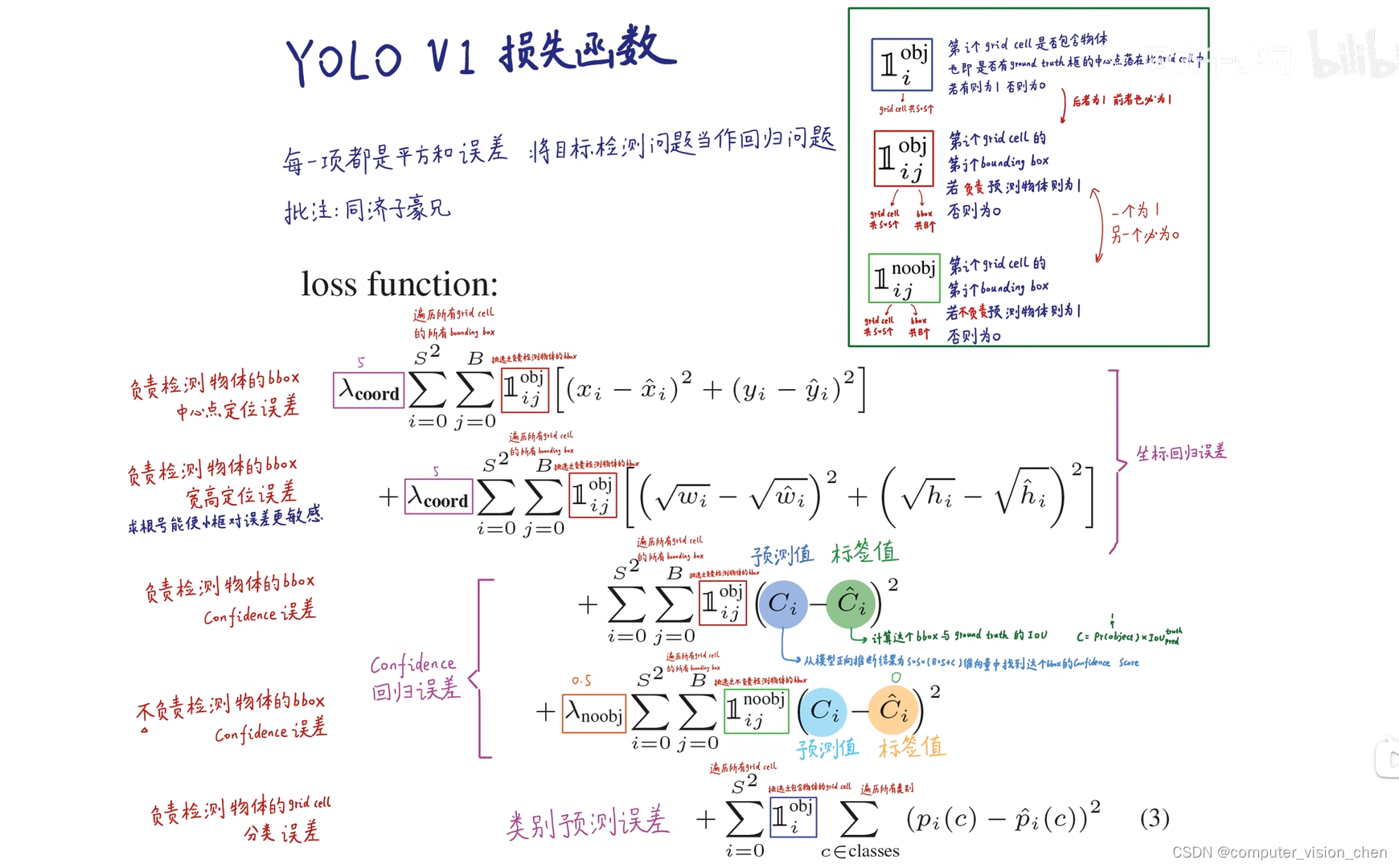

python">1.计算预测中心点与真实中心点的损失。
2.计算预测的宽高与真实宽高的损失。
用根号,是使得小框对误差更敏感。
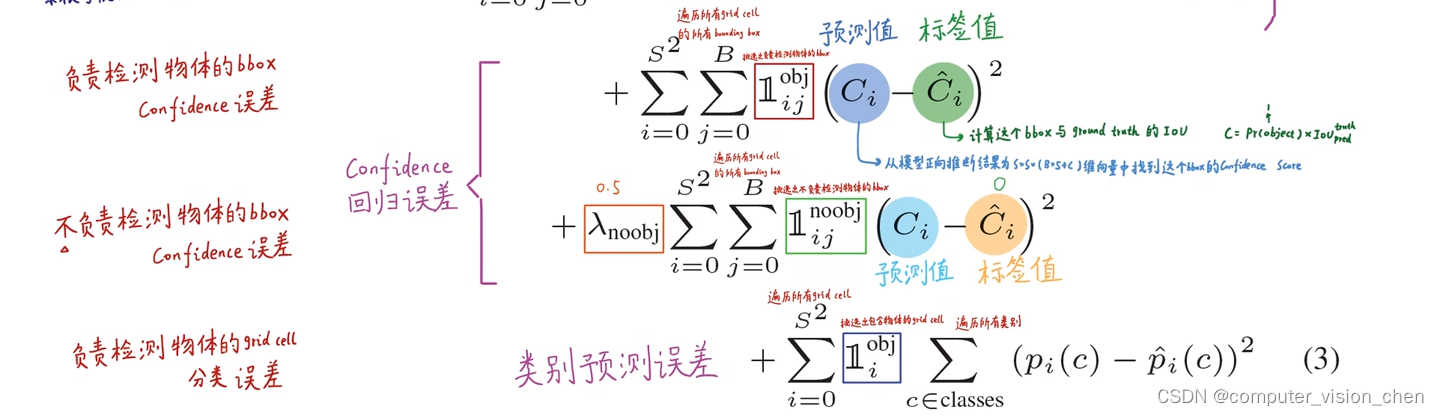
第三项负责计算置信度的误差
标签值是预测框真实框的IOU,作为标签值。
第四项是不负责检测目标的框,让它们的Loss值越小越好。让他们的权重小一些,因为他们比较多。
第五项:负责检测物体那个框的分类误差。比如真实框类别标注是狗,那么预测的类别是狗的概率让它越来越接近1。
python">import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import warnings
warnings.filterwarnings('ignore') # 忽略警告消息
CLASS_NUM = 20 # (使用自己的数据集时需要更改)
class yoloLoss(nn.Module):
def __init__(self, S, B, l_coord, l_noobj):
# 一般而言 l_coord = 5 , l_noobj = 0.5
super(yoloLoss, self).__init__()
self.S = S # S = 7
self.B = B # B = 2
self.l_coord = l_coord
self.l_noobj = l_noobj
def compute_iou(self, box1, box2): # box1(2,4) box2(1,4)
N = box1.size(0) # 2
M = box2.size(0) # 1
lt = torch.max( # 返回张量所有元素的最大值
# [N,2] -> [N,1,2] -> [N,M,2]
box1[:, :2].unsqueeze(1).expand(N, M, 2),
# [M,2] -> [1,M,2] -> [N,M,2]
box2[:, :2].unsqueeze(0).expand(N, M, 2),
)
rb = torch.min(
# [N,2] -> [N,1,2] -> [N,M,2]
box1[:, 2:].unsqueeze(1).expand(N, M, 2),
# [M,2] -> [1,M,2] -> [N,M,2]
box2[:, 2:].unsqueeze(0).expand(N, M, 2),
)
wh = rb - lt # [N,M,2]
wh[wh < 0] = 0 # clip at 0
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] 重复面积
area1 = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1]) # [N,]
area2 = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1]) # [M,]
area1 = area1.unsqueeze(1).expand_as(inter) # [N,] -> [N,1] -> [N,M]
area2 = area2.unsqueeze(0).expand_as(inter) # [M,] -> [1,M] -> [N,M]
iou = inter / (area1 + area2 - inter)
return iou # [2,1]
def forward(self, pred_tensor, target_tensor):
'''
pred_tensor: (tensor) size(batchsize,7,7,30)
target_tensor: (tensor) size(batchsize,7,7,30) --- ground truth
'''
N = pred_tensor.size()[0] # batchsize
coo_mask = target_tensor[:, :, :, 4] > 0 # 具有目标标签的索引值 true batchsize*7*7
noo_mask = target_tensor[:, :, :, 4] == 0 # 不具有目标的标签索引值 false batchsize*7*7
coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor) # 得到含物体的坐标等信息,复制粘贴 batchsize*7*7*30
noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor) # 得到不含物体的坐标等信息 batchsize*7*7*30
coo_pred = pred_tensor[coo_mask].view(-1, int(CLASS_NUM + 10)) # view类似于reshape
box_pred = coo_pred[:, :10].contiguous().view(-1, 5) # 塑造成X行5列(-1表示自动计算),一个box包含5个值
class_pred = coo_pred[:, 10:] # [n_coord, 20]
coo_target = target_tensor[coo_mask].view(-1, int(CLASS_NUM + 10))
box_target = coo_target[:, :10].contiguous().view(-1, 5)
class_target = coo_target[:, 10:]
# 不包含物体grid ceil的置信度损失
noo_pred = pred_tensor[noo_mask].view(-1, int(CLASS_NUM + 10))
noo_target = target_tensor[noo_mask].view(-1, int(CLASS_NUM + 10))
noo_pred_mask = torch.cuda.ByteTensor(noo_pred.size()).bool()
noo_pred_mask.zero_()
noo_pred_mask[:, 4] = 1
noo_pred_mask[:, 9] = 1
noo_pred_c = noo_pred[noo_pred_mask] # noo pred只需要计算 c 的损失 size[-1,2]
noo_target_c = noo_target[noo_pred_mask]
nooobj_loss = F.mse_loss(noo_pred_c, noo_target_c, size_average=False) # 均方误差
# compute contain obj loss
coo_response_mask = torch.cuda.ByteTensor(box_target.size()).bool() # ByteTensor 构建Byte类型的tensor元素全为0
coo_response_mask.zero_() # 全部元素置False bool:将其元素转变为布尔值
no_coo_response_mask = torch.cuda.ByteTensor(box_target.size()).bool() # ByteTensor 构建Byte类型的tensor元素全为0
no_coo_response_mask.zero_() # 全部元素置False bool:将其元素转变为布尔值
box_target_iou = torch.zeros(box_target.size()).cuda()
# box1 = 预测框 box2 = ground truth
for i in range(0, box_target.size()[0], 2): # box_target.size()[0]:有多少bbox,并且一次取两个bbox
box1 = box_pred[i:i + 2] # 第一个grid ceil对应的两个bbox
box1_xyxy = Variable(torch.FloatTensor(box1.size()))
box1_xyxy[:, :2] = box1[:, :2] / float(self.S) - 0.5 * box1[:, 2:4] # 原本(xc,yc)为7*7 所以要除以7
box1_xyxy[:, 2:4] = box1[:, :2] / float(self.S) + 0.5 * box1[:, 2:4]
box2 = box_target[i].view(-1, 5)
box2_xyxy = Variable(torch.FloatTensor(box2.size()))
box2_xyxy[:, :2] = box2[:, :2] / float(self.S) - 0.5 * box2[:, 2:4]
box2_xyxy[:, 2:4] = box2[:, :2] / float(self.S) + 0.5 * box2[:, 2:4]
iou = self.compute_iou(box1_xyxy[:, :4], box2_xyxy[:, :4])
max_iou, max_index = iou.max(0)
max_index = max_index.data.cuda()
coo_response_mask[i + max_index] = 1 # IOU最大的bbox
no_coo_response_mask[i + 1 - max_index] = 1 # 舍去的bbox
# confidence score = predicted box 与 the ground truth 的 IOU
box_target_iou[i + max_index, torch.LongTensor([4]).cuda()] = max_iou.data.cuda()
box_target_iou = Variable(box_target_iou).cuda()
# 置信度误差(含物体的grid ceil的两个bbox与ground truth的IOU较大的一方)
box_pred_response = box_pred[coo_response_mask].view(-1, 5)
box_target_response_iou = box_target_iou[coo_response_mask].view(-1, 5)
# IOU较小的一方
no_box_pred_response = box_pred[no_coo_response_mask].view(-1, 5)
no_box_target_response_iou = box_target_iou[no_coo_response_mask].view(-1, 5)
no_box_target_response_iou[:, 4] = 0 # 保险起见置0(其实原本就是0)
box_target_response = box_target[coo_response_mask].view(-1, 5)
# 含物体grid ceil中IOU较大的bbox置信度损失
contain_loss = F.mse_loss(box_pred_response[:, 4], box_target_response_iou[:, 4], size_average=False)
# 含物体grid ceil中舍去的bbox损失
no_contain_loss = F.mse_loss(no_box_pred_response[:, 4], no_box_target_response_iou[:, 4], size_average=False)
# bbox坐标损失
loc_loss = F.mse_loss(box_pred_response[:, :2], box_target_response[:, :2], size_average=False) + F.mse_loss(
torch.sqrt(box_pred_response[:, 2:4]), torch.sqrt(box_target_response[:, 2:4]), size_average=False)
# 类别损失
class_loss = F.mse_loss(class_pred, class_target, size_average=False)
return (self.l_coord * loc_loss + contain_loss + self.l_noobj * (nooobj_loss + no_contain_loss) + class_loss) / N