目录
- 一、改进网络结构设计
- 1 改进的注意力机制
- 2 多尺度特征融合
- 3 改进的激活函数
- 二 数据增强和数据平衡
- 1 数据增强
- 2 数据平衡
- 3 注意事项
- 三、模型融合策略
- 1 投票策略
- 2 加权平均策略
- 3 特征融合策略
- 4 其他模型融合策略
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
一、改进网络结构设计
1 改进的注意力机制
注意力机制是一种常见的网络改进方法,它可以将网络的注意力集中在图像中的重要区域,从而提高网络的性能。在本课题中,将在YOLOv4算法中加入注意力机制来提高车辆识别的性能。
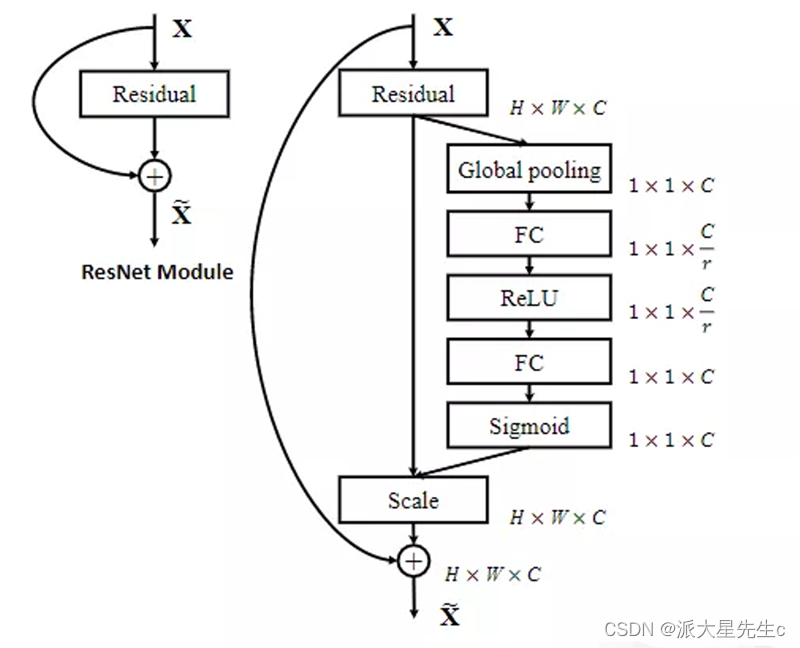
具体来说,使用了SENet(Squeeze-and-Excitation Networks)中的注意力机制。在squeeze流程中,该网络对特征图进行全局池化,从而产生一个全局特征向量。在 excitation方案中,通过对全局特征向量进行两个连通层的运算,得到权重向量。该方法可以通过权重向量可来调整特征图中各通道的权重大小,从而提高网络的性能。
在本课题中,将SENet中的注意力机制加入到YOLOv4算法的主干网络中。在CSPDarknet-53的每个卷积层后面加入一个SE模块。如图3.4这样可以使得网络更加关注图像中的重要区域,从而提高网络的性能。
2 多尺度特征融合
多尺度特征融合是一种常见的网络改进方法,它可以将不同尺度的特征图进行融合,从而提高网络的性能。在本课题中,将在YOLOv4算法中加入多尺度特征融合来提高车辆识别的性能。
具体来说,对YOLOv4算法中的PAN模块进行了改进,以使其能够融合不同尺度的特征图。在YOLOv4算法中,PAN模块采用上下采样的方式对各层级的图像进行融合。上采样模块对低层特征图进行上采样,并将其与高层特征图进行数据融合。下采样模块对高层特征图进行取样,并将其与低层特征图进行融合。这样, PAN模块就可以在多个尺度上实现对多个特征图像的融合,提升网络性能。
在本课题中,将PAN模块进行改进,把更大范围的特性图融合起来。对PAN模块的上、下样本模块进行了改进,实现了多个不同尺度特征图的融合。通过这种方式,可以将不同尺度的特征信息进行更加充分的融合,从而提高网络的性能。
3 改进的激活函数
激活函数是一种非常重要的网络组件,它可以对输入进行非线性变换,从而提高网络的表达能力。在本课题中,将引入改进的激活函数,从而提高YOLOv4算法的性能。
为了提高YOLOv4算法的表达能力,一个新型的激活函数Mish被引入。Mish激活函数利用输入的非线性变换,改善了网络的整体特性。比较常见的激活函数(例如 ReLU, LeakyReLU等),在处理较大的输入时,Mish激活函数表现更好。因此,在本课题中,引入Mish激活函数,以提高YOLOv4算法的性能。
通过这种方式,可以使得网络更加灵活,从而提高网络的表达能力。
二 数据增强和数据平衡
1 数据增强
数据增强是指在不增加新的数据的情况下,通过一系列的变换和处理来扩充训练数据集的数量和质量。在车辆识别中,数据增强可以通过以下几种方式来实现:
在车辆识别中,可以通过随机裁剪、随机旋转、随机缩放和随即扭曲来模拟车辆在不同位置和角度的情况,从而提高模型的泛化能力。可以通过来模拟车辆在不同角度和方向的情况,从而提高模型的鲁棒性、适应性和泛化能力。
2 数据平衡
数据平衡是指通过一系列的处理和调整来保证训练数据集中各个类别之间的数量平衡[21]。在车辆识别中,数据平衡可以通过以下几种方式来实现:
(1)过采样
过采样是一种常用的数据平衡方式,它可以通过复制原始图像来增加某个类别的样本数量,从而达到数据平衡的效果。在车辆识别中,可以通过过采样来增加少数类别(如摩托车、公交车等)的样本数量,从而提高模型对这些类别的识别性能。
(2)欠采样
欠采样是一种简单有效的数据平衡方式,它可以通过删除部分原始图像来减少某个类别的样本数量,以求数据平衡。在车辆识别中,可以从欠采样来降低大部分类别(如轿车、越野车等)的样本量,从而保证各个类别之间的数量平衡。
(3)合成样本
合成样本是一种较为复杂的数据平衡方式,它可以通过对原始图像进行一系列的处理和合成来生成新的训练样本。在车辆识别中,可以通过合成样本来增加某个类别的样本数量,从而提高模型对这些类别的识别性能。
3 注意事项
当执行数据增强和数据平衡时,留意下列事项:
(1)合理选择数据增强和数据平衡方式
不同的数据增强和数据平衡方式适用于不同的数据集和模型,需要根据实际情况进行选择。在选择数据增强和数据平衡方式时,需要考虑模型的结构和训练数据集的特点,以达到最佳的识别性能。
(2)控制数据增强的程度
过度的数据增强可能会导致模型过拟合,因此需要控制数据增强的程度。在进行数据增强时,需要考虑图像变换的幅度和数量,以达到适度的数据扩充效果。
(3)平衡各个类别的样本数量
数据平衡的目的是保证各个类别之间的数量平衡,因此需要根据各个类别的样本数量进行调整。在进行数据平衡时,需要保证删除或复制的样本数量不会对模型的训练造成过度的影响。
总结
基于Yolov4的车辆识别中,数据增强与均衡是提升车辆识别精度的关键技术,合理的数据扩充与均衡能够显著提升模型的泛化与鲁棒性。在实际应用中
三、模型融合策略
在目标检测任务中,模型融合是提高性能的一种重要手段。目前常用的模型融合策略包括投票、加权平均、特征融合等。在改进YOLOv4车辆识别的过程中,可以通过模型融合策略进一步提高模型的性能。
1 投票策略
投票策略是一种简单有效的模型融合方式,通过将多个模型的预测结果进行投票来得到最终的识别结果。在目标检测任务中,投票策略可以通过多个模型的检测框进行重叠和筛选,为的是提高模型的鲁棒性和准确性。
对于YOLOv4车辆识别任务,可以训练多个YOLOv4模型,分别在不同的训练集和参数设置下进行训练,然后对它们的预测结果进行投票。在进行投票时,可以使用简单投票或加权投票的方式来进行,以得到最终的识别结果。
投票策略的优点是简单有效,可以通过多个模型的互相补充和筛选来提高性能。缺点是无法考虑不同模型之间的差异性和复杂性,需要同时训练多个模型,增加了训练和部署的复杂度。
2 加权平均策略
加权平均策略是一种常见的模型融合方法,它将多个模型的预测结果进行权重平均,从而获得最终的识别结果。在目标检测任务中,加权平均策略可以通过不同模型的权重设置和特征融合来提高模型的鲁棒性和准确性。
对于YOLOv4车辆识别任务,可以训练多个YOLOv4模型,然后对它们的预测结果进行加权平均。在进行加权平均时,可以根据模型的性能和重要性进行不同的权重设置,以得到最终的识别结果。此外,还可以进行特征融合,将多个模型的特征图进行融合,从而进一步提高模型的性能。
加权平均策略的优点是灵活可控,可以根据不同模型的性能和重要性进行权重设置和特征融合,从而提高模型的性能。缺点是需要进行模型训练和参数调整,增加了训练和部署的复杂度。
3 特征融合策略
特征融合策略是一种常用的模型融合方式,通过将多个模型的特征图进行融合来得到最终的识别结果。在目标检测任务中,特征融合策略可以通过不同模型的特征提取和特征融合来提高模型的鲁棒性和准确性。
对于YOLOv4车辆识别任务,可以训练多个YOLOv4模型,在得到它们的预测结果之后,将它们的特征图进行融合。常用的特征融合方式包括特征加法、特征乘法、特征拼接等。通过特征融合,该方法能够充分地利用多种模型之间的特性,从而改善模型的特性。
特征融合策略的优势在于,它可以将多个模型的特征信息进行充分地利用,从而提升了模型的稳定性和精度。缺点是需要进行模型训练和参数调整,增加了训练和部署的复杂度。此外,不同模型之间的特征差异性和复杂性也会影响融合结果,需要进行适当的特征选择和融合方式调整。
4 其他模型融合策略
除了投票、加权平均和特征融合策略之外,还有其他一些常用的模型融合策略。在车辆识别领域,多任务学习、迁移学习和弱监督学习等方法也是未来研究的重要方向。多任务学习能够将不同的任务相结合,提高模型的鲁棒性和泛化能力;迁移学习则能够将已有的模型迁移到新的任务中,降低训练成本,提高泛化能力;弱监督学习则可以利用弱标注数据进行训练,降低标注成本,同时提高模型的训练效率和泛化能力。这些方法的应用有望进一步改善车辆识别技术,在实际应用中发挥更大的作用。
需要注意的是,模型融合策略并非适用于所有任务和场景,应该根据实际情况进行选择和调整。此外,在实现模型融合策略时,还需要考虑训练和部署的效率、可扩展性和复杂度等因素,并进行适当调整。通过综合考虑这些因素,可以实现性能更好、效率更高、更易部署的车辆识别算法。
综上所述,模型融合是提高YOLOv4车辆识别性能的重要手段之一,其常用的模型融合策略包括投票、加权平均和特征融合等。在实际应用中,还可以根据实际情况选择和调整其他模型融合策略。需要注意的是,在实现模型融合策略时,应综合考虑识别性能和计算效率等因素,以达到最优的识别性能和最小的复杂度。