博客【opencv dnn模块 示例(3) 目标检测 object_detection (2) YOLO object detection】 测试了yolov3 及之前系列的模型,有在博客【opencv dnn模块 示例(15) opencv4.2版本dnn支持cuda加速(vs2015异常解决)】 说明了如何使用dnn模块进行cuda加速推理。
本文说明yolo v4的网络改进和测试情况。
文章目录
- 1、前言
- 2、Yolo v4
- 2.1、网络结构
- 2.1.1、跨阶段部分网络(Cross Stage Partial Networks,CSPNet)
- 2.1.2、空间金字塔池化网络(Spatial Pyramid Pooling Network,SPPNet)
- 2.1.3、空间注意力机制(Spatial Attention Module,SAM)
- 2.1.4、路径聚合网络(Path Aggregation Network,PANet)
- 2.1.5、Mish激活函数
- 2.2、改进之处
- 2.2.1、马赛克(Mosaic)数据增强 + CutMix数据增强
- 2.2.2、自对抗训练(Self-Adversarial Training,SAT)
- 2.2.3、改进的Dropout(DropBlock)
- 2.2.4、标签平滑(Label Smoothing)
- 2.2.5、CIoU Loss损失函数
- 2.2.6、DIoU-NMS
- 3、测试
- 3.1、训练
- 3.2、测试代码
1、前言
yolo v1~v3 的作者Joseph Redmon于2020年初宣布停止一切CV研究,原因是自己的开源算法已经用在军事和隐私问题上,对他的道德造成了巨大的考验。他的退出是学术界对于AI道德问题一记警钟。salute…
俄罗斯大神AlexAB作为YOLO系列的继任者,在Redmon宣发放弃更新Yolo后两个月,发布了YOLOv4。我们以前在windows上测试YOLO算法时,使用的就是AlexAB 的 darknet开源项目 版本。
首先回顾下Yolo v3网络,整个主干网络Backbone为Darkent53,包含53个卷积层(全连接fc层用于图像分类,这里已移除);输出head包含三个尺度,输入为608*608时,分别为19*19,38*38,76*76。
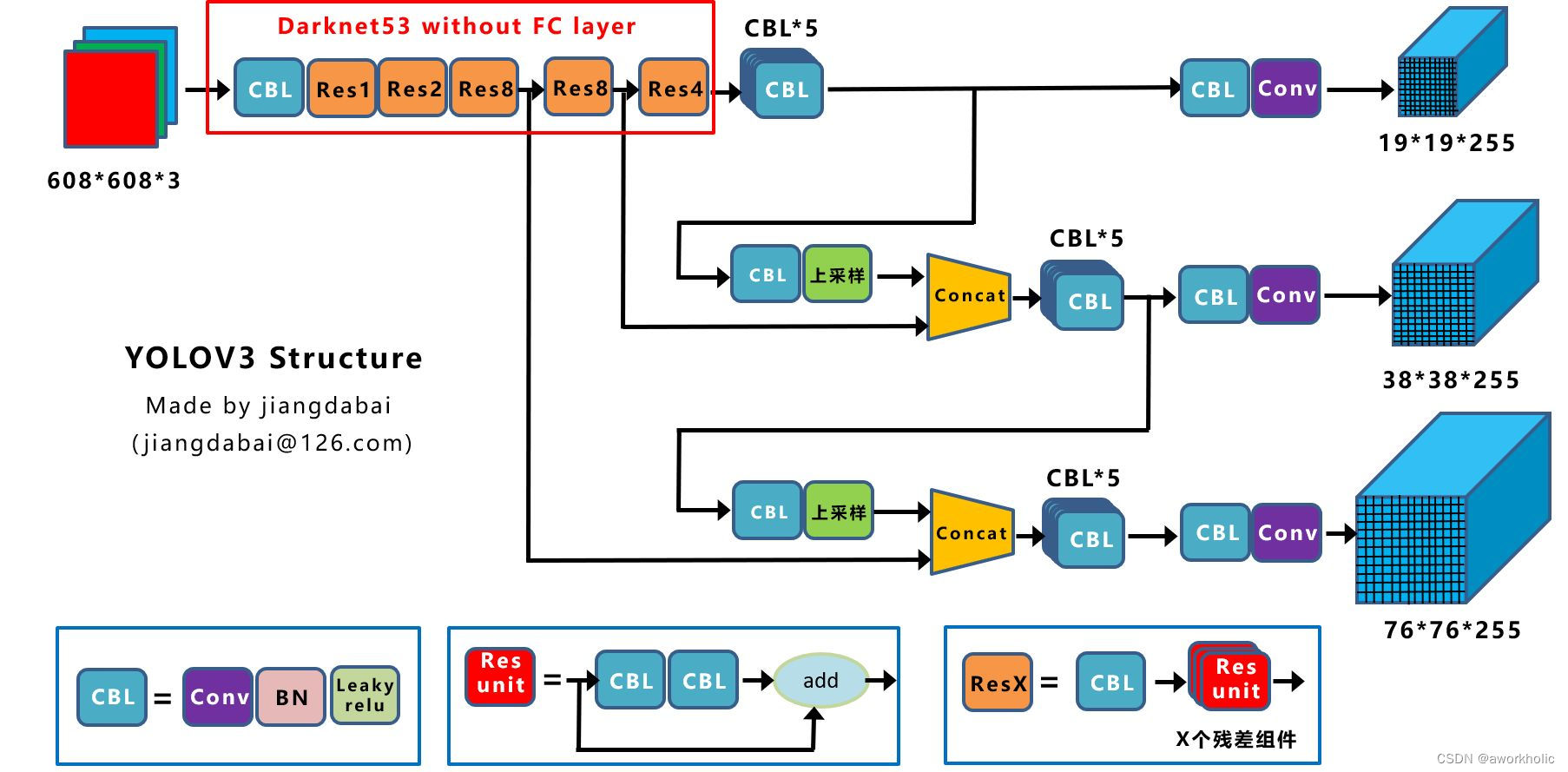
CBL 是Yolov3网络结构中的最小组件;
Res Unit 借鉴Resnet中残差结构,让网络构建更深;
ResX 是Yolov3的大组件,每个Res模块前CBL起到下采样过程,输入60*608的图像,经过5次Res模块后,得到的特征图是608->304->152->76->38->19。
Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。将大感受野的特征图进行上采样,得到于小感受野特征图相同的大小,进行维度拼接,达到多尺度特征融合的目的,从而加强小目标检测能力。
add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样。
2、Yolo v4
核心思想:
yolov4筛选了一些从yolov3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并加以组合及适当创新的算法,实现了速度和精度的完美平衡。虽然有许多技巧可以提高卷积神经网络CNN的准确性,但是某些技巧仅适合在某些模型上运行,或者仅在某些问题上运行,或者仅在小型数据集上运行。
主要调优手段:
加权残差连接(WRC)、跨阶段部分连接(CSP)、跨小批量标准化(CmBN)、自对抗训练(SAT)、Mish激活、马赛克数据增强、CmBN、DropBlock正则化、CIoU Loss等等。经过一系列的堆料,终于实现了目前最优的实验结果:43.5%的AP(在Tesla V100上,MS COCO数据集的实时速度约为 65FPS)。
2.1、网络结构
相较于Darknet53网络,YoloV4的骨干网络使用CSPDarknet53,如下图
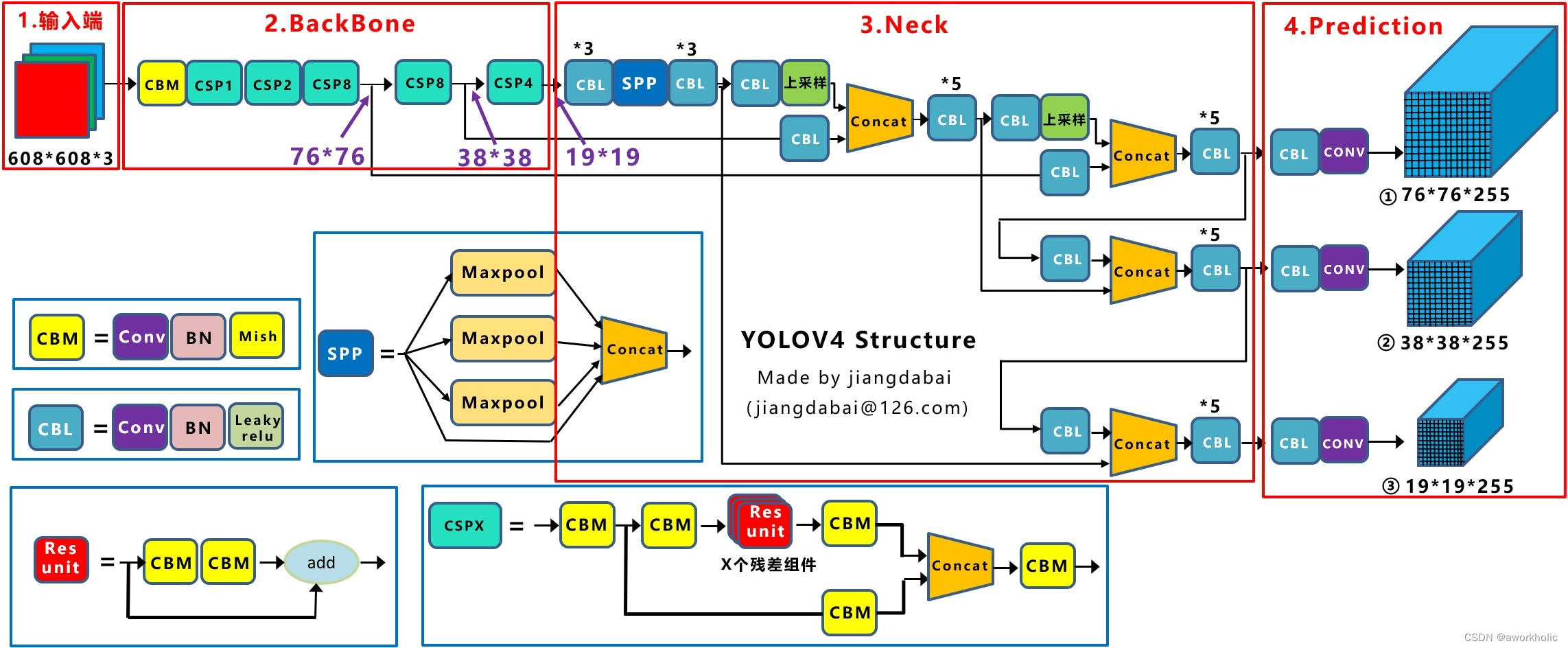
主要区别:
(1)将原来的Darknet53与CSPNet进行结合,形成Backbone网络。
(2)采用SPPNet适应不同尺寸的输入图像大小,且可以增大感受野;
(3)采用SAM引入空间注意力机制;
(4)采用PANet充分利用了特征融合;
(5)激活函数由MIsh替换Leaky ReLU; 在yolov3中,每个卷积层之后包含一个批归一化层和一个Leaky ReLU。而在yolov4的主干网络CSPDarknet53中,使用Mish替换原来的Leak ReLU。
2.1.1、跨阶段部分网络(Cross Stage Partial Networks,CSPNet)
2019年提出用来解决网络优化中的重复梯度信息问题,在ImageNet dataset和MS COCO数据集上有很好的测试效果。且易于实现,在ResNet、ResNeXt和DenseNet网络结构上都能通用。
CSPNet结构实现更丰富的梯度组合,同时减少计算量:将基本层的特征图分成两部分:(1)主干部分继续堆叠原来的残差块;(2)、支路部分则相当于一个残差边,经过少量处理直接连接到最后。
在这里插入图片描述
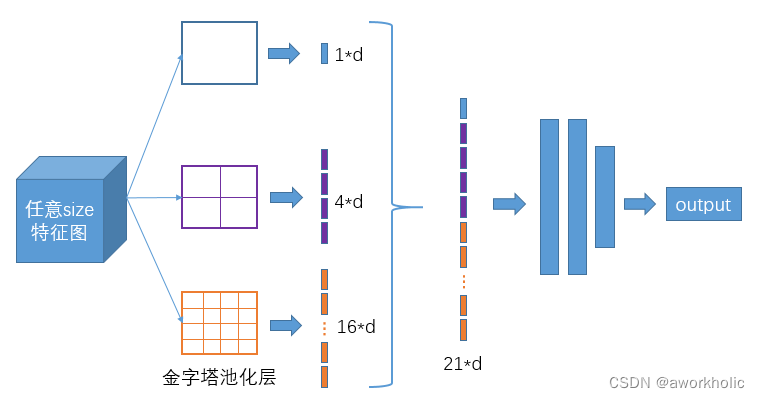
2.1.2、空间金字塔池化网络(Spatial Pyramid Pooling Network,SPPNet)
yolov1背景:yolov1训练时的分辨率:224×224;测试时:448×448。
yolov2背景:yolov2保持yolov1的操作不变,但在原训练的基础上又加上了(10个epoch)的448×448高分辨率样本进行微调,使网络特征逐渐适应 448×448 的分辨率;然后再使用 448×448 的样本进行测试,缓解了分辨率突然切换造成的影响。
目的:使得网络模型的输入图像不再有固定尺寸的大小限制。通过最大池化将不同尺寸的输入图像变得尺寸一致。
优点:增大感受野。
2.1.3、空间注意力机制(Spatial Attention Module,SAM)
yolov4采用改进的SAM方法:Channel attention module(CAM) -> SAM(Spatial Attention Module) -> CBAM(Convolutional Block AM) -> 改进的SAM
-
特征图注意力机制(Channel Attention Module):在Channel维度上,对每一个特征图(channel)加一个权重,然后通过sigmoid得到对应的概率值,最后乘上输入图像,相当于对输入图像的特征图进行加权,即注意力。
如:32×32×256,对256个通道进行加权。 -
空间注意力机制(Spatial Attention Module):在Spatial维度上,对每一个空间位置(Spatial)加一个权重,然后通过sigmoid得到对应的概率值,最后乘上输入图像,相当于对输入图像的所有位置特征进行加权,即注意力。
如:32×32×256,对任意空间位置进行
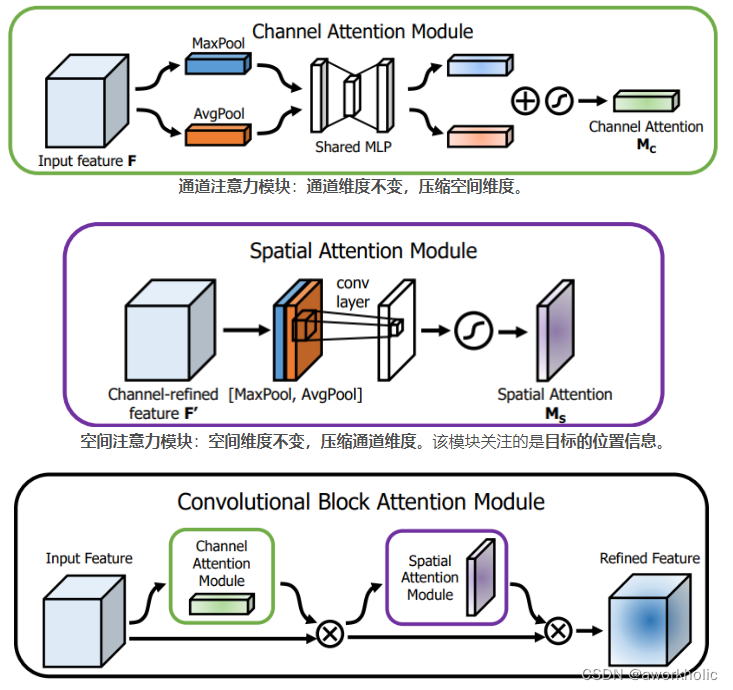
优化原因:
(1)由于CBAM计算比较复杂且耗时,而yolo的出发点是速度,故只计算空间位置的注意力机制。
(2)常规的SAM最大值池化层和平均池化层分别作用于输入的feature map,得到两组shape相同的feature map,再将结果输入到一个卷积层。 过程过于复杂,yolo采取直接卷积进行简化。
2.1.4、路径聚合网络(Path Aggregation Network,PANet)
背景: PANet发表于CVPR2018,其是COCO2017实例分割比赛的冠军,也是目标检测比赛的第二名。
具体方式: yolov4采用改进的PANet方法
优化历程: FPNet(Feature Pyramid Networks) -> PANet(Path Aggregation Network) -> 改进的PAN
优化原因:
(1)FPNet网络采取自上而下的方式,将高层特征逐层与中高层、中层、中底层、低层特征进行融合。缺点是无法自下而上融合,而PANet的优化了该部分不足,详见示意图的(b)部分。
(2)FANet采用特征相加的融合方式,而yolo采用特征拼接的融合方式。加法可以得到一个加强版的特征图,但特征权重不大于1,而拼接可能得到大于1的特征图。
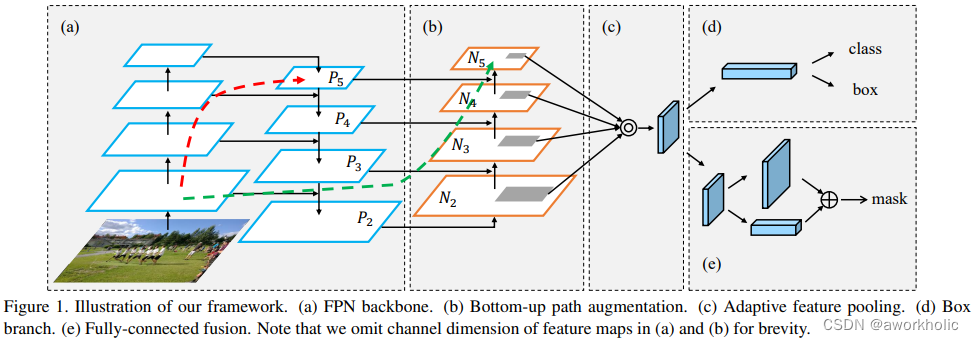
(a)FPNet:通过 融合高层特征 来提升目标检测的效果。
(b)Bottom-up Path Augmentation:通过 融合低层特征(边缘形状等)来提升目标检测的效果。
(c)Adaptive Feature Pooling:采用 拼接特征融合。拼接相比加法,特征更明显,可以提高检测效果。
(d)Box branch:类别和定位分支。
(e)Fully-connected Fusion:用于分割中像素级的预测。
2.1.5、Mish激活函数
Mish在负值的时候并不是完全截断,允许比较小的负梯度流入。实验中,随着层深的增加,ReLU激活函数精度迅速下降,而Mish激活函数在训练稳定性、平均准确率(1%-2.8%)、峰值准确率(1.2% - 3.6%)等方面都有全面的提高。
2.2、改进之处
BackBone训练策略:数据增强、自对抗训练、DropBlock正则化、类标签平滑、CIoU损失函数、DIoU-NMS等。
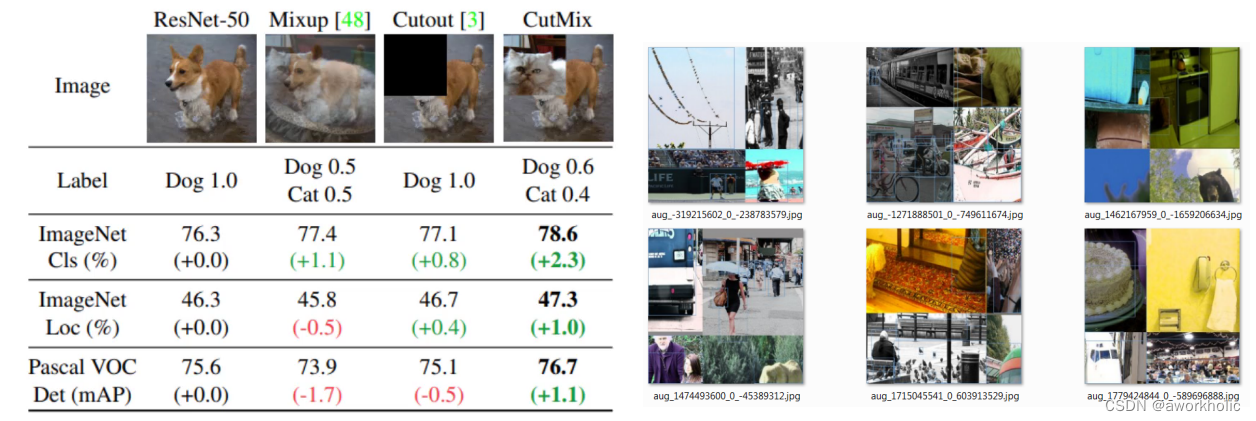
2.2.1、马赛克(Mosaic)数据增强 + CutMix数据增强
最大特点:使得yolov4只通过单CPU就能完成训练,不用再担心设备问题。
具体方式:
11、采用常用的数据增强方法(如:亮度、饱和度、对比度;随机缩放、旋转、翻转等)对所有的图像进行数据增强;
22、采用CutMix数据增强方法。详细见下。
33、采取马赛克(Mosaic)数据增强方法,即随机取四张图像拼接为一张图像。
2.2.2、自对抗训练(Self-Adversarial Training,SAT)
在第一阶段:在原始图像的基础上,添加噪音并设置权重阈值,让神经网络对自身进行对抗性攻击训练。
在第二阶段:用正常的方法训练神经网络去检测目标。
备注:详细可参考对抗攻击的快速梯度符号法(FGSM)。
2.2.3、改进的Dropout(DropBlock)
之前的dropout是随机删除一些点,现在是整块删除。
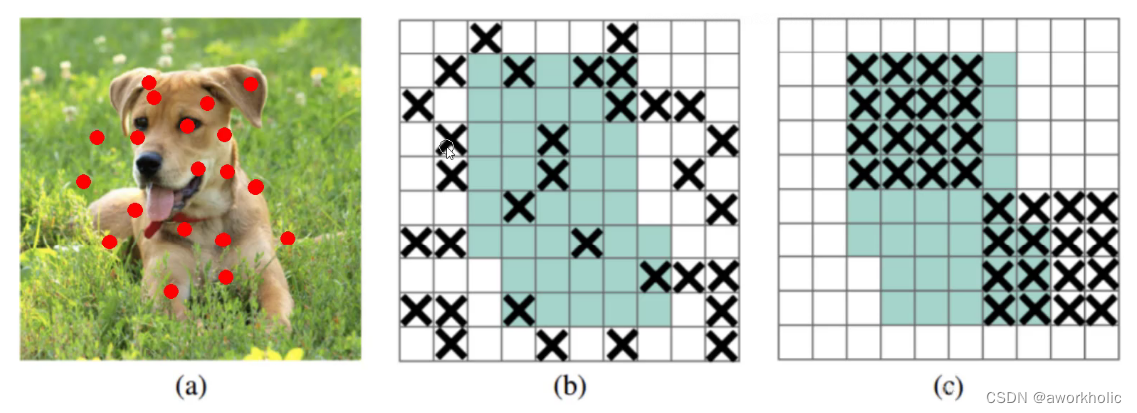
b图:Dropout是随机删除一些神经元(如:a图的红点),但对于整张图来说,效果并不明显。比如:眼睛被删除,我们仍然可以通过眼睛的周边特征(眼角、眼圈等)去近似识别。
c图:DropBlock是随机删除一大块神经元。 如:将狗头的左耳全部删除。
2.2.4、标签平滑(Label Smoothing)
问题:标签绝对化:要么0要么1。该现象将导致神经网络在训练过程中,自我良好,从而过拟合。
具体方式:将绝对化标签进行平滑( 如:[0,0] ~ [0.05,0.95] ),即分类结果具有一定的模糊化,使得网络的抗过拟合能力增强。
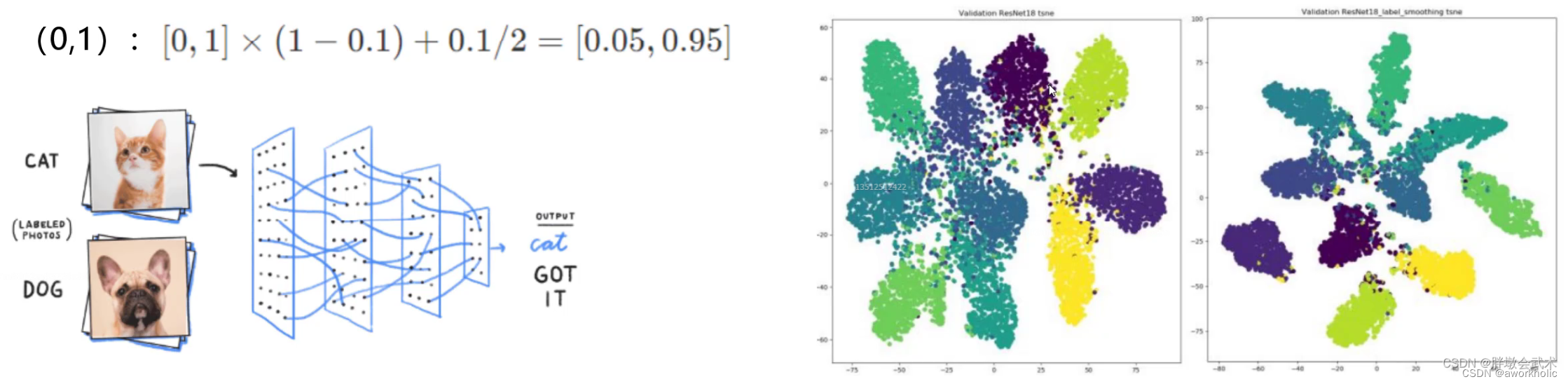
使用前,分类结果相对不错,但各类别之间存在一定的误差;使用后,分类结果比较好,簇内距离变小,簇间距离变大。
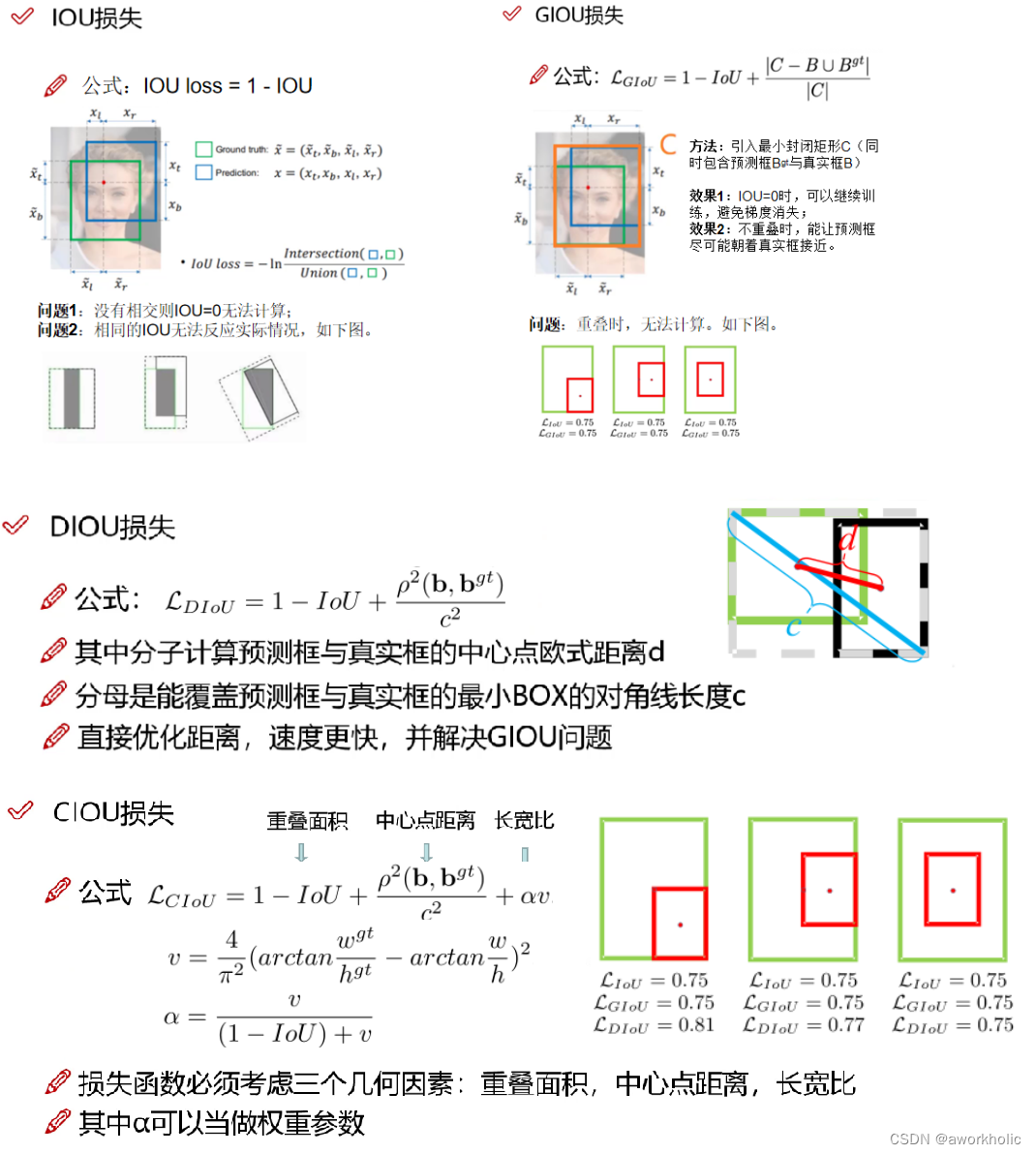
2.2.5、CIoU Loss损失函数
效果:采用CIoU Loss损失函数,使得预测框回归的速度和精度更高一些。
loss优化历程:经典IOU损失 -> GIOU损失(Generalized IoU) -> DIOU损失(Distance IoU) -> CIOU损失。
Iou仅考虑有目标框有交集的重叠面积情况,GIou考虑边界框不重合的问题、可以在没有交集情况下继续训练,DIou在前面的基础上考虑了边界框的中心点的欧氏距离,CIou进一步考虑长宽比的尺度信息。
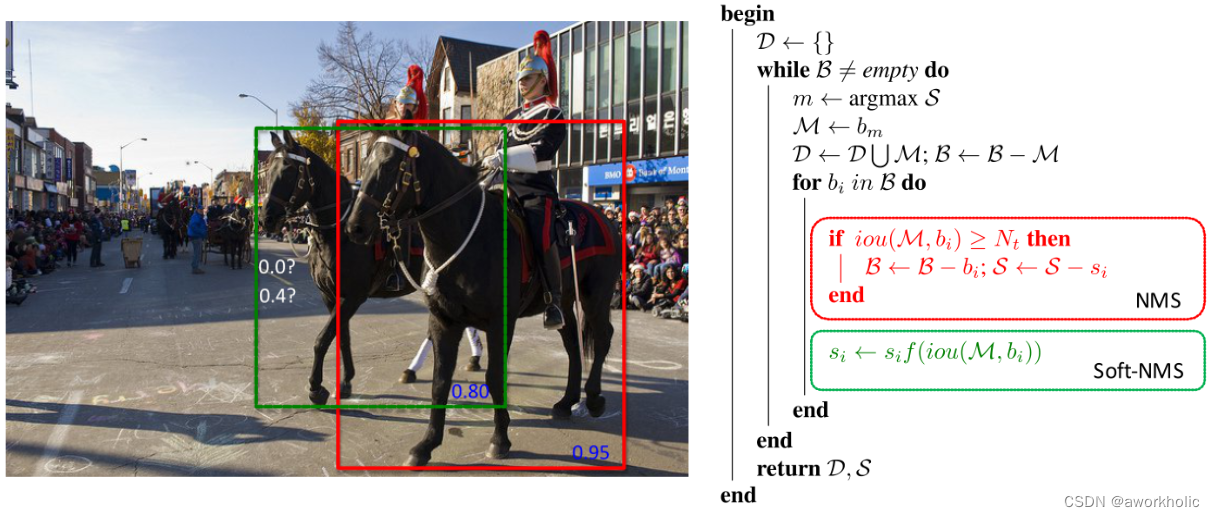
2.2.6、DIoU-NMS
在检测结果中,若存在多个检测框的IOU大于置信度阈值
(1)NMS非极大值抑制:只取IoU最大值对应的框。
(2)DIoU-NMS:只取公式计算得到的最大值对应的框。取最高置信度的IoU,并计算最高置信度候选框(M)与其余所有框(Bi)的中心点距离。优点:在有遮挡的情况下识别效果更好。
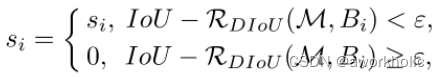
(3)SOFT-NMS:对于不满足要求,且与最大置信度对应的检测框高度重叠的检测框,不直接删除,而采取降低置信度的方式。优点:召回率更高
3、测试
yolov3 和 yolov4 使用相同代码即可测试。可以参看 【opencv dnn模块 示例(3) 目标检测 object_detection (2) YOLO object detection】。
项目介绍和下载地址 https://github.com/AlexeyAB/darknet#pre-trained-models
3.1、训练
yolo v4同样使用darknet框架,训练直接使用官方程序脚本(同yolov3)即可。
3.2、测试代码
#include <fstream>
#include <sstream>
#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
using namespace dnn;
float confThreshold, nmsThreshold;
std::vector<std::string> classes;
void postprocess(Mat& frame, const std::vector<Mat>& out, Net& net);
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);
void callback(int pos, void* userdata);
int main(int argc, char** argv)
{
// 根据选择的检测模型文件进行配置
confThreshold = 0.5;
nmsThreshold = 0.4;
float scale = 0.00392;
Scalar mean = {0,0,0};
bool swapRB = true;
int inpWidth = 416; // 416, 608 ...
int inpHeight = 416;
String modelPath = "../../data/testdata/dnn/yolov4.weights";
String configPath = "../../data/testdata/dnn/yolov4.cfg";
String framework = "";
//int backendId = cv::dnn::DNN_BACKEND_OPENCV;
//int targetId = cv::dnn::DNN_TARGET_CPU;
int backendId = cv::dnn::DNN_BACKEND_CUDA;
int targetId = cv::dnn::DNN_TARGET_CUDA;
String classesFile = "../../data/dnn/object_detection_classes_yolov4.txt";
// Open file with classes names.
if (!classesFile.empty()) {
const std::string& file = classesFile;
std::ifstream ifs(file.c_str());
if (!ifs.is_open())
CV_Error(Error::StsError, "File " + file + " not found");
std::string line;
while (std::getline(ifs, line)) {
classes.push_back(line);
}
}
// Load a model.
Net net = readNet(modelPath, configPath, framework);
net.setPreferableBackend(backendId);
net.setPreferableTarget(targetId);
std::vector<String> outNames = net.getUnconnectedOutLayersNames();
// Create a window
static const std::string kWinName = "Deep learning object detection in OpenCV";
// Open a video file or an image file or a camera stream.
VideoCapture cap;
cap.open(0);
// Process frames.
Mat frame, blob;
while (waitKey(1) < 0) {
cap >> frame;
if (frame.empty()) {
waitKey();
break;
}
// Create a 4D blob from a frame.
Size inpSize(inpWidth > 0 ? inpWidth : frame.cols,
inpHeight > 0 ? inpHeight : frame.rows);
blobFromImage(frame, blob, scale, inpSize, mean, swapRB, false);
// Run a model.
net.setInput(blob);
if (net.getLayer(0)->outputNameToIndex("im_info") != -1) // Faster-RCNN or R-FCN
{
resize(frame, frame, inpSize);
Mat imInfo = (Mat_<float>(1, 3) << inpSize.height, inpSize.width, 1.6f);
net.setInput(imInfo, "im_info");
}
std::vector<Mat> outs;
net.forward(outs, outNames);
postprocess(frame, outs, net);
// Put efficiency information.
std::vector<double> layersTimes;
double freq = getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
std::string label = format("Inference time: %.2f ms", t);
putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
imshow(kWinName, frame);
}
return 0;
}
void postprocess(Mat& frame, const std::vector<Mat>& outs, Net& net)
{
static std::vector<int> outLayers = net.getUnconnectedOutLayers();
static std::string outLayerType = net.getLayer(outLayers[0])->type;
std::vector<int> classIds;
std::vector<float> confidences;
std::vector<Rect> boxes;
if (net.getLayer(0)->outputNameToIndex("im_info") != -1) // Faster-RCNN or R-FCN
{
// Network produces output blob with a shape 1x1xNx7 where N is a number of
// detections and an every detection is a vector of values
// [batchId, classId, confidence, left, top, right, bottom]
CV_Assert(outs.size() == 1);
float* data = (float*)outs[0].data;
for (size_t i = 0; i < outs[0].total(); i += 7) {
float confidence = data[i + 2];
if (confidence > confThreshold) {
int left = (int)data[i + 3];
int top = (int)data[i + 4];
int right = (int)data[i + 5];
int bottom = (int)data[i + 6];
int width = right - left + 1;
int height = bottom - top + 1;
classIds.push_back((int)(data[i + 1]) - 1); // Skip 0th background class id.
boxes.push_back(Rect(left, top, width, height));
confidences.push_back(confidence);
}
}
}
else if (outLayerType == "DetectionOutput") {
// Network produces output blob with a shape 1x1xNx7 where N is a number of
// detections and an every detection is a vector of values
// [batchId, classId, confidence, left, top, right, bottom]
CV_Assert(outs.size() == 1);
float* data = (float*)outs[0].data;
for (size_t i = 0; i < outs[0].total(); i += 7) {
float confidence = data[i + 2];
if (confidence > confThreshold) {
int left = (int)(data[i + 3] * frame.cols);
int top = (int)(data[i + 4] * frame.rows);
int right = (int)(data[i + 5] * frame.cols);
int bottom = (int)(data[i + 6] * frame.rows);
int width = right - left + 1;
int height = bottom - top + 1;
classIds.push_back((int)(data[i + 1]) - 1); // Skip 0th background class id.
boxes.push_back(Rect(left, top, width, height));
confidences.push_back(confidence);
}
}
}
else if (outLayerType == "Region") {
for (size_t i = 0; i < outs.size(); ++i) {
// Network produces output blob with a shape NxC where N is a number of
// detected objects and C is a number of classes + 4 where the first 4
// numbers are [center_x, center_y, width, height]
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols) {
Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
Point classIdPoint;
double confidence;
minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > confThreshold) {
int centerX = (int)(data[0] * frame.cols);
int centerY = (int)(data[1] * frame.rows);
int width = (int)(data[2] * frame.cols);
int height = (int)(data[3] * frame.rows);
int left = centerX - width / 2;
int top = centerY - height / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(Rect(left, top, width, height));
}
}
}
}
else
CV_Error(Error::StsNotImplemented, "Unknown output layer type: " + outLayerType);
std::vector<int> indices;
NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
Rect box = boxes[idx];
drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));
std::string label = format("%.2f", conf);
if (!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ": " + label;
}
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
rectangle(frame, Point(left, top - labelSize.height),
Point(left + labelSize.width, top + baseLine), Scalar::all(255), FILLED);
putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}