文章目录
- 简介
- 整体介绍
- 整体架构图
- 网络架构的改进
- Backbone 的改进
- FPN
- Anchor 机制
- 坐标表示与样本匹配
- 目标边界框的预测
- 正负样本匹配
- 损失函数
简介
关注目标在哪里
目标是什么
目标检测的发展路径:
proposal 两阶段 --> anchor-base/ anchor-free --> nms free
小目标、跨域?
整体介绍

1、YOLOv3在实时性和精确性在当时都是做的比较好的,并在工业界得到了广泛应用。
2、YOLOv3在Backbone网络结构上应用残差连接思想来解决深度网络的梯度消失问题。
yolov2 使用的是 darknet 19, 类似于 vgg。
3、YOLOv3最显著的改进就是在3个尺度上以相同的方式进行目标的检测。这使其可以检测到不同规模的目标。(最涨点)
4、YOLOv3在损失函数是将之前使用的Softmax修改为Logit;
5、最后推理阶段YOLOv3对3个检测层的预测结果进行非最大抑制(NMS)确定最终的检测结果。
整体架构图




网络架构的改进
Backbone 的改进
YOLOv3是基于DarkNet53进行构建的,对比一下VGG、DarkNet19、ResNet101以及DarkNet53;
首先对比Plain Model,可以看到DarkNet19相对于VGG16有更少的参数量,同时也具有更快的速度和更高的精度(6.2ms vs 9.4ms)
而对于具有残差结构的ResNet101和DarkNet53,在具有类似精度的情况下,DarkNet53具有更高的精度和更快的速度(13.7ms vs 20.0ms)

为什么DarkNet19能够在较少参数的情况下,保持了精度同时还具有较快的速度?
较少参数量:DarkNet19使用1×1卷积代替了FC,很大程度减少了参数量,同时DarkNet19在连续卷积块中使用了1×1卷积进行通道的缩减,而VGG系列均使用了3×3卷积,同时通道没有变化,这一操作也减少了参数量;
较快的速度:也是因为FC层,1×1卷积的Bottleneck设计也会有速度上的优势(不是主要原因);
精度的保持:DarkNet19在后期通道也是增长了,而VGG系列最后一个Block的通道数是没有变化的,这也只是可能的一个因素,这也说明了另一件事VGG系列可能出现了过拟合的现象(个人见解)

为什么VGG系列以及DarkNet19当年为什么网络最深只到19层?
VGG论文当年只给出了VGG19作为最深的模型,而DarkNet19也是19层,为什么?
这个疑惑在何恺明大神的ResNet论文中得到了答案,就是对于Plain模型,网络越深,训练误差和测试误差越大,精度可能相较于浅层网络还会有所下降。因为随着网络的加深,会出现梯度的弥散,很多特征会消失在深层网络,导致结果没办法呈现到最佳的效果。

什么是残差连接?为什么对梯度消失有效?带来了什么效果?
残差结构如下图所示,其原理主要是把卷积层前后的特征进行元素相加求和,如果特征是在这其中的某一个卷积后消失的,那么残差结构便可以找回丢失的特征。
如下图所示,左图为没有使用残差结构的plain模型,右图是使用了残差结构的残差网络ResNet,可以看到使用了残差结构的模型,随着模型深度的增加,误差随着训练的迭代进行也是降低的。

YOLOv3作者为什么重新设计DarkNet53,而不是直接使用ResNet呢?DarkNet53与ResNet又有什么不同呢?
对于YOLOv3来说,主要是为了在追求精度的同时也要保证一定的实时性,而ResNet在某种程度上还是比较大的,可能会影响速度。
这里按照精度相似的ResNet101与DarkNet53进行对比:
相同点:都用了Stride=2的3×3卷积代替Max-pooling操作,也都用了残差结构的思想来设计主干模型;
不同点:在堆叠的残差块中,DarkNet53仅仅堆叠了2个卷积作为Block,而ResNet101使用了3个卷积层,DarkNet53最后一个Stage的通道数是ResNet101的0.5倍,最后一个便是每个Stage的残差块数量DarkNet53的设计更为均衡合理(1,2,8,8,4 vs 3,4,23,3),这也暗示ResNet101的设计有一定的冗余。
ResNet

Darkenet-53

FPN
之前的一些结构
- 手工设计的特征:自己手动修改输入图的大小,从而得到不同的特征
- SSD 虽然设计了金字塔,但是增加了很多卷积层,增大了参数量
- 高分辨率特征图具有低层次的特征,这也损害了其对目标识别的表征能力
FPN 的设计
- 重用特征,减少参数量
- 融合低分辨率语义信息较强的特征图和高分辨率语义信息较弱但空间信息丰富的特征图。
- 以特征金字塔为基础结构上,对每一层的特征图分别进行预测

YOLOv3的FPN是怎么做的呢?
为了进一步降低模型的复杂度进而提升速度,YOLOv3选择了重用Backbone所提取的不同Level的特征图,主要是8倍、16倍以及32倍下采样的特征图,同时采用了FPN 的设计思想,分别对16倍、32倍以及各自上采样后的结果进行了融合,但是也对其进行了一定的改进,就是将特征融合的操作由Add改为了Concat。相加可能会掩盖一些特征性,而concat则可以保持梯度的丰富性。后续的yolo也延续了这个改进。


Anchor 机制
如果输入的是416×416的3通道图像,YOLOv3会产生3个尺度的特征图,分别为:13×13、26×26、52×52,也对应着Grid Cell个数,即总共产生13×13+26×26+52×52个Grid Cell。对于每个Grid Cell,对应3个Anchor Box,于是,最终产生了(13×13+26×26+52×52)×3=10647个预测框。
其中不同尺度特征图对应的预测框相对预测的目标大小规模也不一样,具体如下:
- 13×13预测大目标
- 26×26预测中目标
- 52×52预测小目标
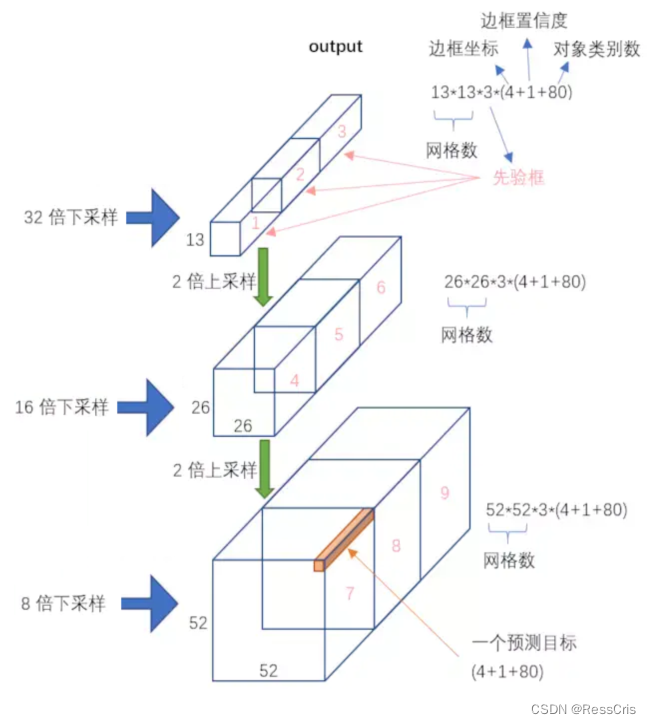

对于每个Grid Cell,其都对应一个85维度的Tensor(80+5=80+4+1,也就是数据集的类别数量+坐标值+目标值)
5=4+1 :中心点坐标、宽、高,置信度
80 :80个类别的类别概率(COCO数据集的类别是80个);

坐标表示与样本匹配
目标边界框的预测
如何更好地衡量两点之间的相对位置?
YOLOv3采用直接预测相对位置的方法预测出bbox中心点相对于Grid Cell左上角的相对坐标。直接预测出(tx,ty,tw,th,t0),然后通过以下坐标偏移公式计算得到bbox的位置大小和置信度:
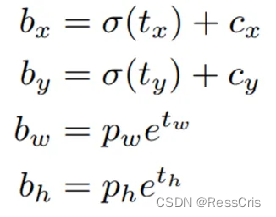
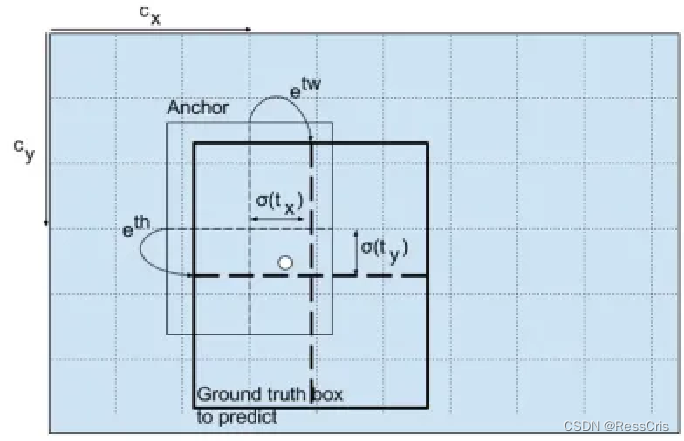
tx、ty、tw、th就是模型的预测输出。cx和cy表示Grid Cell的坐标;
比如某层的特征图大小是13×13,那么Grid Cell就有13×13个,第0行第1列的Grid Cell的坐标cx就是0,cy就是1。pw和ph表示预测前bbox的size。bx、by、bw和bh就是预测得到的bbox的中心的坐标和宽高。
在训练这几个坐标值的时候采用了平方和损失,因为这种方式的误差可以很快的计算出来。
正负样本匹配
在YOLOv3论文中提到正负样本的匹配规则是给每一个GT分配一个正样本,这个正样本是所有bbox中找一个与GT的重叠区域最大的一个预测框,也就是和该GT的IOU最大的预测框。
如果一个样本不是正样本,那么它既没有定位损失,也没有类别损失,只有置信度损失,在YOLOv3的论文中作者尝试用Focal Loss来缓解正负样本不均匀的问题,但是并没有取得很好的效果,原因就在于负样本值参与了置信度损失,对Loss的影响占比很小。
但是这么做也有一个缺点,就是用这个匹配规则去寻找正样本,正样本的数量是很少的,这将使得网络难以训练。
损失函数
在YOLOv3中,loss分为3个部分:
1、xywh误差,也就是bbox loss;
2、置信度误差,也就是obj loss;
3、类别误差,也就是class loss;
在代码中分别对应lbox,lobj,lcls,YOLOv3中使用的loss公式如下:

其中: