten().tolist()]
line = f"{CLASS_ID} {x_c_norm} {y_c_norm} {box_width_norm} {box_height_norm} "
line+= " ".join(map(str, kps_flattend))
f.write(line)
家 > 关键点检测 >动物姿态估计:微调 YOLOv8 姿态模型
动物姿态估计:微调 YOLOv8 姿态模型
库纳尔黎明库纳尔黎明
SEPTEMBER 19, 2023 5 评论
关键点检测 关键点估计 姿态估计 YOLO
动物后期估计功能gif
动物姿态估计是计算机视觉的一个研究领域,是人工智能的一个子领域,专注于自动检测和分析图像或视频片段中动物的姿势和位置。目标是确定一种或多种动物的身体部位(例如头部、四肢和尾巴)的空间排列。这项技术具有广泛的应用,从研究动物行为和生物力学到野生动物保护和监测。
在这篇博文中,我们将专门处理狗的关键点估计,并向您展示如何微调 Ultralytics 非常流行的 YOLOv8 姿势模型。
微调动物关键点的姿态模型可能具有挑战性,需要微调多个超参数。幸运的是,YOLOv8 在模型微调期间提供了相当多的超参数自定义。准确地说,我们将微调以下 YOLOv8 姿势模型:
斯坦福狗的动物姿势估计数据集
对于我们的动物姿势估计实验,我们将使用斯坦福数据集,该数据集包含 120 个品种的狗,分布在 20,580 张图像中。此外,数据集还包含这些图像的边界框注释。
关键点注释需要通过填写谷歌表单从 StandfordExtra 数据集下载。在 12,538 张图像中提供了 20 个狗姿势关键点的关键点注释(每条腿 3 个,每只耳朵 2 个,尾巴、鼻子和下巴 2 个)。
下载的注释将包含以下结构:
StanfordExtra_V12
├── StanfordExtra_v12.json
├── test_stanford_StanfordExtra_v12.npy
├── train_stanford_StanfordExtra_v12.npy
└── val_stanford_StanfordExtra_v12.npy
训练、验证和测试拆分分别作为原始数据的索引提供,这些数据分别包含 6773、4062 和 1703 图像的注释。StanfordExtra_v12.json
作者还以文件的形式提供了关键点元数据,其中包含动物姿势名称、每个关键点的颜色编码等。但是,它包含 24 个关键点(每个眼睛、喉咙和肩膀各 1 个)的信息。可以使用下图来说明关键点。CSV
用于动物姿势估计的狗标志点
需要微调的狗关键点
在总共 24 个关键点中,只有 20 个存在注释。对于遗漏的 4 个关键点(2 个用于眼睛、喉咙和凋零),坐标标记为 0。
还有一个额外的布尔可见性标志,它与 20 个关键点相关联:
0:不可见
1:可见
用于动物姿态估计的数据集异常
边界框和关键点的真值注释仅适用于单个对象实例。此外,仍然有相当多的不正确的注释,从下面的示例中可以看出。
动物姿态估计的数据异常
数据集异常
边界框和关键点的真值注释仅适用于单个对象实例。此外,仍然有相当多的不正确的注释,从下面的示例中可以看出。
从最左上角的图像中可以看出,边界框和关键点已针对两个不同的对象实例进行了注释。第一行的第二张和第四张图片(从左到右)以及第二行的第一张和第三张图片也反映了这一点。
此外,关键点也被错误地注释了,如第一行的第三张图片所示,下颌和左耳尖被错误地注释。第二行的第一张图像也是如此,其中左耳的尖端被错误标记。第二行的第四张图片中出现了另一个不正确的注释,其中两个耳塞都被贴错了标签。
如前所述,每个图像只有单个实例注释。观察第二行的第二张图片(从左到右),我们只有左边的狗的注释,而有三个狗的实例。
处理跨框和关键点的不匹配的地面实况注释,以进行动物姿态估计
处理不匹配的框和关键点注释的一种直观方法是根据给定的关键点估计矩形。这可以使用实用程序函数来近似给定一组坐标的矩形来完成。请稍等片刻,看看下面的示例。cv2.boundingRect
处理不匹配的注释以进行动物姿势估计
处理不匹配的边界框和关键点批注
尽管边界框并不完美,但使用上述方法处理不匹配的边界框和关键点注释可能成本低廉。我们可以运行一个检测模型,如 YOLOv8 来获得更准确的框注释,然后将关键点与最接近的边界框映射。
但是,我们将坚持使用原始 JSON 文件中提供的注释进行实验。
下载代码为了轻松完成本教程,请单击下面的按钮下载代码。注册完全免费!
下载代码
点击这里下载这篇文章的源代码
为训练和验证数据创建与 YOLOv8 一致的注解
在准备数据之前,我们需要精通 Ultralytics 的 YOLOv8 姿态模型所接受的关键点检测注释格式。以下几点突出显示了用于微调 Ultralytics 的 YOLOv8 Pose 模型的数据集格式:
用于训练YOLO姿态模型的数据集格式如下:
每张图片一个文本文件:数据集中的每张图片都有一个对应的文本文件,其名称和扩展名与图片相同。.txt
每个对象一行:文本文件中的每一行对应于图像中的一个对象实例。
每行对象信息:每行包含有关对象实例的以下信息:
对象类索引:表示对象类的整数(例如,人、汽车等)。01
对象中心坐标:对象中心的 x 和 y 坐标归一化为 和 。01
对象宽度和高度:对象的宽度和高度被规范化为介于 和 之间。01
对象宽度和高度:对象的宽度和高度被规范化为介于 和 之间。01
此外,可见性标志与关键点坐标相关联。它可以包含以下三个值之一:
0:未标记
1:已标记但不可见
2:已标记且可见。
JSON 注释包含一个额外的布尔可见性标志和前面讨论的关键点坐标。我们将所有可见关键点的标志设置为 。2
Ultralytics 中微调姿态模型的关键点注释对应于以下语法:
…
1
0 0.55991 0.503 0.76688 0.918 0.39143 0.91133 2.0 0.44227 0.72467 2.0
条目中的第一项是CLASS_ID,后跟边界框数据(规范化 x中心、y中心、宽度、高度),最后是归一化坐标以及可见性标志(即,对于两个关键点)。[x y]2
下载图像数据和关键点元数据
在开始数据准备之前,我们需要先下载图像数据。让我们定义一个实用程序函数,用于下载和提取包含图像的文件。此外,我们还将下载包含关键点元数据的元数据,例如动物姿势名称、每个关键点的颜色编码等,涵盖所有关键点。images.tarkeypoint_definitions.csv24
def download_and_unzip(url, save_path):
print("Downloading and extracting assets...", end="")
file = requests.get(url)
open(save_path, "wb").write(file.content)
try:
# Extract tarfile.
if save_path.endswith(".tar"):
with tarfile.open(save_path, "r") as tar:
tar.extractall(os.path.split(save_path)[0])
print("Done")
except:
print("Invalid file")
现在让我们指定图像和元数据 URL 并下载它们。
IMAGES_URL = r"http://vision.stanford.edu/aditya86/ImageNetDogs/images.tar"
IMAGES_DIR = "Images"
IMAGES_TAR_PATH = os.path.join(os.getcwd(), f"{IMAGES_DIR}.tar")
ANNS_METADATA_URL = r"https://github.com/benjiebob/StanfordExtra/raw/master/keypoint_definitions.csv"
ANNS_METADATA = "keypoint_definitions.csv"
if not os.path.exists(IMAGES_DIR):
download_and_unzip(IMAGES_URL, IMAGES_TAR_PATH)
os.remove(IMAGES_TAR_PATH)
if not os.path.isfile(ANNS_METADATA):
download_and_unzip(ANNS_METADATA_URL, ANNS_METADATA)
所有下载的图像都将提取到目录中。它具有以下目录结构:Images
Images/
├── n02085620-Chihuahua
│ ├── n02085620_10074.jpg
│ ├── n02085620_10131.jpg
│ └── ...
├── n02085782-Japanese_spaniel
│ ├── n02085782_1039.jpg
│ ├── n02085782_1058.jpg
│ └── n02085782_962.jpg
└── ...
它指定了所有 120 个类别的狗的图像文件。
创建用于动物姿态估计的 YOLO 训练和验证目录
在为动物姿态估计创建训练和验证数据之前,我们需要有注释 JSON 文件。该目录包含文件以及训练、验证和测试拆分。
StanfordExtra_V12StanfordExtra_v12.json
StanfordExtra_V12
├── StanfordExtra_v12.json
├── test_stanford_StanfordExtra_v12.npy
├── train_stanford_StanfordExtra_v12.npy
└── val_stanford_StanfordExtra_v12.npy
现在让我们阅读注释文件。
ANN_PATH = "StanfordExtra_V12"
JSON_PATH = os.path.join(ANN_PATH, "StanfordExtra_v12.json")
with open(JSON_PATH) as file:
json_data = json.load(file)
列表中的每个条目都是一个字典,其中包含图像和注释信息。示例实例可以是以下内容:json_data
{'img_path': 'n02091134-whippet/n02091134_3263.jpg',
'img_width': 360,
'img_height': 480,
'img_bbox': [21, 55, 328, 422],
'is_multiple_dogs': False,
'joints': [[175.33333333333334, 453.3333333333333, 1],
[260.0, 367.0, 1],
[248.0, 296.6666666666667, 1],
[337.6666666666667, 302.6666666666667, 1],
[333.0, 265.0, 1],
[329.3333333333333, 231.33333333333334, 1],
[48.666666666666664, 415.0, 1],
[167.0, 340.5, 1],
[182.66666666666666, 280.3333333333333, 1],
[0, 0, 0],
[250.5, 253.0, 0],
[277.0, 211.0, 0],
[297.0, 200.5, 0],
[0, 0, 0],
[263.0, 117.0, 1],
[193.66666666666666, 113.33333333333333, 1],
[238.33333333333334, 182.0, 1],
[231.66666666666666, 201.33333333333334, 1],
[287.0, 69.61702127659575, 1],
[187.36363636363637, 59.0, 1],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
'seg': ...}
它具有以下密钥:
img_path:图像文件的路径。
img_width:图像宽度。
img_height:图像高度。
img_box:[x 中的边界框注释分钟、y分钟、宽度、高度] 格式。
is_multiple_dogs:一个布尔值,表示存在单个或多个狗实例。
joints:每个 24 个关键点像素坐标 (x, y) 的列表,每个坐标都与可见性标志 和 相关联。01
seg:运行长度编码 (RLE) 中的分段掩码。
文件:,并由与原始列表相关的训练和验证索引组成。
为简单起见,我们将使用测试数据进行验证。训练集和测试集分别包括 6773 个和 1703 个样本。
train_stanford_StanfordExtra_v12.npytest_stanford_StanfordExtra_v12.npyjson_data
train_ids = np.load(os.path.join(ANN_PATH,
"train_stanford_StanfordExtra_v12.npy"))
val_ids = np.load(os.path.join(ANN_PATH,
"test_stanford_StanfordExtra_v12.npy"))
现在,我们将为每个 YOLO 创建训练和验证目录。具体来说,它将具有以下目录结构:
animal-pose-data
├── train
│ ├── images (6773 files)
│ └── labels (6773 files)
└── valid
├── images (1703 files)
└── labels (1703 files)
现在,让我们初始化并创建训练和验证数据的目录路径。
DATA_DIR = "animal-pose-data"
TRAIN_DIR = f"train"
TRAIN_FOLDER_IMG = f"images"
TRAIN_FOLDER_LABELS = f"labels"
TRAIN_IMG_PATH = os.path.join(DATA_DIR, TRAIN_DIR, TRAIN_FOLDER_IMG)
TRAIN_LABEL_PATH = os.path.join(DATA_DIR, TRAIN_DIR, TRAIN_FOLDER_LABELS)
VALID_DIR = f"valid"
VALID_FOLDER_IMG = f"images"
VALID_FOLDER_LABELS = f"labels"
VALID_IMG_PATH = os.path.join(DATA_DIR, VALID_DIR, VALID_FOLDER_IMG)
VALID_LABEL_PATH = os.path.join(DATA_DIR, VALID_DIR, VALID_FOLDER_LABELS)
os.makedirs(TRAIN_IMG_PATH, exist_ok=True)
os.makedirs(TRAIN_LABEL_PATH, exist_ok=True)
os.makedirs(VALID_IMG_PATH, exist_ok=True)
os.makedirs(VALID_LABEL_PATH, exist_ok=True)
接下来,我们将使用和使用之前获得的图像和注释数据来收集图像和注释数据。
train_idsval_idsjson_data
train_json_data = []
for train_id in train_ids:
train_json_data.append(json_data[train_id])
val_json_data = []
for val_id in val_ids:
val_json_data.append(json_data[val_id])
现在,我们将使用图像路径将图像文件从之前创建的 和 数据复制到相应的文件夹。
train_json_dataval_json_dataimagestrainvalid
for data in train_json_data:
img_file = data["img_path"]
filename = img_file.split("/")[-1]
copyfile(os.path.join(IMAGES_DIR, img_file),
os.path.join(TRAIN_IMG_PATH, filename))
for data in val_json_data:
img_file = data["img_path"]
filename = img_file.split("/")[-1]
copyfile(os.path.join(IMAGES_DIR, img_file),
os.path.join(VALID_IMG_PATH, filename))
YOLO__672">创建最终的 YOLO 注释文本文件
我们数据准备的最后一项任务是根据 Ultralytics 的 YOLO 创建框和关键点注释。由于我们将处理单个类(即狗),因此我们将类索引设置为 。0
1
CLASS_ID = 0
鉴于框和地标处于绝对坐标中,我们需要在相对于图像分辨率的范围内对它们进行归一化。[0, 1]
该函数执行以下任务:create_yolo_boxes_kpts
修改关键点的可见性指示器(将标记关键点的可见性设置为 )。2
规范化边界框和关键点相对于图像尺寸的坐标。
将边界框转换为规范化形式。
def create_yolo_boxes_kpts(img_size, boxes, lm_kpts):
IMG_W, IMG_H = img_size
# Modify kpts with visibilities as 1s to 2s.
vis_ones = np.where(lm_kpts[:, -1] == 1.)
lm_kpts[vis_ones, -1] = 2.
# Normalizing factor for bboxes and kpts.
res_box_array = np.array([IMG_W, IMG_H, IMG_W, IMG_H])
res_lm_array = np.array([IMG_W, IMG_H])
# Normalize landmarks in the range [0,1].
norm_kps_per_img = lm_kpts.copy()
norm_kps_per_img[:, :-1] = norm_kps_per_img[:, :-1] / res_lm_array
# Normalize bboxes in the range [0,1].
norm_bbox_per_img = boxes / res_box_array
# Create bboxes coordinates to YOLO.
# x_c, y_c = x_min + bbox_w/2. , y_min + bbox_h/2.
yolo_boxes = norm_bbox_per_img.copy()
yolo_boxes[:2] = norm_bbox_per_img[:2] + norm_bbox_per_img[2:]/2.
return yolo_boxes, norm_kps_per_img
以下是 的输入参数:create_yolo_boxes_kpts
img_size:指示图像尺寸(宽度、高度)的元组。
boxes:格式中的边界框。[xmin, ymin, width, height]
lm_kpts:具有形状 ( 的 ) 的地标关键点。[24, 3]3[x, y, visibility]
我们最终将根据之前获得的 和 为 YOLO 创建文件。该函数使用上述实用程序函数在 YOLO 中创建所需的注释。txttrain_json_dataval_json_datacreate_yolo_txt_files.txtcreate_yolo_boxes_kpts
def create_yolo_txt_files(json_data, LABEL_PATH):
for data in json_data:
IMAGE_ID = data["img_path"].split("/")[-1].split(".")[0]
IMG_WIDTH, IMG_HEIGHT = data["img_width"], data["img_height"]
landmark_kpts = np.nan_to_num(np.array(data["joints"], dtype=np.float32))
landmarks_bboxes = np.array(data["img_bbox"], dtype=np.float32)
bboxes_yolo, kpts_yolo = create_yolo_boxes_kpts(
(IMG_WIDTH, IMG_HEIGHT),
landmarks_bboxes,
landmark_kpts)
TXT_FILE = IMAGE_ID+".txt"
with open(os.path.join(LABEL_PATH, TXT_FILE), "w") as f:
x_c_norm, y_c_norm, box_width_norm, box_height_norm = round(bboxes_yolo[0],5),\
round(bboxes_yolo[1],5),\
round(bboxes_yolo[2],5),\
round(bboxes_yolo[3],5),\
kps_flattend = [round(ele,5) for ele in kpts_yolo.flatten().tolist()]
line = f"{CLASS_ID} {x_c_norm} {y_c_norm} {box_width_norm} {box_height_norm} "
line+= " ".join(map(str, kps_flattend))
f.write(line)
它接受以下参数:
json_data:每个词典包含图像元数据的词典列表,包括图像尺寸、关键点(关节)和边界框 (img_bbox)。
LABEL_PATH:保存文本文件的路径。
注意:我们使用 NumPy 将带有 s 的关键点坐标转换为 0s。nan_to_numNaN
以下示例显示了一个这样的实例,其中关键点坐标为 NaNs。
'joints': [[423.5, 224.75, 1.0],
[285.0, 284.0, 1.0],
[265.0, 232.0, 0.0],
[nan, nan, 0.0],
[137.0, 238.0, 0.0],
[153.0, 221.0, 0.0],
[111.0, 212.6, 1.0],
[75.0, 270.0, 0.0],
[nan, nan, 0.0],
[100.0, 234.0, 1.0],
[nan, nan, 0.0],
[nan, nan, 0.0],
[87.0, 224.0, 0.0],
[79.0, 218.0, 0.0],
[312.6666666666667, 156.5, 1.0],
[172.0, 133.83333333333334, 1.0],
[223.5, 264.0, 1.0],
[215.5, 304.8333333333333, 1.0],
[nan, nan, 0.0],
[nan, nan, 0.0],
[nan, nan, 0.0],
[nan, nan, 0.0],
[nan, nan, 0.0],
[nan, nan, 0.0]]
现在,我们将创建训练和验证注释。
create_yolo_txt_files(train_json_data, TRAIN_LABEL_PATH)
create_yolo_txt_files(val_json_data, VALID_LABEL_PATH)
YOLO__787">可视化来自 YOLO 注释的数据
一旦我们创建了与YOLO兼容的数据,我们就可以可视化一些地面实况样本,以确保我们的转换是正确的。
在可视化样本之前,我们可以将可用的十六进制颜色编码映射到 RGB 值。keypoint_definitions.csv
ann_meta_data = pd.read_csv("keypoint_definitions.csv")
COLORS = ann_meta_data["Hex colour"].values.tolist()
COLORS_RGB_MAP = []
for color in COLORS:
R, G, B = int(color[:2], 16), int(color[2:4], 16), int(color[4:], 16)
COLORS_RGB_MAP.append({color: (R,G,B)})
该函数用于使用 对图像上相应的地标点进行注释。draw_landmarksCOLORS_RGB_MAP
def draw_landmarks(image, landmarks):
radius = 5
# Check if image width is greater than 1000 px.
# To improve visualization.
if (image.shape[1] > 1000):
radius = 8
for idx, kpt_data in enumerate(landmarks):
loc_x, loc_y = kpt_data[:2].astype("int").tolist()
color_id = list(COLORS_RGB_MAP[int(kpt_data[-1])].values())[0]
cv2.circle(image,
(loc_x, loc_y),
radius,
color=color_id[::-1],
thickness=-1,
lineType=cv2.LINE_AA)
return image
该函数用于注释边界框以及图像上的置信度分数(如果通过)。draw_boxes
def draw_boxes(image, detections, class_name = "dog", score=None, color=(0,255,0)):
font_size = 0.25 + 0.07 * min(image.shape[:2]) / 100
font_size = max(font_size, 0.5)
font_size = min(font_size, 0.8)
text_offset = 3
thickness = 2
# Check if image width is greater than 1000 px.
# To improve visualization.
if (image.shape[1] > 1000):
thickness = 10
xmin, ymin, xmax, ymax = detections[:4].astype("int").tolist()
conf = round(float(detections[-1]),2)
cv2.rectangle(image,
(xmin, ymin),
(xmax, ymax),
color=(0,255,0),
thickness=thickness,
lineType=cv2.LINE_AA)
display_text = f"{class_name}"
if score is not None:
display_text+=f": {score:.2f}"
(text_width, text_height), _ = cv2.getTextSize(display_text,
cv2.FONT_HERSHEY_SIMPLEX,
font_size, 2)
cv2.rectangle(image,
(xmin, ymin),
(xmin + text_width + text_offset, ymin - text_height - int(15 * font_size)),
color=color, thickness=-1)
image = cv2.putText(
image,
display_text,
现在,我们有了注释地标和边界框的实用程序。但是,我们需要绝对坐标(框和关键点)来在图像上注释它们 - 该实用程序在将注释转换为绝对坐标后绘制注释。visualize_annotations
回想一下,边界框坐标和关键点在 范围内被归一化。但是,要绘制它们,我们需要绝对坐标。[0, 1]
从 YOLO bboxes 到 的转换映射非常简单,可以使用以下公式集获得:[xmin, ymin, xmax, ymax]
x
m
i
n
=
W
2
(
2
x
c
e
n
t
e
r
−
w
i
d
t
h
)
x_{min} = \frac{W}{2} (2x_{center} \ - \ width)
xmin=2W(2xcenter − width)
y
m
i
n
=
H
2
(
2
y
c
e
n
t
e
r
−
h
e
i
g
h
t
)
y_{min} = \frac{H}{2} (2y_{center} \ - \ height)
ymin=2H(2ycenter − height)
x
m
a
x
=
x
m
i
n
+
宽度
∗
W
x_{max} = x_{min} + 宽度 * W
xmax=xmin+宽度∗W
y
m
a
x
=
y
m
i
n
+
高度
∗
H
y_{max} = y_{min} + 高度 * H
ymax=ymin+高度∗H
同样,可以使用以下公式对关键点进行非规范化(到绝对坐标):
x
a
b
s
=
x
n
o
r
m
∗
W
x_{abs} = x_{norm}* W
xabs=xnorm∗W
y
a
b
s
=
y
n
o
r
m
∗
H
y_{abs} = y_{norm}* H
yabs=ynorm∗H
这里,and 分别是框的宽度和高度,而 and 分别是图像的宽度和高度。widthheightWH
def visualize_annotations(image, box_data, keypoints_data):
image = image.copy()
shape_multiplier = np.array(image.shape[:2][::-1]) # (W, H).
# Final absolute coordinates (xmin, ymin, xmax, ymax).
denorm_boxes = np.zeros_like(box_data)
# De-normalize center coordinates from YOLO to (xmin, ymin).
denorm_boxes[:, :2] = (shape_multiplier/2.) * (2*box_data[:,:2] - box_data[:,2:])
# De-normalize width and height from YOLO to (xmax, ymax).
denorm_boxes[:, 2:] = denorm_boxes[:,:2] + box_data[:,2:]*shape_multiplier
for boxes, kpts in zip(denorm_boxes, keypoints_data):
# De-normalize landmark coordinates.
kpts[:, :2]*= shape_multiplier
image = draw_boxes(image, boxes)
image = draw_landmarks(image, kpts)
下图显示了一些图像样本及其相应的地面实况注释。关键点批注根据其相应的可见性标志进行筛选。
在我们的实验中,我们将使用 YOLOv8m-pose 和 YOLOv8l-pose 模型。
训练配置
我们将定义训练配置,以便在课堂上进行微调。
TrainingConfig
@dataclass(frozen=True)
class TrainingConfig:
DATASET_YAML: str = "animal-keypoints.yaml"
MODEL: str = "yolov8m-pose.pt"
EPOCHS: int = 100
KPT_SHAPE: tuple = (24,3)
PROJECT: str = "Animal_Keypoints"
NAME: str = f"{MODEL.split('.')[0]}_{EPOCHS}_epochs"
CLASSES_DICT: dict = field(default_factory = lambda:{0 : "dog"})
观察 (keypoint shape) 参数。 表示要训练的关键点数,同时指示坐标和“可见性”标志。KPT_SHAPE243x-y
数据配置
该类采用与数据相关的各种超参数,例如训练时要使用的图像大小和批大小,以及各种增强概率,例如马赛克、水平翻转等。DatasetConfig
@dataclass(frozen=True)
class DatasetConfig:
IMAGE_SIZE: int = 640
BATCH_SIZE: int = 16
CLOSE_MOSAIC: int = 10
MOSAIC: float = 0.4
FLIP_LR: float = 0.0 # Turn off horizontal flip.
接下来,我们实例化 和 类。TrainingConfigDatasetConfig
2
train_config = TrainingConfig()
data_config = DatasetConfig()
在开始训练之前,我们需要创建一个包含图像和标签文件的路径。我们还需要指定类名、起始点和关键点形状。yamlindex=0
如果关键点沿参考点或一组参考点对称(例如,鼻子的一组关键点可以用作面部的参考点),我们也可以提供参数。flip_idx
例如,如果我们假设面部特征的五个关键点:[左眼、右眼、鼻子、左嘴、右嘴],并且原始索引是 ,那么flip_idx是 。当水平翻转用作数据增强时,这是必不可少的。[0, 1, 2, 3, 4][1, 0, 2, 4, 3]
注意:我们已经关闭了实验的水平(LR翻转)。
current_dir = os.getcwd()
data_dict = dict(
path = os.path.join(current_dir, DATA_DIR),
train = os.path.join(TRAIN_DIR, TRAIN_FOLDER_IMG),
val = os.path.join(VALID_DIR, VALID_FOLDER_IMG),
names = train_config.CLASSES_DICT,
kpt_shape = list(train_config.KPT_SHAPE),
)
with open(train_config.DATASET_YAML, "w") as config_file:
yaml.dump(data_dict, config_file)
动物姿势估计的微调和训练
最后,我们将使用上面定义的配置进行训练。
pose_model = model = YOLO(train_config.MODEL)
pose_model.train(data = train_config.DATASET_YAML,
epochs = train_config.EPOCHS,
imgsz = data_config.IMAGE_SIZE,
batch = data_config.BATCH_SIZE,
project = train_config.PROJECT,
name = train_config.NAME,
close_mosaic = data_config.CLOSE_MOSAIC,
mosaic = data_config.MOSAIC,
fliplr = data_config.FLIP_LR
)
YOLOv8_994">YOLOv8在动物姿态估计中的评价
回想一下,在目标检测中,交并集 (IoU) 对于查找两个框之间的相似性以及计算平均精度精度 (mAP) 至关重要。它与关键点估计类似,是对象关键点相似性 (OKS)。
OKS 的定义如下: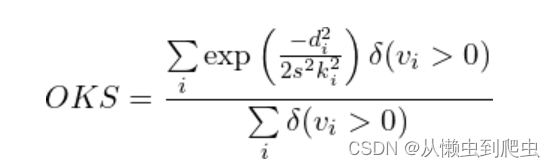
d我是真值与预测关键点 i 之间的欧几里得距离
k 是关键点 i 的常数
s 是真值对象的比例尺;s2因此成为对象的分割区域。
v我是关键点的真值可见性标志i
δ(v我> 0)是狄拉克-德尔塔函数,其计算方式就好像关键点被标记一样,否则1i0
查看我们最近的文章,其中我们深入讨论了对象关键点相似性 (OKS)。
使用上面的配置,我们获得了 YOLOv8m 的以下指标:
Box 指标:
mAP@50: 0.991
map@50-95:0.922
姿势指标:
mAP@50: 0.937
map@50-95:0.497
下图显示了 YOLOv8m 的指标。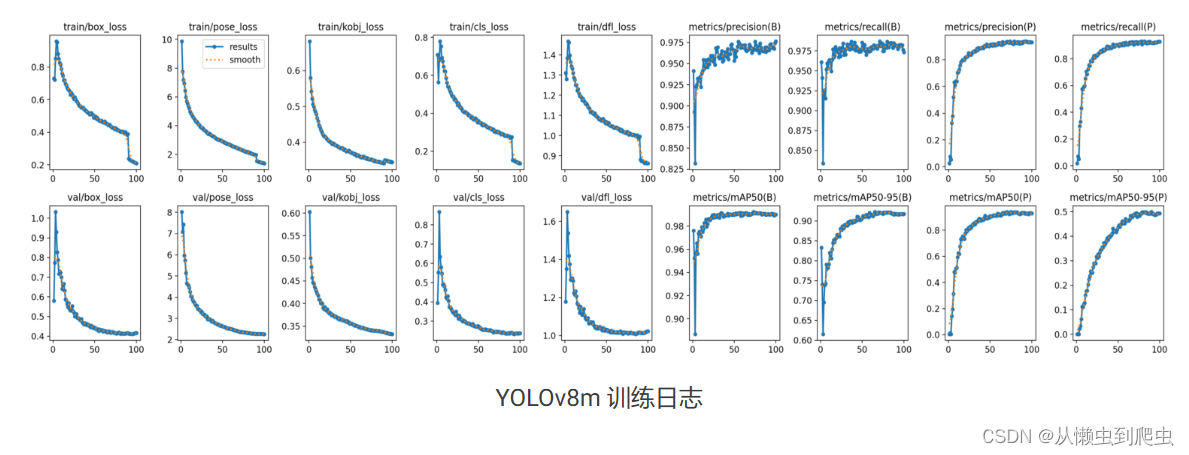
以下是使用与训练 YOLOv8m 相同的超参数设置的 YOLOv8l 的指标:
Box 指标:
mAP@50: 0.992
map@50-95:0.932
姿势指标:
mAP@50: 0.941
map@50-95:0.509
下图显示了 YOLOv8l 的日志: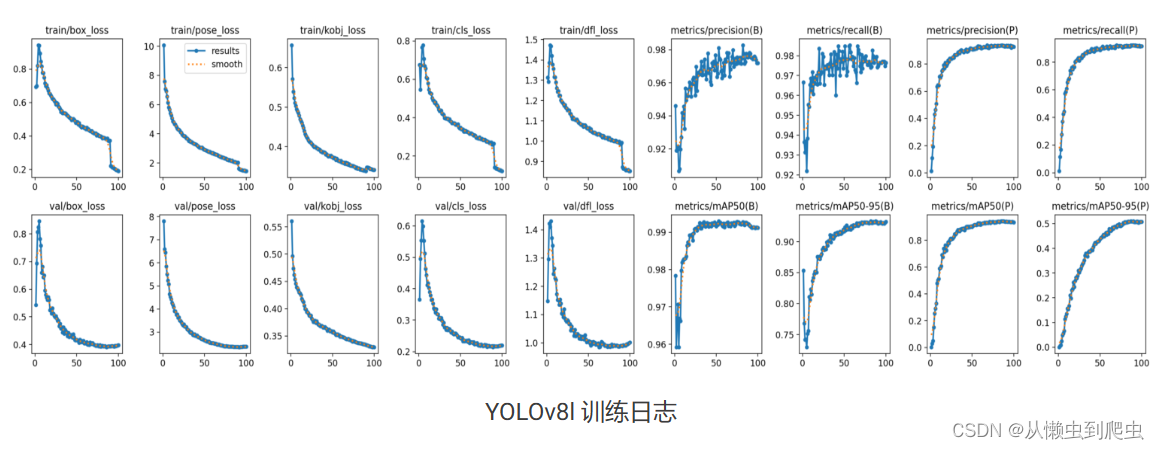
观察 box、cls、dfl 的急剧下降,并在第 90 纪元后造成损失。这正是马赛克增强被关闭的时候!
您还可以查看 YOLOv8m 和 YOLOv8l 的 tensorboard 训练日志。
图像预测的可视化##
该函数获取相应图像的预测框、置信度分数和关键点。它接受以下阈值:prepare_predictions
BOX_IOU_THRESH:过滤掉大于此阈值的重叠边界框。
“BOX_CONF_THRESH”:筛选置信度分数低于此阈值的框。
KPT_CONF_THRESH:过滤置信度分数低于阈值的关键点坐标。
def prepare_predictions(
image_dir_path,
image_filename,
model,
BOX_IOU_THRESH = 0.55,
BOX_CONF_THRESH=0.30,
KPT_CONF_THRESH=0.68):
image_path = os.path.join(image_dir_path, image_filename)
image = cv2.imread(image_path).copy()
results = model.predict(image_path, conf=BOX_CONF_THRESH, iou=BOX_IOU_THRESH)[0].cpu()
if not len(results.boxes.xyxy):
return image
# Get the predicted boxes, conf scores and keypoints.
pred_boxes = results.boxes.xyxy.numpy()
pred_box_conf = results.boxes.conf.numpy()
pred_kpts_xy = results.keypoints.xy.numpy()
pred_kpts_conf = results.keypoints.conf.numpy()
# Draw predicted bounding boxes, conf scores and keypoints on image.
for boxes, score, kpts, confs in zip(pred_boxes, pred_box_conf, pred_kpts_xy, pred_kpts_conf):
kpts_ids = np.where(confs > KPT_CONF_THRESH)[0]
filter_kpts = kpts[kpts_ids]
filter_kpts = np.concatenate([filter_kpts, np.expand_dims(kpts_ids, axis=-1)], axis=-1)
image = draw_boxes(image, boxes, score=score)
image = draw_landmarks(image, filter_kpts)
以下是 YOLOv8m 姿态模型的预测样本。
下图表示 YOLOv8l 姿态模型的可视化效果。
比较两个推理样本,即使 YOLOv8l 的指标略高,YOLOv8m 的性能似乎也略高于 YOLOv8l。
我们可以从下面的视频示例中确认这一点。
从样本图像和视频推断中,我们可以观察到模型仍有改进的空间,因为关键点预测,尤其是耳塞和尾部,不是最优的。通过解决我们之前讨论的数据集异常,可以显著改进预测。
结论
在本文中,我们了解了如何微调 YOLOv8 以进行动物姿态估计。我们还看到现有数据集中存在异常,这可能阻碍了模型学习,这从样本推断中可以明显看出。
可以通过正确标记注释来缓解异常,这可以改善现有模型的指标。
此外,我们还看到 YOLOv8 medium 在可视化方面的表现优于 YOLOv8 large,尽管指标略高于 YOLOv8m。