前言:Hello大家好,我是小哥谈。BiFPN ( Bidirectional Feature Pyramid Network )是一种加权双向(自顶向下 + 自底向上)特征金字塔网络,是目标检测中神经网络架构设计的选择之一,是为了优化目标检测性能而提出,主要用来进行多尺度特征融合,对神经网络性能进行优化。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
YOLOv5算法改进(5)— 添加ECA注意力机制
YOLOv5算法改进(6)— 添加SOCA注意力机制
YOLOv5算法改进(7)— 添加SimAM注意力机制
YOLOv5算法改进(8)— 替换主干网络之MobileNetV3
YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
YOLOv5算法改进(10)— 替换主干网络之GhostNet
YOLOv5算法改进(11)— 替换主干网络之EfficientNetv2
YOLOv5算法改进(12)— 替换主干网络之Swin Transformer
YOLOv5算法改进(13)— 替换主干网络之PP-LCNet
目录
🚀1.论文
🚀2.BiFPN网络架构及原理
🚀3.添加方式1:Add操作
💥💥步骤1:在common.py中添加BiFPN模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py
🚀4.添加方式2:Concat操作
💥💥步骤1:在common.py中添加BiFPN模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py

🚀1.论文
EfficientDet 是继 2019 年推出 EfficientNet 模型之后,Google 人工智能研究小组Tan Mingxing等人为进一步提高目标检测效率,以 EfficientNet 模型和双向特征加权金字塔网络 BiFPN为基础,于2020 年创新推出的新一代目标检测模型,在COCO数据集上吊打其他方法。🌟
总结:EfficientDet = Backbone(EfficientNet) + Neck(BiFPN) + Head(class + box)

在这篇论文中,作者主要贡献如下:
首先,提出了一种加权双向特征金字塔网络(BIFPN),该网络可以简单快速的实现多尺度特征融合。
其次,提出了一种Compound Scaling方法,该方法可以同时对所有的主干网络、特征网络和框/类预测网络的分辨率、深度和宽度进行统一缩放。

说明:♨️♨️♨️
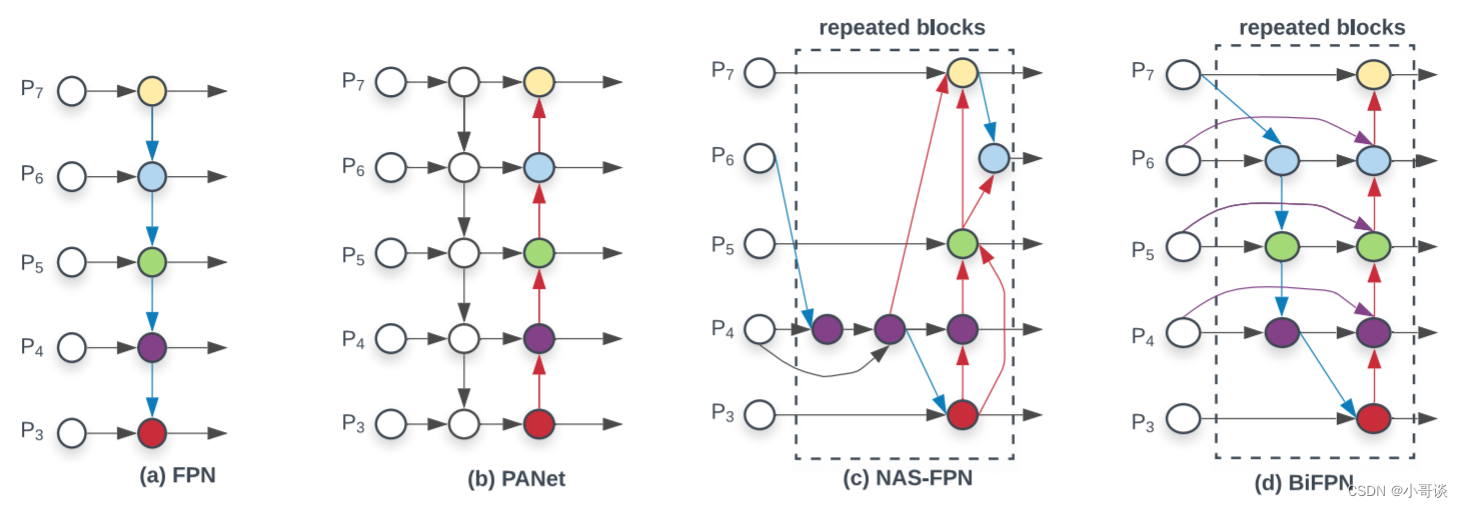
BiFPN是本文中提出的最重要的一个结构。在此之前介绍一下其他的特征金字塔网络(FPN)结构:
FPN:采用一种自上而下的方法来组合多尺度特征
PANet:在FPN之上增加了一个额外的自下而上的路径聚合网络
STDL:提出了一个利用跨尺度特征的尺度转换模块
M2det:提出一种融合多尺度特征的U形模块
NAS-FPN:利用神经架构搜索来自动设计特征网络拓扑结构
BiFPN:高效的双向跨尺度连接和加权特征融合
论文题目:《EfficientDet: Scalable and Efficient Object Detection》
论文地址: https://arxiv.org/pdf/1911.09070.pdf
代码实现: https://github.com/jewelc92/mmdetection/blob/3.x/projects/EfficientDet/efficientdet/bifpn.py
🚀2.BiFPN网络架构及原理
YOLOv5模型的Neck部分使用的是FPN+PAN结构,它利用金字塔的形式对尺度不同的特征图进行连接,将高层特征和低层特征进行融合。FPN与PAN的结合,虽然有效提高了网络的特征融合能力,但也会导致一个问题,即PAN结构的输入全部是FPN结构处理的特征信息,而骨干特征提取网络部分的原始特征信息存在一部分丢失。缺乏参与学习的原始信息很容易导致训练学习的偏差,影响检测的准确性。从Neck特征融合入手,引入加权双向特征金字塔BiFPN来加强特征图的底层信息,使不同尺度的特征图进行信息融合,从而加强特征信息。🔖
BiFPN是在FPN的基础上对其进行改进的,是一种改进版的FPN网络结构,主要用于目标检测任务。该结构是加权且双向连接的,即自顶向下和自底向上结构,通过构造双向通道实现跨尺度连接,将特征提取网络中的特征直接与自下而上路径中的相对大小特征融合,保留了更浅的语义信息,而不会丢失太多的深层语义信息。🔖
所以,总的网络结构如下所示,即不断堆叠BiFPN层的EfficientDet模型。

说明:♨️♨️♨️
传统的特征融合是将尺度不同的特征图以相同权重进行加权,但是当输入的特征图分辨率不同时,以相同的权重进行加权对输出的特征图不平等。所以,BiFPN根据不同输入特征的重要性设置不同的权重,同时反复采用这种结构来加强特征融合。
BiFPN通过上下两个方向的信息传递,增强了特征金字塔网络的表达能力和信息传递效率。它具有以下几个关键特点:
🍀(1)双向连接:BiFPN在特征金字塔的每一层都设置了上下两个连接,使得特征能够在不同层之间双向传播和融合,从而保留了更多的上下文信息。
🍀(2)特征融合:BiFPN使用了一种基于注意力机制的特征融合方式,通过动态地调整特征的权重来实现更好的特征融合效果。
🍀(3)尺度平衡:BiFPN通过引入一个可学习的权重参数来平衡不同尺度的特征在融合过程中的重要性,使得网络对多尺度目标具有更好的适应性。
总之,BiFPN通过双向连接和特征融合机制,在目标检测和语义分割任务中起到了提升特征表达和信息传递效率的作用,提高了模型的性能。
🚀3.添加方式1:Add操作
💥💥步骤1:在common.py中添加BiFPN模块
将下面BiFPN模块的代码复制粘贴到common.py文件的末尾。
python"># BiFPN
# 两个特征图add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三个特征图add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
具体如下图所示:

💥💥步骤2:在yolo.py文件中加入类名
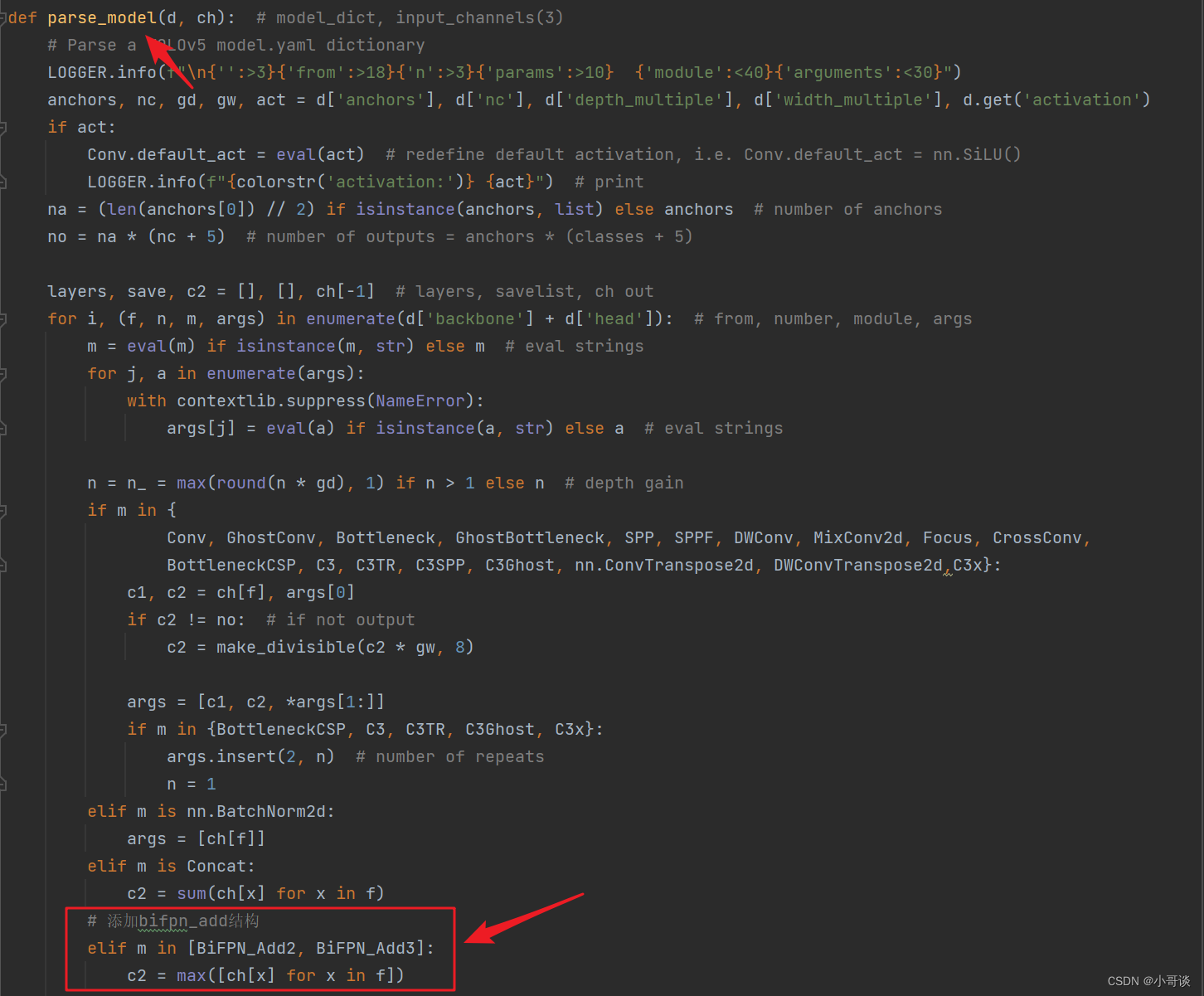
在yolo.py文件的parse_model函数中找到 elif m is Conat: 语句,在其后面加上下列语句:
python"># 添加bifpn_add结构
elif m in [BiFPN_Add2, BiFPN_Add3]:
c2 = max([ch[x] for x in f])具体如下图所示:
💥💥步骤3:创建自定义yaml文件
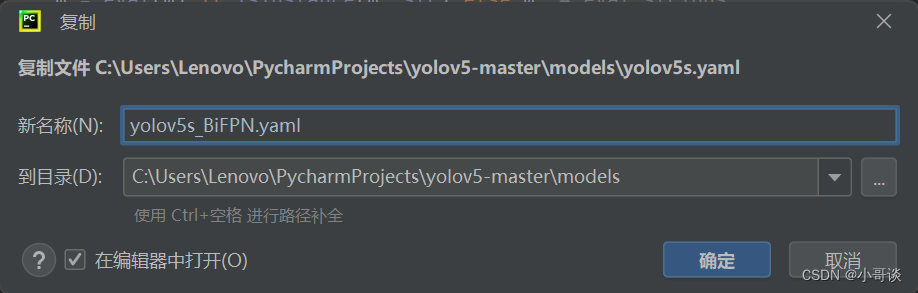
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_BiFPN.yaml。
然后将yaml文件中所有Concat换成BiFPN_Add。
yaml文件修改后的完整代码如下:
python"># YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.1 BiFPN head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Add2, [256, 256]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Add2, [128, 128]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17
[-1, 1, Conv, [512, 3, 2]],
[[-1, 13, 6], 1, BiFPN_Add3, [256, 256]], #v5s通道数是默认参数的一半
[-1, 3, C3, [512, False]], # 20
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Add2, [256, 256]], # cat head P5
[-1, 3, C3, [1024, False]], # 23
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
说明:♨️♨️♨️
BiFPN_Add本质上是add操作,不是Concat操作,因此BiFPN_Add的各个输入层要求大小完全一致(通道数、feature map大小等)。
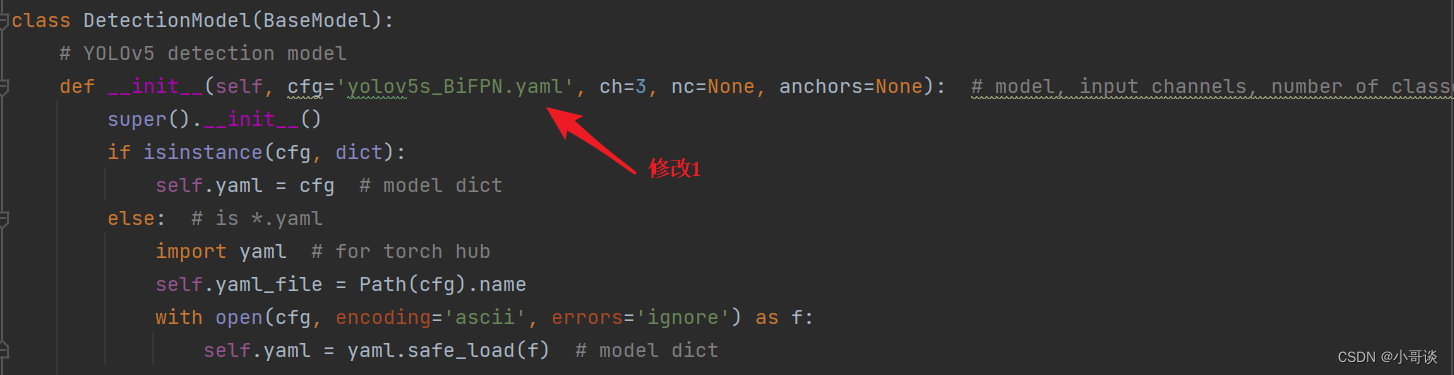
💥💥步骤4:验证是否加入成功
在yolo.py文件里,配置我们刚才自定义的yolov5s_BiFPN.yaml。

然后运行yolo.py,得到结果。
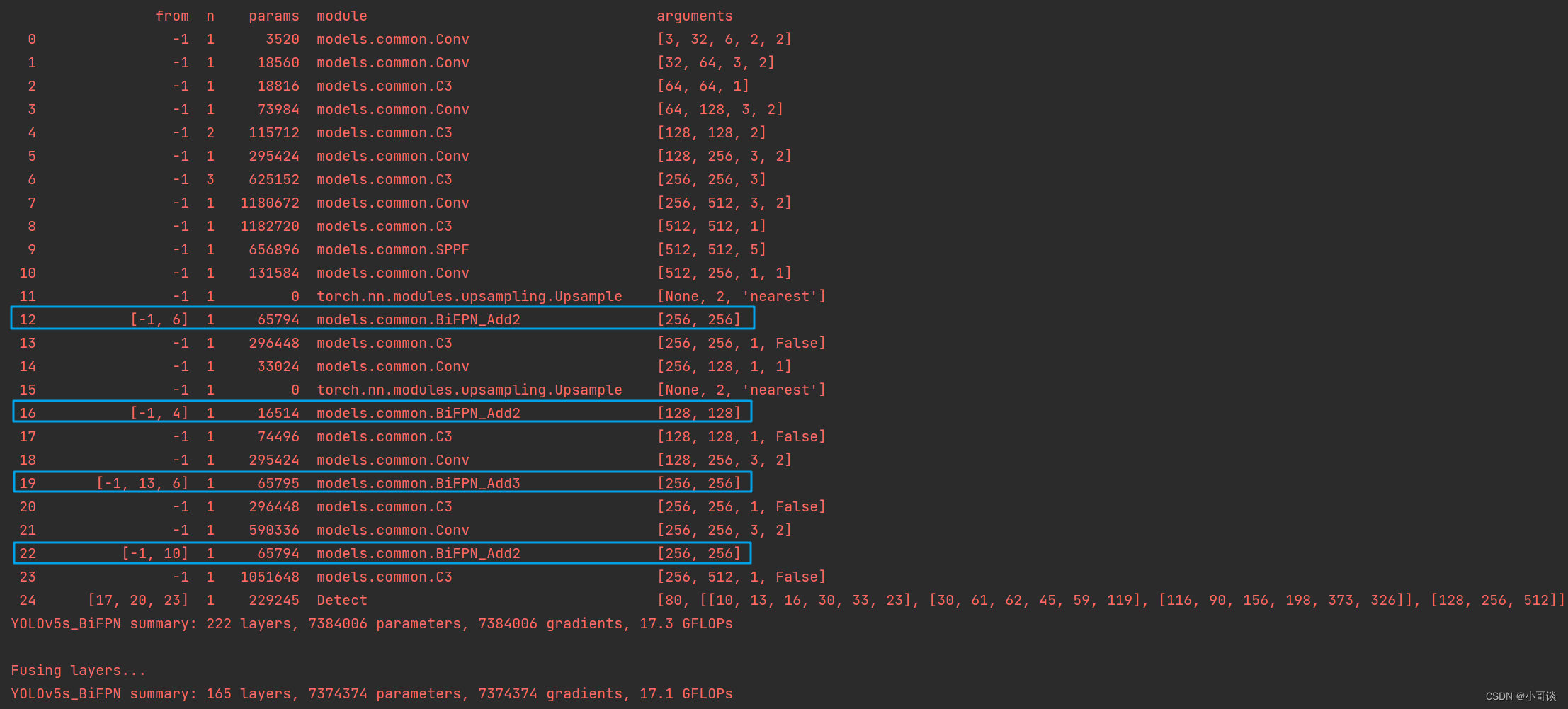
由运行结果可以看到,所有Concat已被换成了BiFPN_Add。
这样就算添加成功了。🎉🎉🎉
💥💥步骤5:修改train.py
首先找到train.py文件中的 #Optimizer,加入下列代码:
python"> g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
# BiFPN_Concat
elif isinstance(v, BiFPN_Add2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Add3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
具体如下图所示:

此时,我们可以看到,出现了报错提示,原因是我们没有导入相应的包。
接下来,我们就导入相应的包。
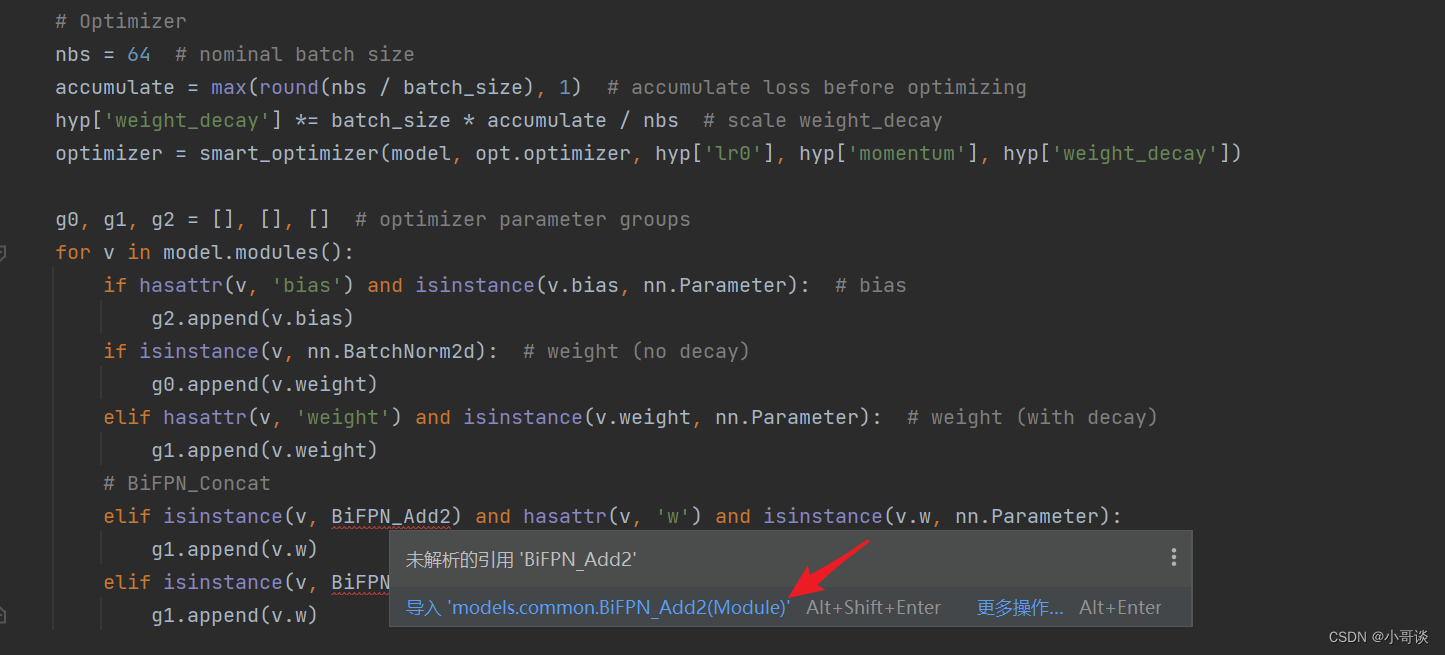
导入完毕后,我们可以看到:报错消失了!具体如下图所示:

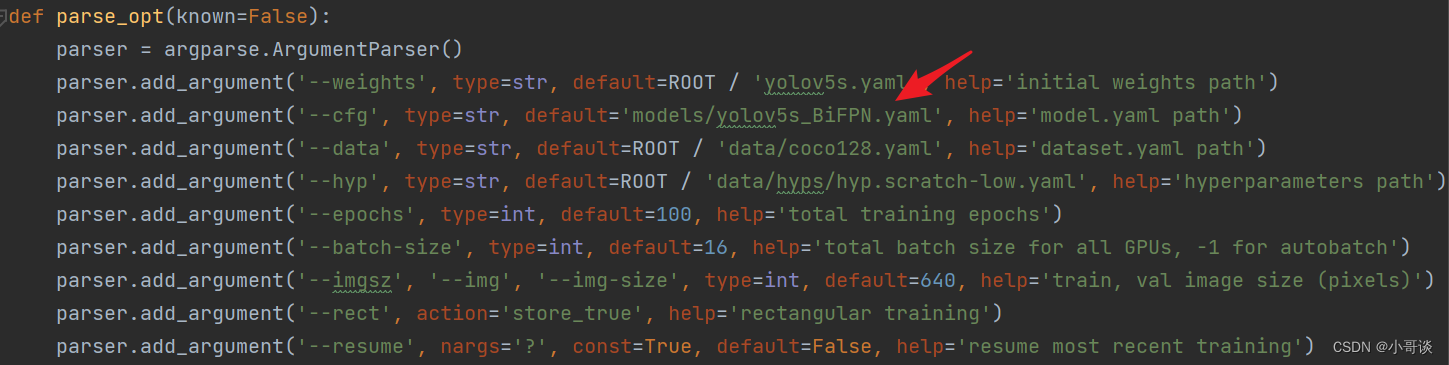
然后,在train.py文件中找到 parse_opt函数,然后将第二行 '--cfg' 的default改为 'models/yolov5s_BiFPN.yaml',然后就可以开始进行训练了。🎈🎈🎈
🚀4.添加方式2:Concat操作
💥💥步骤1:在common.py中添加BiFPN模块
将下面BiFPN模块的代码复制粘贴到common.py文件的末尾。
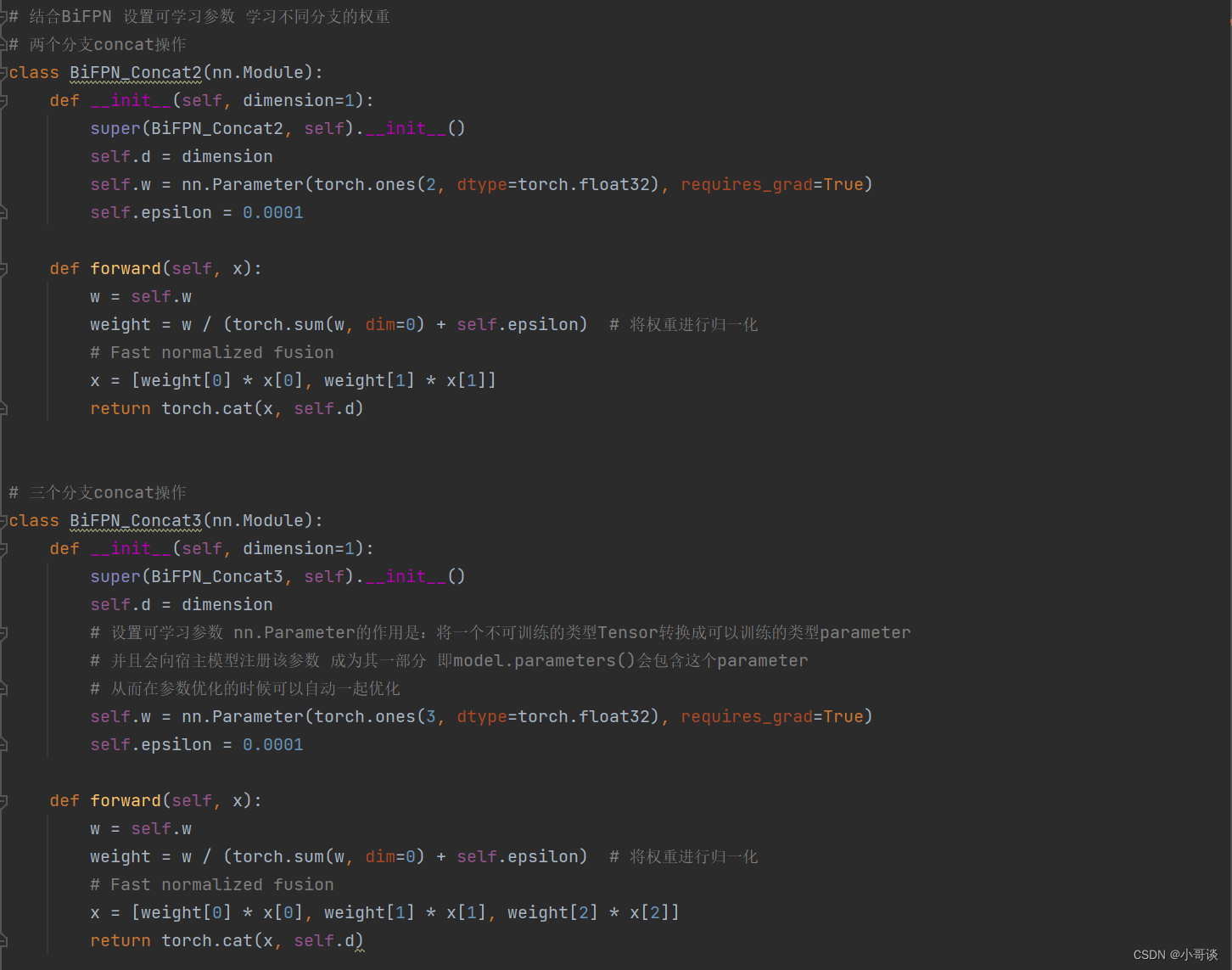
python"># 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支concat操作
class BiFPN_Concat2(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat2, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1]]
return torch.cat(x, self.d)
# 三个分支concat操作
class BiFPN_Concat3(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat3, self).__init__()
self.d = dimension
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
return torch.cat(x, self.d)具体如下图所示:
💥💥步骤2:在yolo.py文件中加入类名
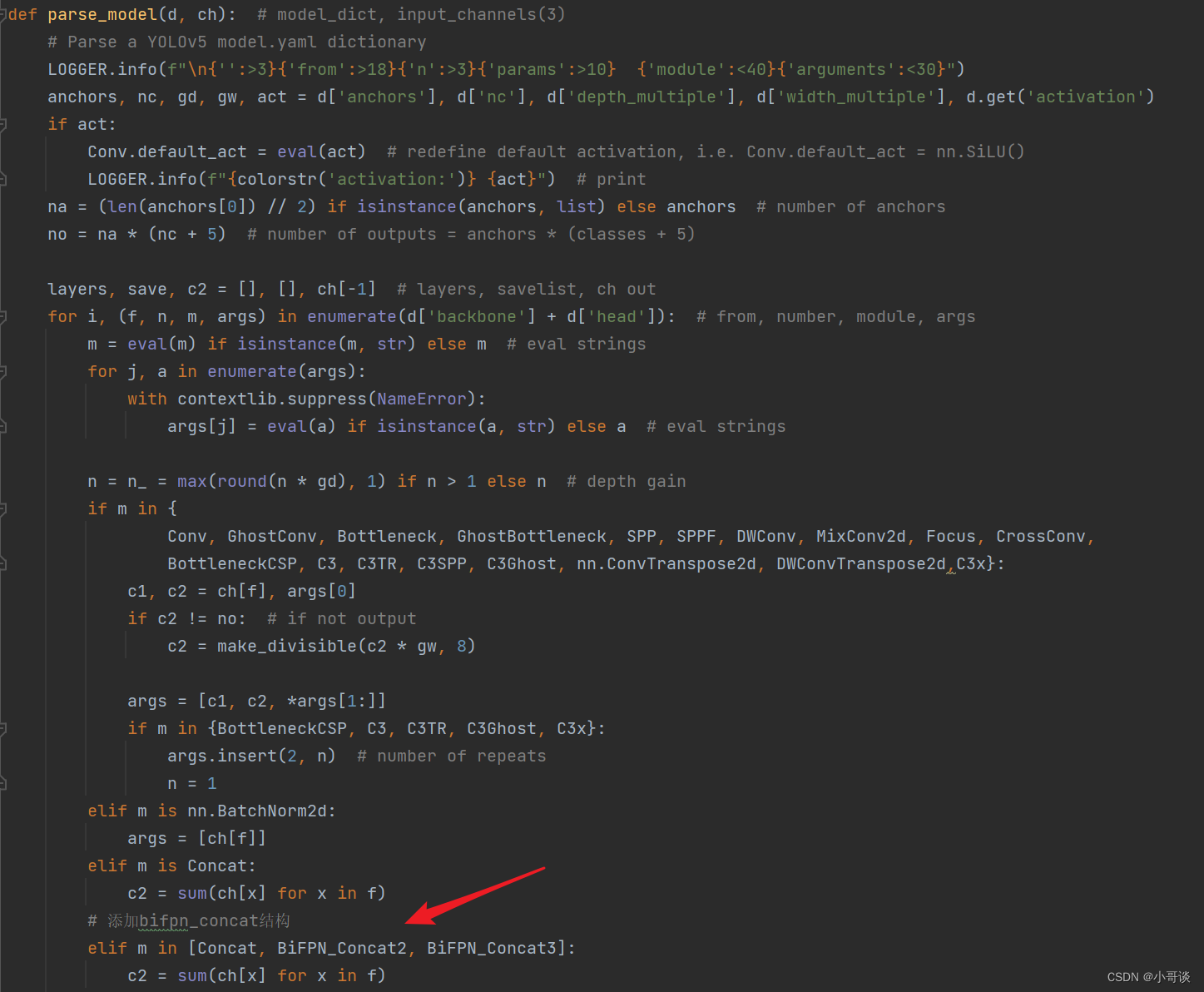
在yolo.py文件的parse_model函数中找到 elif m is Conat: 语句,在其后面加上下列语句:
python"># 添加bifpn_concat结构
elif m in [Concat, BiFPN_Concat2, BiFPN_Concat3]:
c2 = sum(ch[x] for x in f)具体如下图所示:
💥💥步骤3:创建自定义yaml文件
yaml文件修改后的完整代码如下:
python"># YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 BiFPN head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Concat2, [1]], # cat backbone P4 <--- BiFPN change
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Concat2, [1]], # cat backbone P3 <--- BiFPN change
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14, 6], 1, BiFPN_Concat3, [1]], # cat P4 <--- BiFPN change
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Concat2, [1]], # cat head P5 <--- BiFPN change
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]💥💥步骤4:验证是否加入成功
在yolo.py文件里,配置我们刚才自定义的yolov5s_BiFPN.yaml(添加方式1时,我已经配置完毕)。然后运行yolo.py,得到结果:
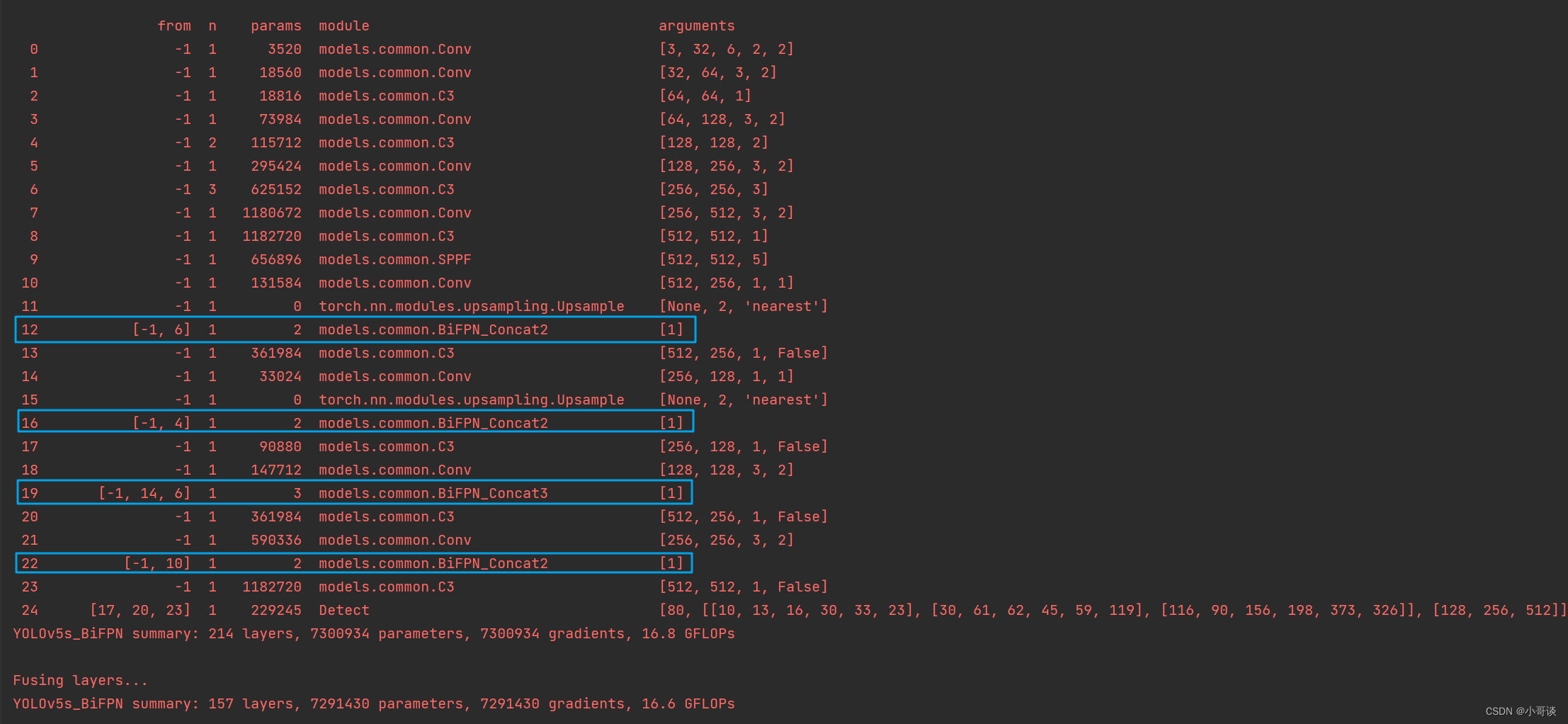
可以看到,我们已经替换成功!🎉🎉🎉
💥💥步骤5:修改train.py
和上面步骤一样,向优化器中添加BiFPN的权重参数。
python">g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
# BiFPN_Concat
elif isinstance(v, BiFPN_Concat2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Concat3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)具体如下图所示:
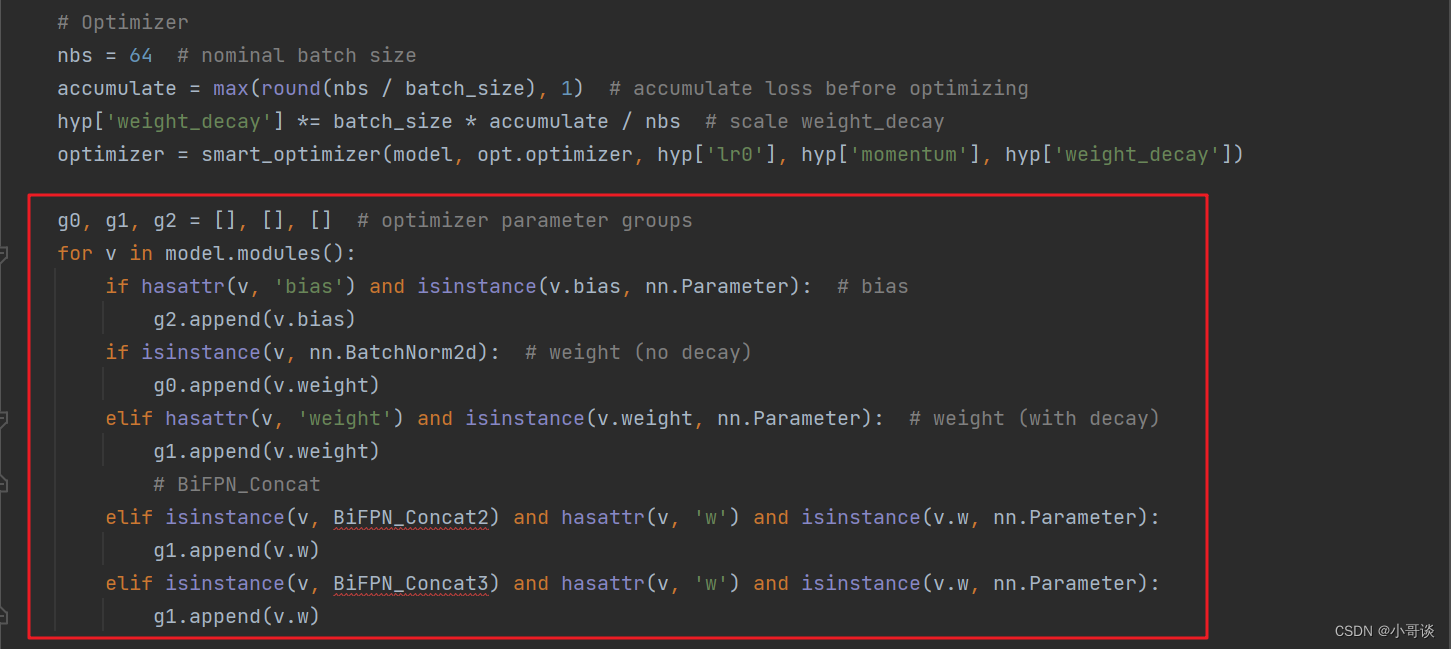
此时会出现报错,导入相应的包即可。(和上面步骤一样)
然后我们就可以训练了!🎈🎈🎈